Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
NVIDIA A100 GPU と DGX SuperPOD システムが、AI トレーニング向け商用製品として世界最速に認定
NVIDIA の AI トレーニング性能は商用製品において世界最速であることが、MLPerf ベンチマークによって本日証明されました。
A100 Tensor コア GPUは、8 つの MLPerf ベンチマークすべてでアクセラレータあたりのパフォーマンスの最速値を記録しました。大規模なソリューションに費やす時間を最短にするため、HDR InfiniBand に接続された DGX A100 システムの大規模なクラスターである DGX SuperPOD システム も、新しい記録を8 つ樹立しました。今回の記録樹立で真の勝利を得たのは、現在この性能を活用して、AI でビジネスをより速く、より費用対効果の高い方法で変革しようとしているお客様です。
2018 年 5 月に設立された業界ベンチマーク グループである MLPerf でのトレーニング テストにおいて、この結果は NVIDIA にとって 3 年連続となる最強の成果です。NVIDIA は、2018 年 12 月に最初の MLPerf トレーニング ベンチマークで 6 つの記録を、2019 年 7 月には 8 つの記録を打ち立てました。
NVIDIA は、お客様の関心が最も高い、商用製品のカテゴリーで記録を樹立しました。テストの実行時には、Volta アーキテクチャとともに、最新の NVIDIA Ampere アーキテクチャが使用されました。
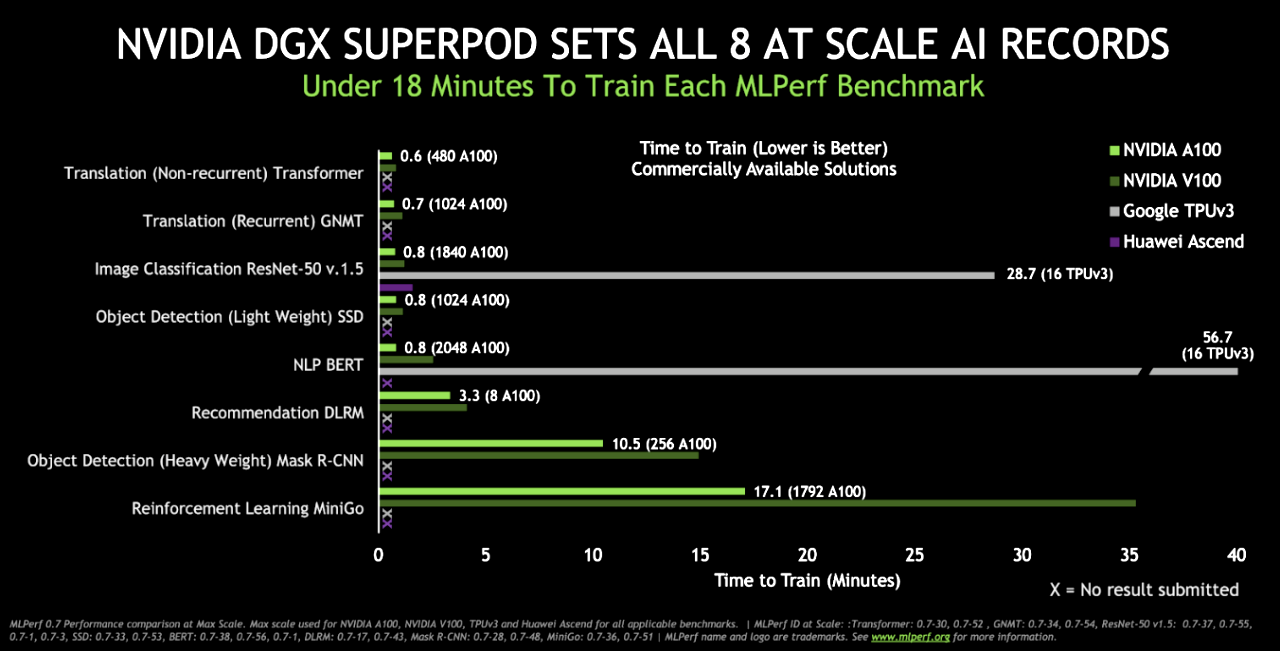 NVIDIA DGX SuperPOD システムは、大規模な AI トレーニングのマイルストーンを新たに樹立しました。
NVIDIA DGX SuperPOD システムは、大規模な AI トレーニングのマイルストーンを新たに樹立しました。
NVIDIA は、すべてのテストにおいて商用利用可能な製品を提出した唯一の企業でした。他社のほとんどが、数か月後まで利用できない可能性があるプレビューカテゴリや、しばらくの間利用できないと予想されるリサーチカテゴリにおける提出でした。
さまざまな記録を打ち破るNVIDIA Ampere
NVIDIA Ampereアーキテクチャに基づく最初のプロセッサである A100 は、性能面での記録樹立に加えて、発売までの期間がこれまでの NVIDIA GPU の中で最も短いプロセッサとなりました。発表時には NVIDIA の第 3 世代 DGX システムに搭載され、わずか 6 週間後には Google のクラウド サービスで一般利用可能となりました。
