
先日、ヤン・ルカン(Yann LeCun)氏に招かれ、ニューヨーク大学で“The Future of AI”の立ち上げシンポジウムで講演をしてきました。この分野をリードする人々が大勢集まり、AIの現状とその進歩について語りあうすばらしい会でした。今日は、そこでお話ししたことをご紹介しましょう。ディープラーニングとは新しいコンピューティング・モデルが必要な新しいソフトウェア・モデルであること、GPUアクセラレーテッド・コンピューティングがAI研究者に普及しているのはなぜか、AIは爆発的に普及しつつありますがNVIDIAはその普及を継続的に推進していること、そして、登場から長い年月が経過した今、AIの普及が始まったのはなぜか、をお話させていただきました。

ビッグバン
コンピュータというものが登場して以来、ずっと、AIは、最後のフロンティアだと考えられてきました。この50年間、人間と同じように世界を認識したり言語を理解したり、事例から学んだりできるインテリジェントなマシンを構築することがコンピュータ科学者のライフワークだったのです。ヤン・ルカン氏の畳み込みニューラルネットワーク、ジェフ・ヒントン(Geoff Hinton)氏のバック・プロパゲーションと確率的勾配降下法によるトレーニング、アンドリュー・ン(Andrew Ng)氏による大規模なGPUを活用してたディープ・ニューラル・ネットワークの高速化が組み合わさるまで、最新型AI――すなわちディープラーニング――のビッグバンは起きませんでした。
当時、NVIDIAは、超並列のグラフィックス・プロセッサにより、やはり並列的特性を持つアプリケーションを高速化する新しいコンピューティング・モデル、GPUアクセラレーテッド・コンピューティングの推進に全力を注いでいました。そして、分子レベルのシミュレーションによって命を救う医薬品の効果を測ったり、人間の臓器を3Dで可視化したり(CTスキャンの映像から立体を再構築)、銀河レベルのシミュレーションによって宇宙の原理を解明したりといったことがGPUによって行われるようになりました。量子色力学のシミュレーションにNVIDIAのGPUを採用した研究者から、このように言われたことがあります――「NVIDIAのおかげで、生きているうちに実現することが可能になりました」と。これほどうれしい言葉はありません。NVIDIAは、よりよい未来を実現するための力を世の中に提供することをミッションとしてきました。NVIDIA GPUの登場でスーパーコンピューティングが民生化され、その力を研究者の方々が入手できるようになったわけです。
2011年になると、AI研究者もNVIDIA GPUに注目しました。ちょうど、YouTubeの映画を観ることでネコと人を区別できるようになるという驚異的な成果をGoogle Brainが挙げたころです。でも、そのためには、Googleの巨大なデータセンタにずらりと並んだサーバを使い、2,000個ものCPUで処理する必要がありました。これほど大量のコンピュータを使えるところはほとんどありません。そこに登場したのがNVIDIAとGPUでした。NVIDIAリサーチのブライアン・カタンザーロ(Bryan Catanzaro)がスタンフォード大学のアンドリュー・ン氏のチームと協力し、ディープラーニングにGPUを適用してみました。その結果、ディープラーニングにおいては、12個のNVIDIA GPUが2,000個のCPUに匹敵するパフォーマンスを挙げられるとわかったのです。そして、ニューヨーク大学、トロント大学、スイスAIラボで、GPUによるディープ・ニューラル・ネットワークの高速化が始まり、これが爆発的な普及につながっていきます。
