
リーズニング AI の時代において、よりスマートで高性能なモデルをトレーニングすることは、インテリジェンスを拡大していく上で極めて重要です。この新たな時代に対応できる圧倒的なパフォーマンスを実現するには、GPU、CPU、NIC、スケールアップおよびスケールアウトのネットワーク、システム アーキテクチャ、そして膨大な量のソフトウェアとアルゴリズムにおけるブレークスルーが不可欠です。
AI トレーニング性能の業界標準テストであり、長年にわたって実施されている一連のテストの最新版である MLPerf Training v5.1 において、NVIDIA は 7 つのテストすべてで勝利を収め、大規模言語モデル (LLM)、画像生成、レコメンダー システム、コンピュータビジョン、グラフ ニューラル ネットワークなど、あらゆる分野で最速のトレーニング時間を達成しました。
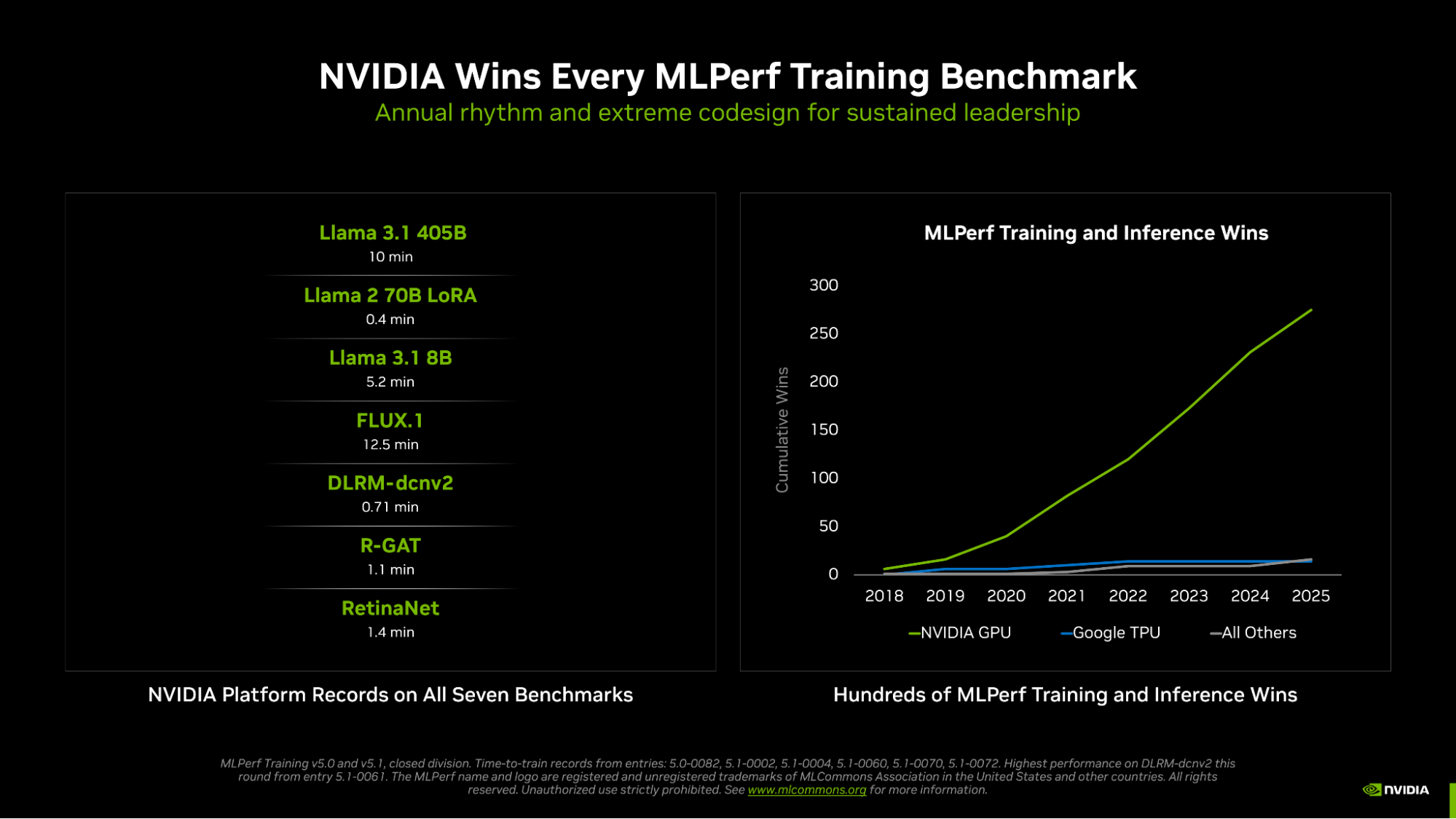
NVIDIA は、すべてのテストで結果を提出した唯一のプラットフォームであり、NVIDIA GPU の高いプログラマビリティと、CUDA ソフトウェア スタックの成熟度および汎用性の高さを改めて証明しました。
NVIDIA Blackwell Ultra がさらに進化
NVIDIA Blackwell Ultra GPU アーキテクチャを搭載した GB300 NVL72 ラックスケール システムは、前回の MLPerf Inference ラウンドで記録的な性能を達成したのに続き、今回の MLPerf Training ラウンドに初登場しました。
前世代の Hopper アーキテクチャと比較して、Blackwell Ultra ベースの GB300 NVL72 は、同数の GPU で Llama 3.1 405B の事前トレーニング性能を 4 倍以上、Llama 2 70B LoRA のファインチューニング性能を 5 倍近く向上させました。

これらの性能向上は、15 ペタフロップスの NVFP4 AI 演算性能を提供する新しい Tensor コア、2 倍のアテンション レイヤー演算性能、279GB の HBM3e メモリなどのBlackwell Ultra のアーキテクチャの改良に加え、このアーキテクチャの膨大な NVFP4 演算性能を活用した新しいトレーニング手法によって実現されました。
