
「アクセラレーテッド コンピューティングなくして、AI のスケールアウトはとうてい現実的ではない」―― Google が最近公開した TPU に関する論文では、明確にそう結論付けられています。
現在の経済は世界各国のデータ センターの内部で動いており、そしてデータ センターは劇的に変化しています。少し前までは、Web ページや、広告、ビデオ コンテンツを提供していたデータ センターが、今や音声を認識し、ビデオ ストリーム内の画像を検出し、まさに必要なタイミングで必要な情報にユーザーをつなげてくれるまでになっています。
そうした能力の可能性は、ディープラーニングと呼ばれる人工知能の一種によってますます広がっています。ディープラーニングとは、言語の翻訳、がんの診断、自律走行車に運転を学習させる、といった課題に対応できるソフトウェアを開発するために膨大なデータから学習するアルゴリズムです。私たちの業界では、AI によってもたらされるこうした変化が、かつてないペースで加速しています。
ディープラーニングの先駆的研究者であるジェフリー・ヒントン (Geoffrey Hinton) 氏は最近、The New Yorker 誌に対して次のように述べています。「大量のデータが存在する従来の分類のどの問題をとってみても、ディープラーニングによって解決されるでしょう。今後、ディープラーニングを採用した何千ものアプリケーションが登場するはずです。」
著しく効果的な成果
Google は、ディープラーニングにおけるその革新的研究の応用が世界の注目を集めてきました。たとえば、Google Now サービスの驚くべき精度、世界最強クラスの囲碁棋士に対する画期的勝利、100 種類の言語に対応する Google Translate の能力などです。
ディープラーニングは、著しく効果的な成果を上げてきました。しかし、ディープラーニングのアプローチでは、ムーアの法則が減速しつつあるまさにこの時代において、コンピューターによる大量のデータ処理が求められます。ディープラーニングという新しいコンピューティング モデルには、新たなコンピューティング アーキテクチャの考案が必要だったのです。
NVIDIA では、以前からこの AI コンピューティング モデルのアーキテクチャの変化に重点的に取り組んできました。2010 年には、ユルゲン・シュミットフーバー (Juergen Schmidhuber) 教授率いるスイスの AI 研究所の研究者であるダン・シレサン (Dan Ciresan) 氏が、NVIDIA の GPU を利用してディープ ニューラル ネットワークのトレーニングを行うことで、CPU の 50 倍もの高速化を実現できることを発見しました。その 1 年後、シュミットフーバー教授のラボは、GPU を初の純粋なディープ ニューラル ネットワークの開発に取り入れ、手書き認識とコンピューター ビジョンにおいて国際コンテストで優勝しました。
そして、2012 年には、当時トロント大学の大学院生であったアレックス クリジェフスキー (Alex Krizhevsky) 氏が、今では有名になった ImageNet の年次大規模画像認識大会で 2 つの GPU を使って優勝します (最新のコンピューター ビジョンにおける GPU ディープラーニングの影響については、シュミットフーバー教授によってその包括的な歴史が記録されています)。
ディープラーニングへの最適化
コンピューター グラフィックス アプリケーションやスーパーコンピューティング アプリケーション向けに NVIDIA が開発した GPU アクセラレーテッド コンピューティング モデルがディープラーニングに最適であることを、世界中の AI 研究者が理解するようになりました。3D グラフィックス、医療画像、分子動力学、量子化学、天気のシミュレーションなどのディープラーニングは、線形代数アルゴリズムであり、テンソル (多次元ベクトル) の超並列コンピューティングを必要とします。2009 年に設計された NVIDIA の Kepler 世代の GPU は、GPU アクセラレーテッド コンピューティングをディープラーニングに利用できる可能性を世界に知らしめるのに貢献しましたが、その作業のために特別に最適化されることはありませんでした。