また、A100 に対する強い需要に応えるのは、Amazon Web Services、Baidu Cloud、Microsoft Azure、Tencent Cloud といった世界トップクラスのクラウド プロバイダーのほか、Dell Technologies、Hewlett Packard Enterprise、Inspur、Supermicroといった主要なサーバー メーカー数十社です 。
世界中のユーザーが A100 を利用して、AI、データ サイエンス、サイエンス コンピューティングの非常に複雑な課題に取り組んでいます。
レコメンダー システムや対話型 AI アプリケーションといった新技術の実現や、COVID-19 の治療方法の模索など、その用途はさまざまですが、すべてのユーザーがNVIDIAの歴代GPUの中で最大のパフォーマンスの飛躍を果たした、第 8 世代 GPU の恩恵を受けています。
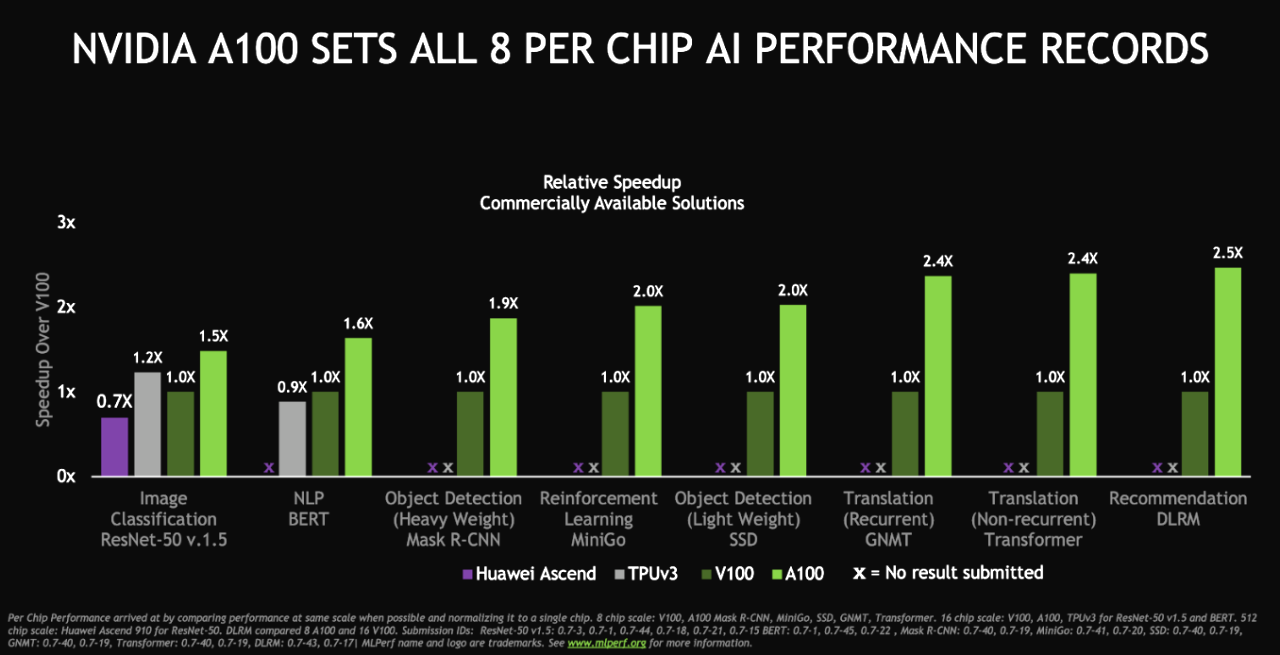 NVIDIA Ampere アーキテクチャは、商用アクセラレータの8つのテストすべてを独占しました。
NVIDIA Ampere アーキテクチャは、商用アクセラレータの8つのテストすべてを独占しました。
1 年半でパフォーマンスが 4 倍向上
最新の結果では、NVIDIA がプロセッサ、ネットワーキング、ソフトウェア、システムまでにおよぶ AI プラットフォームの継続的な進化に注力していることが示されています。
たとえば、同等のスループット レートの場合、MLPerf トレーニングの 1 回目のテストで使用した V100 GPU搭載システムのパフォーマンスと比べて、最新の DGX A100 システムが最大 4 倍のパフォーマンスを発揮することが、今回のテストで示されています。ちなみに、1回目に使用された、NVIDIA V100を搭載した DGX-1システムは、最新のソフトウェア最適化により、最大 2 倍のパフォーマンスを提供できるようになっています。
これらの成果は、AI プラットフォーム全体のイノベーションによって 2 年足らずで実現しました。最新の NVIDIA A100 GPU は、CUDA-X ライブラリ のソフトウェア アップデートと相まって、Mellanox HDR 200Gb/s InfiniBand ネットワーキングで構築されたクラスターを強化しています。