複数の GB300 NVL72 システムを接続する、業界初のエンドツーエンド 800Gb/s ネットワーキング プラットフォームである NVIDIA Quantum-X800 InfiniBand プラットフォームも MLPerf に初登場し、前世代と比較してスケールアウト ネットワーク帯域幅が 2 倍になりました。
性能の飛躍的向上:NVFP4 が LLM トレーニングを加速
今回の優れた結果の鍵となったのは、MLPerf Training 史上初となる NVFP4 精度での計算の実行です。
計算性能を向上させる方法の一つは、より少ないビット数で表現されたデータに対して計算を実行できるアーキテクチャを構築し、その計算を高速化することです。しかし、精度が低いということは、各計算で利用できる情報量が少なくなることを意味します。そのため、トレーニング プロセスで低精度計算を用いる場合は、結果の精度を維持するために慎重な設計判断が必要となります。
NVIDIA チームは、LLM トレーニングに FP4 精度を導入するために、スタックのあらゆるレイヤーで革新的な取り組みを行いました。NVIDIA Blackwell GPU は、NVIDIA が設計した NVFP4 フォーマットを含む様々な FP4 形式での計算を、FP8 の 2 倍の速度で実行できます。Blackwell Ultra では、これを 3 倍に引き上げ、GPU が大幅に向上した AI 計算性能を発揮できるようにしています。
NVIDIA は現在まで、ベンチマークの厳格な精度要件を満たしながら、FP4 精度で計算を実行した MLPerf Training の結果を提出した唯一のプラットフォームです。
NVIDIA Blackwell が新たな高みへ到達
NVIDIA は、5,000基以上の Blackwell GPU を効率的に連携させることで、Llama 3.1 405B のトレーニング時間をわずか 10 分に短縮し、新たな記録を樹立しました。この記録は、前回のラウンドで提出された Blackwell ベースの最高記録よりも 2.7 倍高速です。これは、GPU 数を 2 倍以上に増やして効率的なスケーリングを実現したことに加え、NVFP4 精度を使用することで各 Blackwell GPU の実効性能を大幅に向上させた結果です。
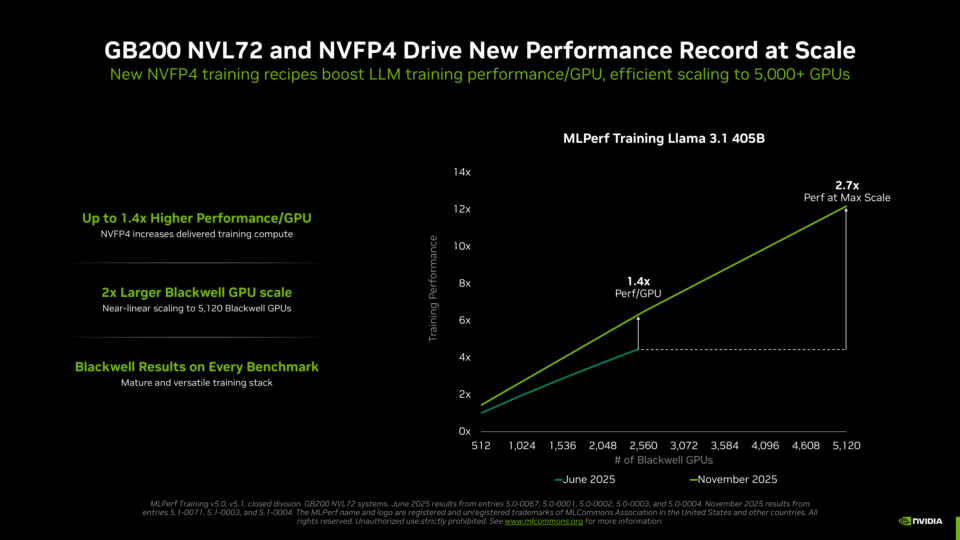