そこで、NVIDIA は、新世代の GPU アーキテクチャの開発に取りかかりました。まずは Maxwell、次に Pascal です。その過程では、ディープラーニングに特化したアーキテクチャの強化が数多く図られました。Kepler ベースの Tesla K80 からわずか 4 年後に発表された NVIDIA の Pascal ベースの Tesla P40 推論アクセラレーターでは、ムーアの法則をはるかに上回る 26 倍のディープラーニング推論パフォーマンスが実現しています。
この間、Google では、特に推論を処理するためのテンソル プロセッシング ユニット (TPU) と呼ばれるカスタムのアクセラレーター チップの設計が進められ、2015 年に展開されました。
先週、同チームは、TPU の利点について技術情報を発表しました。その中でも特に、TPU は K80 の 13 倍の推論パフォーマンスを備えていると主張していますが、TPU と現世代の Pascal ベースの P40 との比較は行われていません。
Google の比較結果に関する最新情報
下図では、Google の比較結果に関する最新情報として、K80 から P40 へのパフォーマンスの飛躍的向上を数値化するとともに、TPU と現在の NVIDIA のテクノロジとの比較を示しています。
P40 では、推論だけでなくトレーニングでも前例のないパフォーマンスを達成するため、コンピューティングの精度とスループット、オンチップ メモリとメモリ帯域幅とのバランスがとられています。P40 は、トレーニングでは 10 倍の帯域幅と 12 TFLOPs の 32 ビット浮動小数点パフォーマンスを備え、推論では 8 ビット (INT 8) の高速スループットと高メモリ帯域幅を備えています。
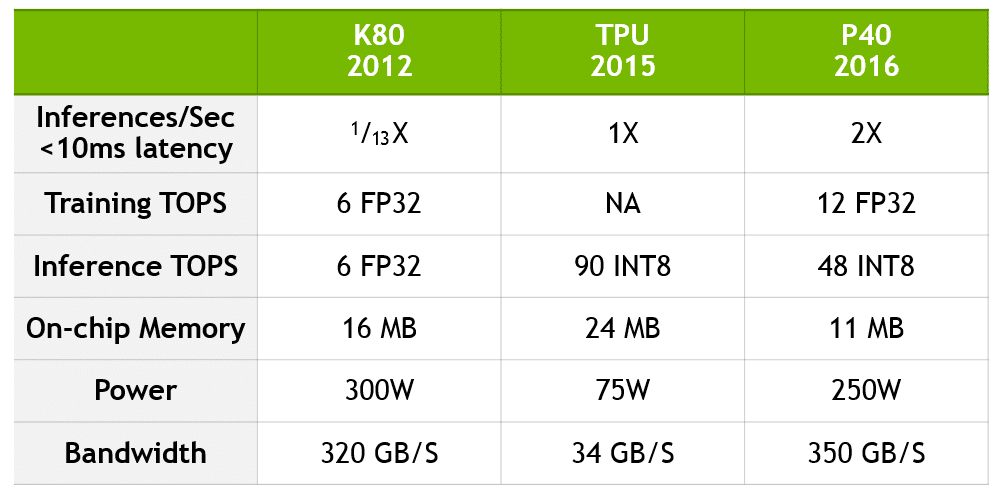
データは、Jouppi et al [Jou17] の「In-Datacenter Performance Analysis of a Tensor Processing Unit (テンソル プロセッシング ユニットのデータセンター内パフォーマンス分析)」と、NVIDIA の内部ベンチマーキングに基づいています。K80 と TPU のパフォーマンス比率は、[Jou17] の CNN0 と CNN1 のアクセラレーション比率に基づいています (半有効化された K80 に対してパフォーマンスを比較)。K80 と P40 のパフォーマンス比率は、同様のパフォーマンス特性を持つ公開中の CNN モデルである GoogLeNet に基づいています。
Google と NVIDIA は異なる開発プロセスを選択しましたが、両社のアプローチには共通のテーマもいくつかありました。具体的には次のようなものです。
- AI にはアクセラレーテッド コンピューティングが必要であり、アクセラレーターは、ムーアの法則が減速しつつある時代において、増大しているディープラーニングの需要に追いつくのに必要な、大量のデータ処理能力をもたらす
- Tensor 処理はディープラーニングのトレーニングと推論に適したパフォーマンスの実現における中核となる
- Tensor 処理は、企業が最新のデータ センターを構築する際に検討する必要のある重要な新しいワークロードである
- Tensor 処理を高速化することで、最新のデータ センターの構築コストを大幅に削減できる
テクノロジの世界は、すでに「AI 革命」と呼ばれる歴史的変革の只中にあります。現在その影響が最も明らかな場所は、Alibaba、Amazon、Baidu、Facebook、Google、IBM、Microsoft、Tencent などのハイパースケール データセンターです。これらの企業は、CPU ノードによって新たなデータセンターを構築して稼働させるために何十億ドルもかけることなく、AI ワークロードを加速する必要があるためです。アクセラレーテッド コンピューティングなくして、AI のスケールアウトはとうてい現実的ではありません。
GPU アクセラレーテッド コンピューティングは、ディープラーニングを可能にし、最新の AI の火付け役となりました。ぜひ、5 月 8 ~ 11 日にかけてカリフォルニア州サンノゼで開催される当社の GPU テクノロジ カンファレンスにお越しください。AI の先駆者たちが紹介する革新的発見を知り、GPU コンピューティングにおける最近の進歩と、それらがさまざまな業界で次々と革命を起こしている経緯を学んでいただけます。