HDR InfiniBand は、非常に低いレイテンシと高いデータ スループットを実現するとともに、Scalable Hierarchical Aggregation and Reduction Protocol (SHARP) テクノロジを介して、スマートなディープラーニング コンピューティング アクセラレーション エンジンを提供します。
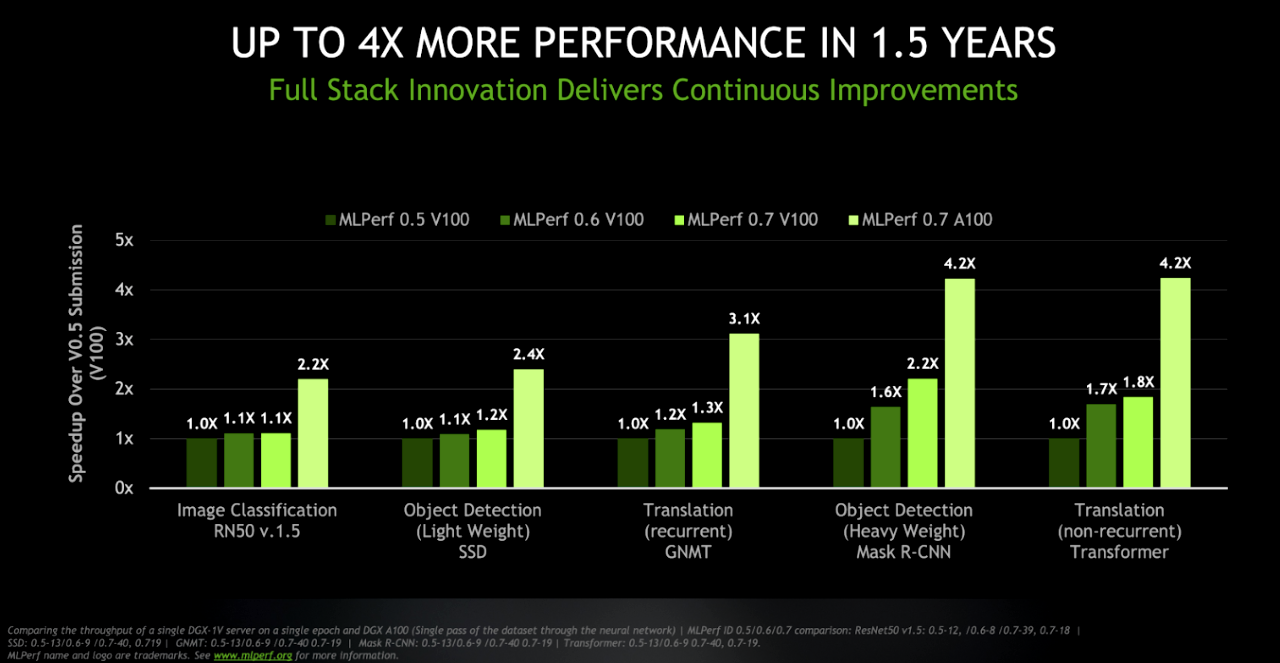 NVIDIA は新しい GPU、ソフトウェアのアップグレード、システム設計の拡張により、AI パフォーマンスのさらなる進化を実現し続けています。
NVIDIA は新しい GPU、ソフトウェアのアップグレード、システム設計の拡張により、AI パフォーマンスのさらなる進化を実現し続けています。
NVIDIAは、レコメンダー システム、対話型 AI、強化学習で真価を発揮
Amazon、Baidu、Facebook、Google、Harvard、Intel、Microsoft、Stanford などの組織に支援されているMLPerf ベンチマークは、AI の進化に合わせて進化し続けています。
最新のベンチマークでは、2 つのテストが新たに採用され、1 つのテストが大幅に改訂されていますが、そのすべてで NVIDIA は優秀な成績を収めました。テスト項目には、AI タスクとして徐々に一般的になってきているレコメンダー システムのパフォーマンスをランク付けするものや、今日使用されている最も複雑なニューラルネットワーク モデルの 1 つである BERT を使用した対話型 AI をテストするものなどがあります。また、強化学習のテストは 19×19 のフルサイズの碁盤で Mini-go (ミニ碁) を使用するもので、ゲーム プレイからトレーニングまでのさまざまな操作が求められる、今回の中で最も複雑なテストでした。
 対話型 AI やレコメンダー システムに NVIDIA の AI を利用しているお客様
対話型 AI やレコメンダー システムに NVIDIA の AI を利用しているお客様
企業はすでに、自分たちの AI の戦略的利用において NVIDIA 製品のパフォーマンスのメリットを享受しています。
Alibaba は 11 月に行われた「独身の日」セールで 380 億ドルもの売上げを記録しましたが、NVIDIA GPU を使用して、CPU と比較して 1 秒あたり 100 倍以上のクエリのレコメンダー システムを提供しました。また、最近では対話型 AI への注目も高く、金融からヘルスケアに至るさまざまな業界の業績向上に一役買っています。
