 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
基盤モデルとは、大量のラベルなしデータセットで学習させた AI ニューラルネットワークで、テキストの翻訳から医用画像の解析まで、さまざまな領域に対応します。
1956 年、Miles Davis Quintet 氏が Prestige Records に数十曲を録音していたスタジオでは、生演奏でテープが回っていました。
エンジニアが次の曲のタイトルを尋ねると、Davis 氏は「演奏して、後で教えてあげる」と告げました。
ジャズ トランペッターや作曲家のように、研究者は AI モデルを猛烈なスピードで生成し、新しいアーキテクチャやユースケースを探求しています。新しい分野を開拓することに集中するあまり、自分たちの仕事を分類することを他人に任せてしまうこともあります。
スタンフォード大学の 100 人以上の研究者が協力して、2021 年夏に発表された 214 ページの論文で、まさにそれを実践しています。
Transformer モデル、大規模言語モデル (LLM)、その他の現在構築中のニューラル ネットワークは、基盤モデルと呼ばれる重要な新しいカテゴリに含まれると言われています。
基盤モデルの定義
基盤モデルとは、一般的に教師なし学習で大量の生データでトレーニングされた AI ニューラルネットワークのことで、幅広いタスクを達成するために適応させることができると、論文で述べられています。
「ここ数年の基盤モデルの規模と範囲の広さは、何が可能かということについての私たちの想像力を広げてくれました」と研究者らは綴っています。
この包括的なカテゴリを定義するのに役立つ 2 つの重要なコンセプトがあります。データ収集が容易であること、可能性が地平線のように広がっていることです。
ラベルはなく、チャンスはたくさんある
基盤モデルは一般的にラベルのないデータセットから学習するため、膨大なコレクションの各項目を手作業で説明する時間と費用を節約することができます。
これまでのニューラルネットワークは、特定のタスクに絞り込んで調整していました。基盤モデルは、ファインチューニングすることで、テキストの翻訳から医用画像の分析まで対応できるようになります。
基盤モデルは「印象的な挙動」を示し、大規模に展開されつつあると、基盤モデルを研究するために設立された研究センターのウェブサイトで述べられています。これまでに、センターの研究者だけで 50 本以上の基盤モデルに関する論文が投稿されています。
センター長の Percy Liang 氏は、基盤モデルに関する第 1 回ワークショップの冒頭にて、次のように述べています。「私たちが解明したのは、将来の基盤モデルはもとより、既存の基盤モデルの能力のごく一部だと考えています」
AI の創発と均質化
同講演で Percy Liang 氏は、基盤モデルを説明するために 2 つの用語を作りました。
「エマージェンス (Emergence)」とは、まだ発見されていない AI の機能を指す言葉であり、基盤モデルに含まれる多くの新たなスキルのようなものです。彼は、AI アルゴリズムとモデル アーキテクチャの混合を「均質化」と呼び、基盤モデルの形成に貢献しました (下図参照)。
この分野は速く動き続けています。
このグループが基盤モデルを定義した 1 年後、他の技術研究者たちは関連用語として「生成 AI」を作り出しました。これは、Transformer、大規模言語モデル、拡散モデル、その他のニューラルネットワークの総称で、テキスト、画像、音楽、ソフトウェアなどを作成できることから、人々の想像力をかき立てています。
最近の AI Podcast で意見を交わしたベンチャー キャピタルである Sequoia Capital の幹部は、「生成 AI は、数兆ドルの経済価値をもたらす可能性がある」と述べています。
基盤モデルの歴史
