
NVIDIA、世界最速の 10 台のスーパーコンピューターのうちの 8 台を加速。NVIDIA Selene が、トップレベルのエネルギー効率を誇る、米国最速の産業用システムとしてデビュー
TOP500 スーパーコンピューターの新しいランキングは、AI とデータ分析によって機能が拡張され、NVIDIA のテクノロジによって加速された、現代の科学計算の姿を反映したものとなっています。
現在の世界トップ 10 のスーパーコンピューターのうちの 8 台が、NVIDIA の GPU か InfiniBand ネットワーキング、あるいはその両方を採用しています。これらのスーパーコンピューターには、米国、ヨーロッパおよび中国で最もパワフルなシステムが含まれています。
NVIDIA は、Mellanox との統合で、TOP500 の最新リストに載っているスーパーコンピューターの 3 分の 2 (333 台) に搭載されるようになり、別々の 2 社を合わせても半分にも満たなかった (203 台)、2017 年 6 月のリストの頃から大幅に台数を増やしています。
リストに載っている、新しい InfiniBand システムのおよそ 4 分の 3 (74%) が、NVIDIA Mellanox HDR 200G InfiniBand を導入しており、スマート インターコネクトでの最近のデータ処理量が急速に増えていることを示しています。
HDR InfiniBand を使用している、TOP500 システムの数は、2019 年 11 月のリストから、ほぼ倍増しています。全体としては、InfiniBand を実装しているリスト内のスーパーコンピューターは 141 台で、2019 年 6 月から 12% 増えています。
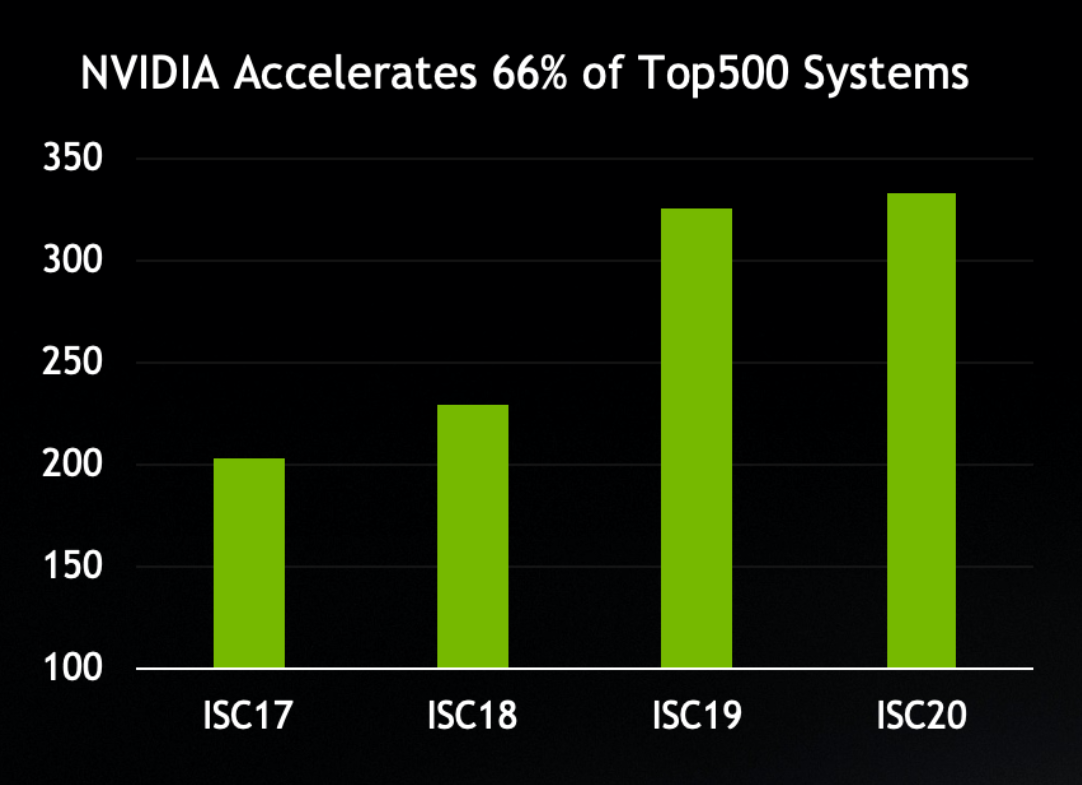
NVIDIA の GPU か Mellanox ネットワーキング、あるいはその両方を採用している TOP500 システムが増加中。
NVIDIA Mellanox InfiniBand および Ethernet ネットワークは、TOP500 スーパーコンピューターのうちの 305 のシステム (61%) を接続しており、これには、InfiniBand を採用している 141 のシステムのすべてと、イーサネットを使用しているうちの 164 (63%) のシステムが含まれています。