奇跡を起こすディープラーニング
そして、コンピュータによる画像認識精度を競うImageNetの2012年大会で、トロント大学のアレックス・クリジェフスキー(Alex Krizhevsky)氏が優勝します (1)。コンピュータビジョンの専門家が作り込んだソフトウェアに大差をつけて勝ったのです。対して、クリジェフスキー氏らはコンピュータビジョンのコードを書いてもいません。ディープラーニングにより、コンピュータ自身が画像の認識方法を学んだのです。クリジェフスキー氏らはAlexNetというニューラル・ネットワークを構築し、何百万枚もの画像を使ってトレーニングしました。これは兆単位の回数、演算が必要な処理になりますが、それをNVIDIA GPUで処理したのです。その結果、クリジェフスキー氏のAlexNetが、人間が作り込んだ最高のソフトウェアを超える成績をたたき出したわけです。
そして、AIレースが始まりました。次の節目は、2015年に訪れました。
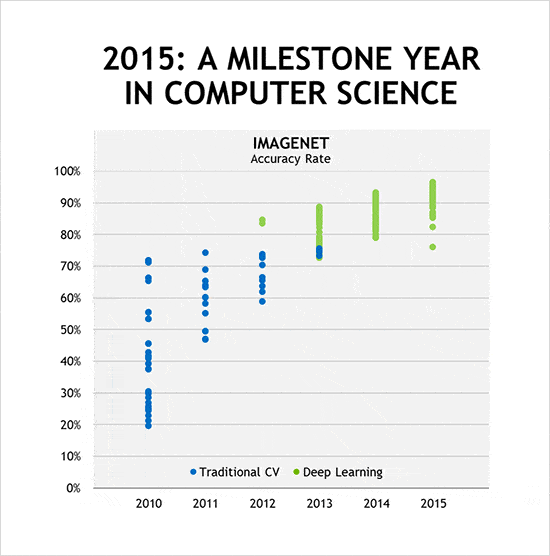
ディープラーニングにより、GoogleとMicrosoftが、ImageNetで人間以上の成績を上げたのです (2,3)。人間が書いたプログラム以上の、ではなく、人間以上の、です。その少しあとには、Microsoftと中国科学技術大学が、IQ試験で大学院生並みのスコアをディープ・ニューラル・ネットワークで得ることに成功したと発表します (4)。さらに、Baiduから、Deep Speech 2というディープラーニング・システムがひとつのアルゴリズムによって英語と標準中国語を学ぶことに成功したとの報告が続きます (5)。ImageNetの2015年大会では、GPUアクセラレーテッドのディープ・ニューラル・ネットワークによるディープラーニングが上位を占め、その多くが人間以上の精度をたたき出しました。
ディープラーニングは2012年に人間が書いたソフトウェアを打ち負かし、2015年には「超人的な」認識能力を実現したわけです。
新しいソフトウェア・モデルのための新しいコンピューティング・プラットフォーム
コンピュータのプログラムというのは、基本的に順を追って実行されていくコマンドが並んだ形になっています。対して、ディープラーニングというのは根本的に異なる新しいソフトウェア・モデルで、何十億ものソフトウェア・ニューロンと何兆もの結合を、並列にトレーニングしていきます。ディープ・ニューラル・ネットワークのアルゴリズムを実行し、実例から学んでいくというのは、コンピュータがみずからソフトウェアを書いているに等しいことです。
これほどソフトウェア・モデルが異なるのですから、それを効率的に走らせられる新たなコンピュータ・プラットフォームが必要になります。このとき、理想的なアプローチはアクセラレーテッド・コンピューティングとなりますし、理想的なプロセッサはGPUとなります。近年、ディープラーニングが急速に進歩しているのは「プログラミングが容易で、ネットワークのトレーニング速度を10倍から20倍に引き上げられる高速グラフィックス・プロセッシング・ユニット(GPU)が登場したから」 (6)だと、ネイチャー誌でも指摘されています。新しいコンピューティング・プラットフォームの誕生には、パフォーマンス、プログラミングの生産性、オープンなアクセス性が同時に成立する必要があります。
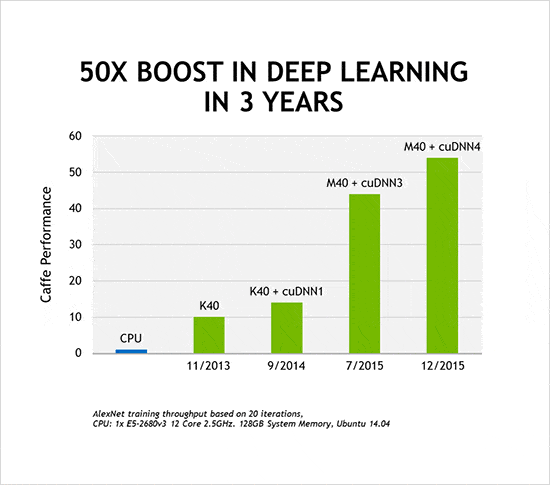