起業家で、Transformer に関する 2017 年の代表的な論文の研究を指揮した Google Brain の元シニア スタッフ研究科学者、Ashish Vaswani 氏は次のように述べています。「ニューラルネットワークのようなシンプルな手法が、爆発的に新しい能力を与えてくれる時代になっています」
その研究は、BERT やその他の大規模言語モデルを作成した研究者にインスピレーションを与え、2018 年は自然言語処理の「分岐点となる瞬間」だったと、同年末の AI に関するレポートで述べられています。
Google は BERT をオープンソース ソフトウェアとして公開し、後続の大規模言語モデルを生み出し、より大きく、より強力な大規模言語モデルを構築する競争を開始しました。そして、この技術を検索エンジンに応用し、ユーザーが簡単な文章で質問できるようにしました。
2020 年、OpenAI の研究者たちは、もうひとつの画期的な Transformer、GPT-3 を発表しました。数週間のうちに、人々はそれを使って詩、プログラム、歌、ウェブサイトなどを作成しました。
「言語モデルは、社会にとって有益な幅広い用途があります」と研究者たちは書いています。
また、これらのモデルがいかに大規模で計算量の多いものであるかも明らかになりました。GPT-3 は、約 1 兆語のデータセットで学習され、ニューラルネットワークのパワーと複雑さを示す重要な指標であるパラメータは、なんと 1750 億個もあります。
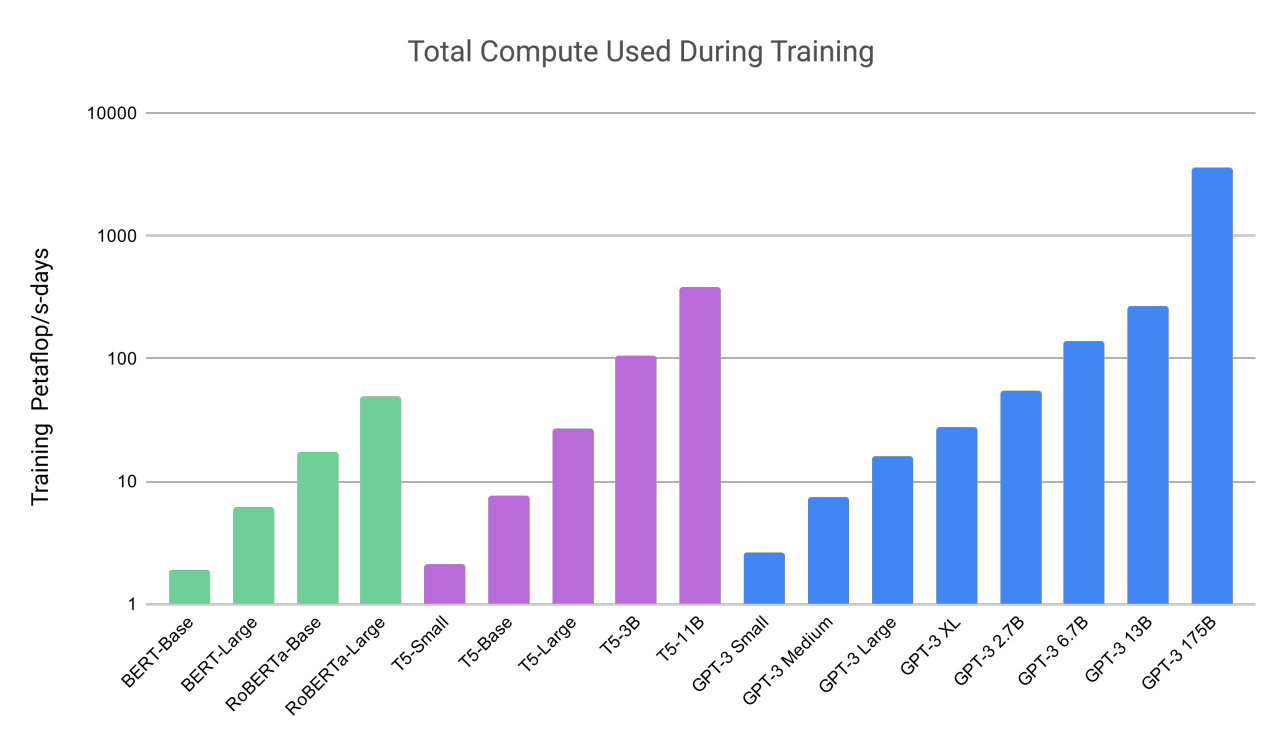 基盤モデルに対する計算需要の増大。(出典:GPT-3 論文)
基盤モデルに対する計算需要の増大。(出典:GPT-3 論文)GPT-3 についてPodcastで語った Liang 氏は、「GPT-3 でできることに圧倒されたのを覚えています」と語りました。
1 万基の NVIDIA GPU で学習させた最新の ChatGPT はさらに魅力的で、わずか 2 ヶ月で 1 億人以上のユーザーを獲得しました。そのリリースは、多くの人に AI の使い方を知ってもらうきっかけとなったため、AI にとっての iPhone の瞬間と呼ばれるようになりました。
 本年表では、初期の AI 研究から ChatGPT までの道のりが記されている (出典 : blog.bytebytego.com)
本年表では、初期の AI 研究から ChatGPT までの道のりが記されている (出典 : blog.bytebytego.com)テキストから画像へ
ChatGPT の登場とほぼ同時期に、「拡散モデル」と呼ばれる別のニューラルネットワークが話題になりました。テキストの説明を芸術的な画像に変換するその能力は、一般ユーザーを魅了し、ソーシャル メディア上で話題になるような驚くべき画像を作成しました。
拡散モデルを説明した最初の論文は、2015 年に登場し、ほとんど騒がれることはありませんでした。しかし、Transformer のように、新しい技術にはすぐに火が着きました。
オックスフォード大学の AI 研究者である James Thornton 氏が管理するリストによると、研究者は昨年、拡散モデルに関する 200 以上の論文を投稿しています。
Midjourney の CEO である David Holz 氏は、ツイートで、同社の拡散モデル ベースのテキストから画像への変換サービスが 440 万人を超えるユーザーを抱えていることを明らかにしました。ユーザーにサービスを提供するには、主に AI の推論に 1 万基以上の NVIDIA GPU が必要であると、彼はインタビューで答えています。
数十種類のモデルを使用
今では数百種類の基盤モデルが登場しています。ある論文では、主要な Transformer モデルだけで 50 種類以上がカタログ化され、分類されています (下表参照)。