エネルギー効率では、NVIDIA GPU を使用しているシステムが、圧倒的有利となっています。GFLOPS/W (ギガフロップス/ワット) で測定した場合、これらのシステムが NVIDIA GPU を導入していないシステムに比べて、エネルギー効率が平均で 2.8 倍高くなっています。
このことも、TOP500 リストの上位 25 台のスーパーコンピューターのうちの 20 台で NVIDIA GPU が使用されている理由の 1 つとなっています。
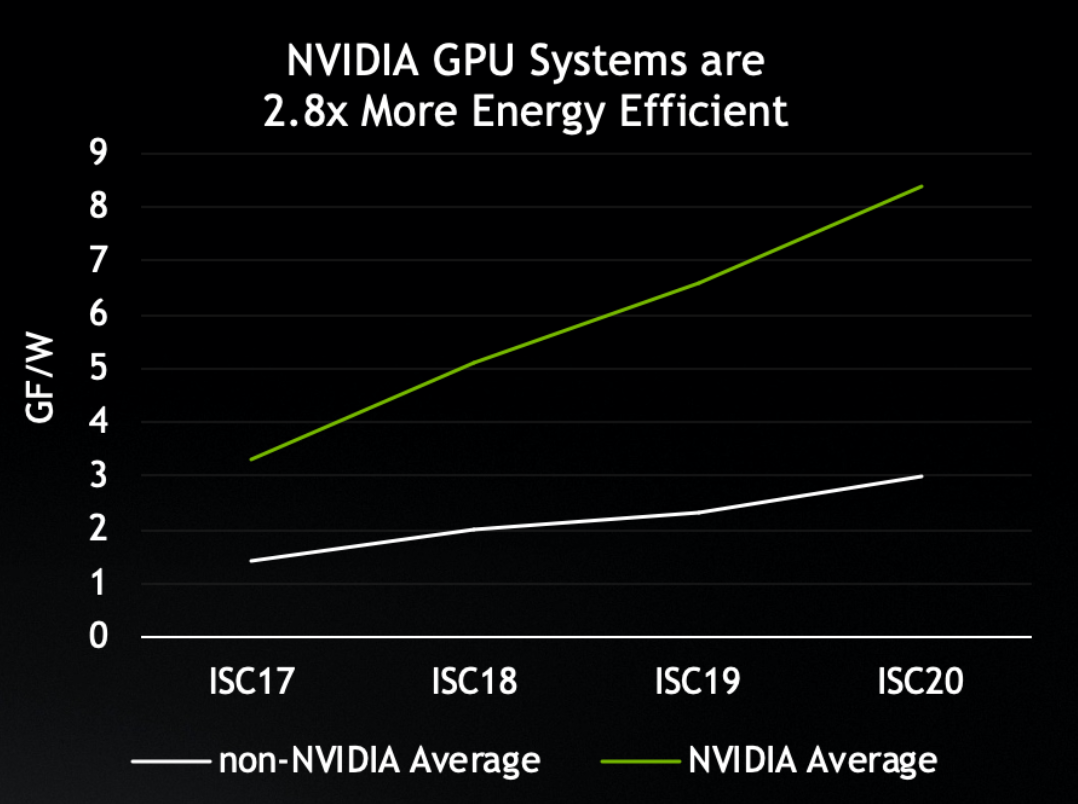
NVIDIA GPU が、TOP500 のスーパーコンピューターのエネルギー効率で他を圧倒。
この電力効率の最良の例となっているのが、NVIDIA の社内研究クラスタに新たに追加された Selene (上の写真) です。このシステムは、Linpack ベンチマークでは 27.5 PFLOPS を記録して、最新の Green500 リストで第 2 位、TOP500 全体では第 7 位となっています。
20.5 GFLOPS/W の効率を誇る Selene は、TOP500 の上位 100 システムにランクされて 20 GFLOPS/W の壁を破った、唯一のシステムです。Selene は、同じく NVIDIA GPU を搭載している、イタリアのエネルギー産業の大企業である Eni S.p.A. の 6 番目にランクされているシステムに次いで、世界で 2 番目にパワフルな産業用スーパーコンピューターでもあります。
エネルギーの消費量では、Selene は、NVIDIA GPU を使用していない TOP500 システムの平均より効率性が 6.8 倍優れています。Selene のこの性能とエネルギー効率は、従来の 64 ビットのシミュレーション用演算と AI 用の低精度演算の両方をスピードアップする、NVIDIA A100 GPU の第 3 世代である Tensor コアによってもたらされています。
Selene のランキングは、組み立てるのに 4 週間もかからなかったシステムにとっての大きな勲章となっています。エンジニアたちがNVIDIA のモジュラー リファレンス アーキテクチャを使用していたため、 Selene を迅速に組み立てることができました。