パフォーマンス。NVIDIA GPUは本質的に並列処理向きで、ディープ・ニューラル・ネットワークの実行を10倍から20倍までスピードアップすることができます。普通なら数週間はかかるトレーニング・セッションを数日に短縮できることが多いのです。しかも、NVIDIAはそこで足を止めたりしませんでした。AI分野の開発者と協力し、GPUの設計やシステム・アーキテクチャ、コンパイラ、アルゴリズムの改良を続け、ディープ・ニューラル・ネットワークのトレーニング速度をわずか3年で50倍まで引き上げることに成功しました。これは、ムーアの法則を大きく上回るペースです。また、今後数年で、さらに10倍程度の高速化ができるとNVIDIAでは考えています。
プログラミング性。AI分野では、猛スピードでイノベーションが続いています。そこで重要になるのは、プログラミングのしやすさと開発者の生産性です。NVIDIAのCUDAプラットフォームはプログラミング性に優れているとともに必要なものが豊富にそろっており、イノベーションをすばやく実現することができます。新しい構成のCNNやDNN、ディープ・インセプション・ネットワーク、RNN、LSTM、強化学習ネットワークなどをさっと作れるのです。

アクセス性。開発者というのは、どこにいても開発をしたいものですし、完成したソフトウェアは好きな場所に展開したいと思うものです。NVIDIA GPUなら世界中いたるところで動いています。OEMのPCにも搭載されています。デスクトップにもノートパソコンにも、さらにはサーバやスーパーコンピュータにも搭載されています。Amazon、IBM、Microsoftのクラウドにも採用されています。主要なAI開発フレームワークは、インターネット企業から研究機関、スタートアップ企業にいたるまで、すべて、NVIDIA GPUアクセラレーションとなっています。好みのAI開発システムは人によって異なるかもしれませんが、GPUアクセラレーションを採用すれば、いずれも、高速化することができます。また、さまざまなGPUを製造しており、どのような大きさのシステムにも対応できます。つまり、どのような種類のインテリジェント・マシンであってもディープ・ニューラル・ネットワークの活用が可能なのです。PCにはGeForce、クラウドやスーパーコンピュータにはTesla、ロボットやドローンにはJetson、そして、自動車にはDRIVE PXがあります。アーキテクチャは同一で、どの製品でもディープラーニングを高速化することができます。
あらゆる業界でインテリジェンスの活用が進行中
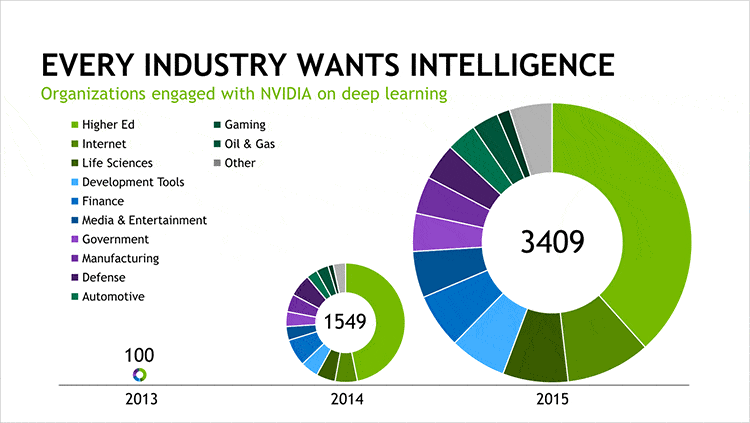
他社に先駆けてディープラーニングにNVIDIA GPUを採用したのは、Baidu、Google、Facebook、Microsoftなどです。話し言葉に対応する、話されたり書かれたりした言葉を別言語に翻訳する、画像を認識し自動的にタグを付与する、ニュースフィードやエンターテイメント、製品などをユーザ一人ひとりの好みに合わせてお勧めするなどを、このAIテクノロジでやろうとしているわけです。そして、AIによって新しい製品やサービスを生みだしたり、業務を改善したりしようと、スタートアップ企業や老舗企業がしのぎを削るようにもなりました。ディープラーニングについてNVIDIAが協力している企業の数は、ここ2年で35倍と爆発的に増え、3,400社以上となりました。ヘルスケアやライフサイエンス、エネルギー、金融サービス、自動車、製造、エンターテイメントなど、さまざまな産業が、山のようなデータを元にした推測を活用しようとしています。そして、FacebookもGoogleもMicrosoftも、それぞれが開発したディープラーニング・プラットフォームの公開に踏みきったことから、今後は、AIを活用したアプリケーションが急増するものと思われます。このような流れをうけ、つい先日、Wired誌は、「GPU興隆」の時代が到来したと宣言しました。