スタンフォード大学のグループは、30 種類の基盤モデルのベンチマークを実施しましたが、この分野の進展が非常に速いため、いくつかの新しい著名なモデルについてはレビューしなかったとのことです。
最先端のスタートアップ企業を育成する NVIDIA Inception プログラムのメンバーである NLP Cloud は、航空会社、薬局、その他のユーザーに提供する商用サービスで、約 25 の大規模言語モデルを使用していると述べています。専門家は、Hugging Face のモデル ハブのようなサイトでオープンソース化されるモデルの割合が増えるだろうと予想しています。
 専門家の間では、基盤モデルをオープンソースとして公開する傾向が強まっていると言われています。
専門家の間では、基盤モデルをオープンソースとして公開する傾向が強まっていると言われています。基盤モデルは、より大きく、より複雑になっています。
そのため、多くの企業が、ゼロから新しいモデルを構築するのではなく、事前に学習させた基盤モデルをカスタマイズして、AI への取り組みを加速させています。
クラウドにおける基盤
あるベンチャー キャピタルは、広告生成からセマンティック検索まで、生成 AI の 33 のユースケースを挙げています。
主要なクラウド サービスでは、以前から基盤モデルの利用が進んでいます。例えば、Microsoft Azure は NVIDIA と協力して、Translator サービスに Transformer を実装しました。これは、マグニチュード 7.0 の地震に対応中の災害作業員がハイチ クレオール語を理解するのに役立ちました。
2 月に、Microsoft は ChatGPT と関連するイノベーションでブラウザと検索エンジンを強化する計画を発表しました。「私たちはこれらのツールをウェブの AI 副操縦士 (Copilot) と考えています」と発表しています。
Google は、実験的な対話型 AI サービスである Bard を発表しました。LaMDA、PaLM、Imagen、MusicLM といった同社の基盤モデルの力を、多くの製品に導入していく計画です。
「AI は、私たちが今取り組んでいる最も奥深い技術です」と、同社のブログには書かれています。
スタートアップ企業も牽引役
スタートアップ企業の Jasper は、VMware のような企業向けのコピーライティングための製品で、年間 7,500 万ドルの売上を見込んでいます。NVIDIA Inception メンバーである Writer を含む、テキストを生成する 10 社以上の企業がこの分野をリードしています。
この分野のその他の Inception のメンバーには、東京を拠点に活躍する rinna があり、日本で数百万人が利用するチャットボットを作成しています。テルアビブでは、Tabnine が世界中の 100 万人の開発者が書くコードの最大 30% を自動化する生成 AI サービスを運営しています。
ヘルスケアのためのプラットフォーム
スタートアップ企業の Evozyne の研究者は、NVIDIA BioNeMo の基盤モデルを使って、2 つの新しいタンパク質を生成しました。1 つは希少疾患の治療、もう 1 つは大気中の炭素を捕捉するのに役立つ可能性があります。
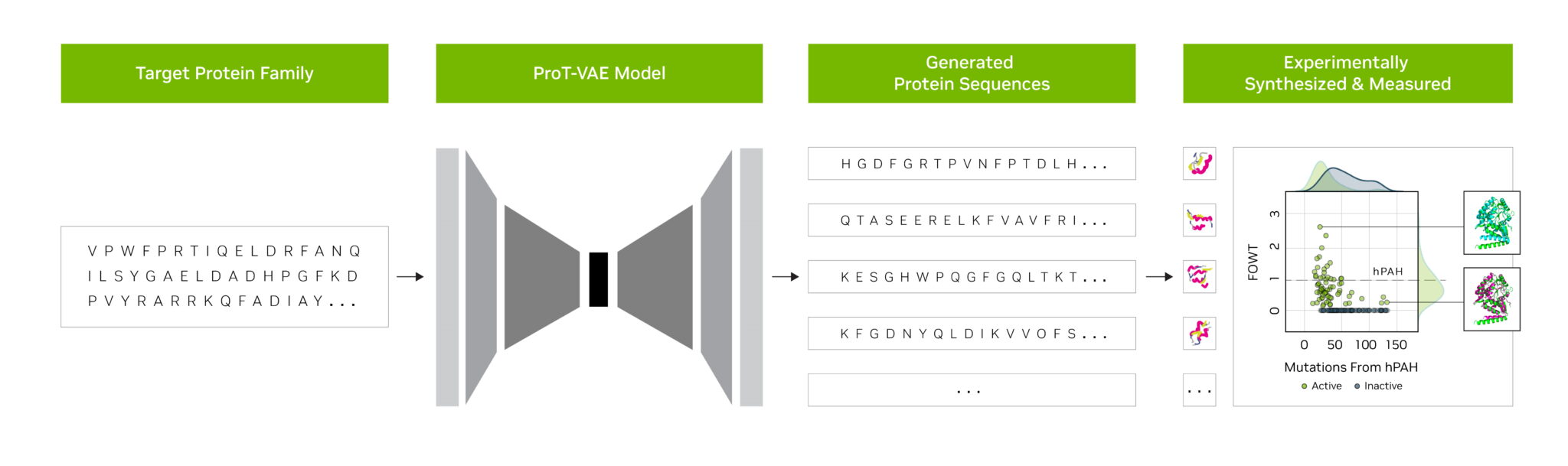 Evozyne と NVIDIA は、共同論文でタンパク質を作成するためのハイブリッド基盤モデルについて説明しました。
Evozyne と NVIDIA は、共同論文でタンパク質を作成するためのハイブリッド基盤モデルについて説明しました。 創薬における生成 AI のためのソフトウェア プラットフォームとクラウド サービスである BioNeMo は、カスタム生体分子 AI モデルのトレーニング、推論の実行、展開のためのツールを提供しています。その中には、NVIDIA と AstraZeneca が開発した化学分野の生成 AI モデルである MegaMolBART が含まれています。