NVIDIA は、こうした業界の強力なジョブの実行に必要なパフォーマンスと、パフォーマンスの採用に必要な使いやすさの両方を提供しています。
ソフトウェアが AI への戦略的道筋を開く
NVIDIA は 5 月に、対話型 AI の Jarvis とレコメンダー システムの Merlin という、2 つのアプリケーション フレームワークを発表しました。Merlin には、最新の MLPerf でも成果を残したトレーニング用の HugeCTR フレームワークが含まれています。
これらのアプリケーション フレームワークは、自動車 (NVIDIA DRIVE)、ヘルスケア (Clara)、ロボティクス (Isaac)、リテール/スマート シティ (Metropolis) などの市場向けに成長を続けています。
 NVIDIA のアプリケーション フレームワークは、開発からデプロイに至るまで、エンタープライズの AI を簡素化します。
NVIDIA のアプリケーション フレームワークは、開発からデプロイに至るまで、エンタープライズの AI を簡素化します。
DGX SuperPOD アーキテクチャが大規模なスピードアップを実現
NVIDIA は、数週間でデプロイ可能な大規模な GPU クラスター用のパブリック リファレンス アーキテクチャである DGX SuperPOD に基づいた社内向けクラスターである Selene 上のシステムにて MLPerf テストを実行しました。このアーキテクチャは、DGX POD で使用されている基本設計とベスト プラクティスを拡張し、今日の AI における最も困難な問題にも対処できます。
Selene は最近、エクサフロップス以上の AI パフォーマンスを備えた米国で最速の産業用システムとして TOP500 リストに初めて登場しました。また、Selene は世界で 2 番目に電力効率の高いシステムとして Green500 リストにも掲載されています。
お客様はすでにこれらのリファレンス アーキテクチャを使用して、独自で DGX POD や DGX SuperPOD を構築しています。例として挙げられるのが 米国最速のAIスーパーコンピューターとなるHiPerGator で、これはフロリダ大学においてカリキュラムを横断した AI イニシアチブの根幹として採用を予定しています。
一方、スーパーコンピューティング センターの最高峰であるアルゴンヌ国立研究所は、DGX A100 を使用して COVID-19 と闘う方法を模索しています。同研究所は、A100 GPU を初めて採用した 6 つのハイパフォーマンス コンピューティング センターのうちの 1 つです。