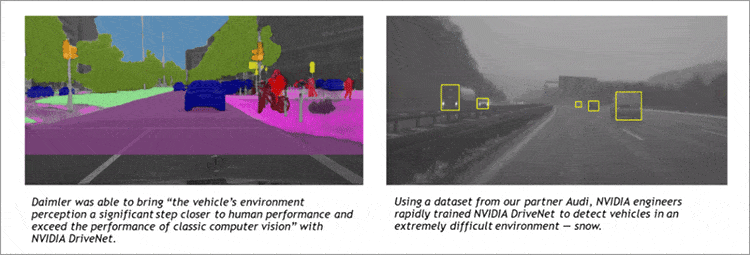
自律走行の自動車。自律走行の自動車は、超人的な副操縦士として運転者を助ける、人々の移動を革新する、都市部で無秩序に増えている駐車場の必要性を引き下げるなど、驚くべきプラスを社会にもたらす可能性を秘めています。運転というのは複雑なものです。予想しないことが起きます。雨氷で道路がスケート場のようになることもあります。通るつもりだった道が閉鎖されていることもあります。車の前に子どもが飛びだしてくることもあります。自律走行の自動車が遭遇する可能性のあるシナリオ、すべてを網羅したソフトウェアなど、書けるはずがありません。だから、ディープラーニングなのです。ディープラーニングなら、学び、適応し、改善していくことができます。NVIDIAでは、トレーニングのシステムから車載AIコンピュータまで、すべてがそろうエンドツーエンドのディープラーニング・プラットフォーム、NVIDIA DRIVE PXを自律走行の自動車用に開発しました。その結果、すばらしい成果が上がりつつあります。超人的なコンピュータを副操縦士にしたり、運転手のいらないシャトルバスが走る未来も、SFではなくなったのです。
ロボット。産業用ロボットの大手メーカ、FANUCが、先日、容器に入った向きがばらばらの部品を「つまむ」ことを学んだ組立ライン用ロボットのデモを行いました。ロボットにGPUを搭載し、試行錯誤で学ばせたのです。このディープラーニング・テクノロジはPreferred Networks社が開発したもので、「人工知能で技術再生に挑む日本」とウォール・ストリート・ジャーナル紙が報じました。
ヘルスケアおよびライフサイエンス。GPUベースのディープラーニングにより、どのような遺伝子が疾病につながるのかを理解しようとしているGenomicsという企業があります。また、GPUを活用したディープラーニングで医療用画像の解析をスピードアップしようとしているArterysという企業もあります。後者のテクノロジは、GE Healthcare社のMRIに採用され、心臓病の診断に役立てられることになっています。Enliticという企業も、ディープラーニングによって医療用画像を解析し、腫瘍や目に見えないほどの骨折などの発見に役立てたいとしています。
今回、ご紹介できたのは実例のごく一部にすぎません。実例は、文字どおり何千とあるのです。
GPUでAIを高速化:新たなコンピューティング・モデル
ディープラーニングというブレークスルーにより、AI革命が始まりました。AIディープ・ニューラル・ネットワーク搭載のマシンなら、複雑すぎて人間のプログラマでは対処できない問題も解くことができます。データから学び、使うたびに成長することができるからです。同じディープ・ニューラル・ネットワークを、それこそプログラマでない人がトレーニングし、別の問題を解かせることさえ可能です。指数関数的な普及が見込まれます。そして、社会に対する影響も、きっと指数関数的になるはずだとNVIDIAでは考えています。KPMGが最近行った研究では、コンピュータによるドライバ・アシスタンス・テクノロジにより、自動車事故は、今後20年間で80%も減少すると予想されています。年間100万人近い人が死なずにすむようになるということです。これを支える要がディープラーニング型AIというわけです。