AstraZeneca の分子 AI、ディスカバリー サイエンス、R&D の責任者である Ola Engkvist 氏は、この研究が発表された際に次のように述べています。「AI の言語モデルが文中の単語間の関係を学習できるように、分子構造データでトレーニングしたニューラルネットワークが、現実の分子内の原子間の関係を学習できるようにすることが私たちの狙いです」
これとは別に、フロリダ大学の学術保健センターが、NVIDIA の研究者と共同で GatorTron を作成しました。この大規模言語モデルは、膨大な量の臨床データから洞察を引き出し、医学研究を加速させることを目的としています。
スタンフォードのセンターでは、最新の拡散モデルを応用して医用画像の高度化を図っています。また、NVIDIA はヘルスケア企業や病院が医用画像に AI を活用し、致命的な病気の診断を早めることを支援しています。
ビジネスのための AI 基盤
もう 1 つの新しいフレームワークである NVIDIA NeMo フレームワークは、あらゆる企業が独自の 10 億または 1 兆パラメーターの Transformer モデルを作成し、カスタムのチャットボット、パーソナル アシスタントなどの AI アプリケーションを駆動できるようにすることを目的としています。
昨年の NVIDIA GTC で基調講演の一部を担当した Toy Jensen (TJ) のアバターを動かす 5,300 億パラメーターの自然言語生成モデル (MT-NLG) は、このフレームワークで作成されました。
NVIDIA Omniverse のような 3D プラットフォームに接続された基盤モデルは、インターネットの 3D 進化形であるメタバースの開発を簡素化する鍵となります。これらのモデルは、エンターテインメントや産業用ユーザー向けのアプリケーションやアセットに活用されることになるでしょう。
工場や倉庫ではすでに、より効率的な作業方法を見つけるためのリアルなシミュレーションであるデジタル ツインの内部で基盤モデルを適用しています。
基盤モデルは、工場や物流センターで自律走行車や人間をサポートするロボットをトレーニングする作業を容易にすることができます。また、下の写真のようなリアルな環境を作ることで、自律走行車のトレーニングにも役立ちます。
基盤モデルの新しい使い方は日々生まれており、それを適用するための課題も出てきています。
基盤モデルや生成 AI モデルに関するいくつかの論文では、下記のリスクについて記述されています。
- モデルのトレーニングに使用される膨大なデータセットに内在するバイアスが増幅されること
- 画像やビデオに不正確な情報や誤解を招く情報が含まれること
- 既存の著作物の知的財産権を侵害すること
基盤モデルに関するスタンフォードの論文では次のように述べられています。「将来の AI システムが基盤モデルに大きく依存する可能性が高いことを考えると、私たちはコミュニティとして、基盤モデルに関するより厳格な原則と、その責任ある開発と展開のための指針を開発するために集まることが不可欠です」
現在考えられている安全策には、プロンプトとその出力のフィルタリング、その場でモデルの再キャリブレーション、膨大なデータセットのスクラビングなどがあります。
NVIDIA の応用ディープラーニング研究担当バイス プレジデントのブライアン カタンザロ (Bryan Catanzaro) は次のように述べています。「これらは研究コミュニティとして取り組んでいる問題です。これらのモデルが本当に広く展開されるためには、安全性に多くの投資をする必要があります」
これは、AI の研究者や開発者が未来を創造するために取り組んでいるもう 1 つの分野です。