GPU あたりのパフォーマンス向上を示すため、NVIDIA は今回、2,560 基の Blackwell GPU を使用した結果を提出し、トレーニング時間を 18.79 分に短縮しました。これは、前回 2,496 基の GPU を使用した結果よりも 45% 高速です。
新しいベンチマーク、新しい記録
NVIDIA は、今回追加された 2 つの新しいベンチマーク、Llama 3.1 8B と FLUX.1 でもパフォーマンス記録を樹立しました。
Llama 3.1 8B は、コンパクトでありながら高性能な LLM で、長らく使用されてきた BERT-large モデルに代わり、ベンチマーク スイートに最新の小型の LLM が加わりました。NVIDIA は最大 512 基の Blackwell Ultra GPU を使用して結果を提出し、トレーニング時間が 5.2 分となる、新たな基準を打ち立てました。
さらに、最先端の画像生成モデルである FLUX.1 は Stable Diffusion v2 に代わって採用され、このベンチマークには NVIDIA プラットフォームのみが結果を提出しました。NVIDIA は 1,152 基のBlackwell GPU を 使用して結果を提出し、トレーニング時間 12.5 分という記録を達成しました。
NVIDIA は、既存のグラフ ニューラル ネットワーク、物体検出、レコメンダー システムに関するテストでも引き続き記録を保持しました。
広範かつ強固なパートナー エコシステム
今回のラウンドでは、NVIDIA のエコシステムが幅広く参加し、ASUSTeK、Dell Technologies、Giga Computing、Hewlett Packard Enterprise、Krai、Lambda、Lenovo、Nebius、Quanta Cloud Technology、Supermicro、フロリダ大学、Verda (旧DataCrunch)、Wiwynn を含む 15 の組織から優れた提出がありました。
NVIDIA は 1 年周期でイノベーションを推進し、事前学習、事後学習、推論の各段階で大幅かつ迅速なパフォーマンス向上を実現することで、新たなレベルのインテリジェンスへの道を開き、AI の導入を加速させています。
NVIDIA のパフォーマンス データの詳細は、Data Center Deep Learning Product Performance Hub および Performance Explorer のページをご覧ください。