コンピュータ業界に与える影響も、指数関数的となるでしょう。ディープラーニングというのは、従来と根本的に異なるソフトウェア・モデルです。だから、それを走らせるために新しいコンピュータ・プラットフォームが必要になります。プログラマが作成したコマンドはもちろん、ディープ・ニューラル・ネットワークの超並列トレーニングも効率的に実行できるアーキテクチャが必要になります。ここは、GPUアクセラレーテッド・コンピューティングの独壇場になるはずだとNVIDIAでは考えています。ポピュラーサイエンス誌も同意見らしく、先日、GPUを「現代AIの大黒柱」と表現していました。そのとおりだと思います。
- A. Krizhevsky, I. Sutskever, G. Hinton. ImageNet classification with deep convolutional neural networks(ディープ畳み込みニューラル・ネットワークによるImageNet画像の分類). 第25回Neural Information Processing Systems予稿集, 1090-1098 (2012)
- K. He, X. Zhang, S. Ren, J. Sun. Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification(rectifierの深部に潜る:ImageNet分類のパフォーマンスで人のレベルを超える). arXiv:1502.01852 [cs] (2015)
- S. Ioffe, C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift(バッチ型正規化:内部共変量シフト削減によるディープ・ネットワーク・トレーニングの加速). ICML (International Conference on Machine Learning), 448-456 (2015)
- H. Wang, B. Gao, J. Bian, F. Tian, T.Y. Liu. Solving Verbal Comprehension Questions in IQ Test by Knowledge-Powered Word Embedding(ナレッジ活用の単語埋込みで知能テストの言語性知能問題を解く). arXiv:1505.07909 [cs.CL] (2015).
- D. Amodei, R. Anubhai, E. Battenberg, C. Case, J. Casper, B. Catanzaro, J. Chen, M. Chrzanowski, A. Coates, G. Diamos, E. Elsen, J. Engel, L. Fan, C. Fougner, T. Han, A. Hannun, B. Jun, P. LeGresley, L. Lin, S. Narang, A. Ng, S. Ozair, R. Prenger, J. Raiman, S. Satheesh, D. Seetapun, S. Sengupta, Y. Wang, Z. Wang, C. Wang, B. Xiao, D. Yogatama, J. Zhan, Z. Zhu.“Deep speech 2: End-to-end speech recognition in English and Mandarin(Deep Speech 2:英語および標準中国語におけるエンドツーエンドの音声認識),”arXiv前刷り arXiv:1512.02595 (2015).
- Y. LeCun, Y. Bengio, G. Hinton. Deep Learning – Review(ディープラーニング-レビュー). Nature (2015).