 NVIDIA DGX POD は幅広くお客様に採用されています。
NVIDIA DGX POD は幅広くお客様に採用されています。
DGX SuperPOD はすでに、自動車業界では Continental、航空宇宙産業では Lockheed Martin、クラウドコンピューティング サービスでは Microsoft などの企業の業績向上に貢献しています。
このシステムはすべて、NVIDIA GPU や DGX システムをサポートする幅広いエコシステムによって稼働しています。
NVIDIA エコシステムによる MLPerf での頼もしい成果
結果を提出した9社のうち、クラウド サービス プロバイダーでは Alibaba Cloud、Google Cloud、Tencent Cloud、サーバー メーカーでは Dell、富士通、Inspur、を含む 7 社が NVIDIA GPU を使用した結果を提出し、NVIDIA のエコシステムの強みが浮き彫りになりました。
 NVIDIA AI プラットフォームを活用してMLPerfの性能結果を提出したパートナー
NVIDIA AI プラットフォームを活用してMLPerfの性能結果を提出したパートナー
パートナーの多くは、NVIDIA のソフトウェア ハブである NGC 上のコンテナ、および一般利用可能なフレームワークを活用して提出しました。
MLPerf パートナーは、NVIDIA A100 GPU を使用するオンライン インスタンス、サーバー、PCIe カードの製品やプランを提供する、20 数社のクラウドサービス プロバイダーおよび OEM で構成されるエコシステムに含まれます。
NGC でテスト済みのソフトウェアが利用可能に
NVIDIA とそのパートナーが最新の MLPerf ベンチマークで使用したほとんどのソフトウェアが、現在 NGC上 で利用できます。
NGC は、いくつかの GPU 最適化コンテナ、ソフトウェア スクリプト、事前トレーニング済みモデル、SDK などを提供しています。こうした機能により、データ サイエンティストや開発者は TensorFlow や PyTorch などの一般的なフレームワーク全体で AI ワークフローを加速できるようになります。
組織はコンテナを採用して、重要な業績を早く得ることができます。結局のところ、これが最も重要なベンチマークなのです。
※NVIDIA Jarvis の名称は 2021 年 7 月に NVIDIA Riva に変更されました。