このガイドでは、NVIDIA が DGX SuperPOD と呼んでいるものが定義されています。DGX SuperPOD は、現代のデータセンターを想定した、パワフルでありながら、柔軟なビルディングブロックである、NVIDIA DGX A100 システムがベースになっています。
DGX A100 は、NVIDIA Mellanox HDR ネットワーキングを使い、6U サーバーに 8 つの A100 GPU を実装した、現在販売中のアジャイル システムです。DGX A100 は、ハイパフォーマンス コンピューティング、データ分析、ならびに学習と推論を含む AI ジョブを効果的に組み合わせ、迅速に展開できるようにするためにするために作られました。
システムから SuperPOD への拡張
リファレンス デザインを活用することで、組織はワールドクラスの演算クラスタを迅速に構築することができます。つまり、NVIDIA Mellanox InfiniBand スイッチを使って、20 基の DGX A100 システムをレゴのようにリンクさせることができるのです。
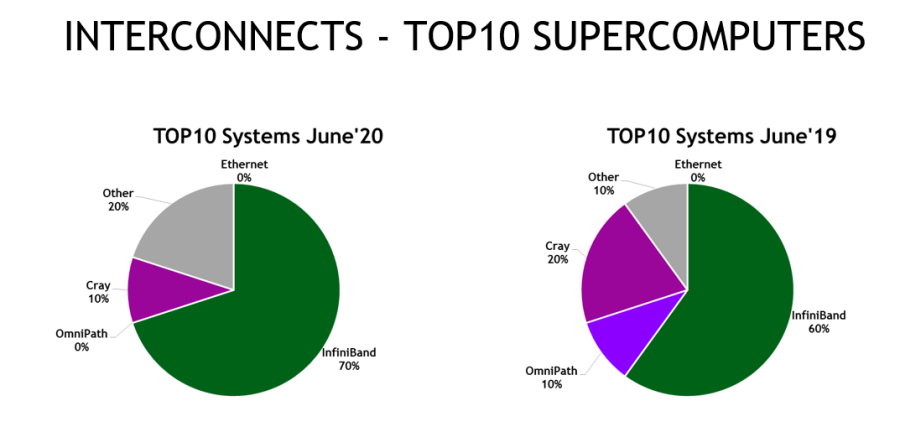
現在、InfiniBand が、中国、ヨーロッパおよび米国で最もパワフルなシステムを含む、上位 10 台のスーパーコンピューターのうちの 7 台を加速。
4 人のオペレーターがいれば、20 のシステムで構成された DGX A100 クラスタを 1 時間程度で組み上げ、TOP500 リストに登場してもおかしくないくらいパワフルな、2 PFLOPS のシステムを構築することができます。このようなシステムは、標準的なデータセンターの電力および温度対応で問題なく動作するように設計されています。
NVIDIA Mellanox InfiniBand のレイヤを追加することにより、エンジニアは、上記の 20 のシステム ユニットのうちの 14 をリンクさせて Selene を構築し、以下の結果を得ることができました。
- 280 基の DGX A100 システム
- 2,240 基の NVIDIA A100 GPU
- 494 の NVIDIA Mellanox Quantum 200G InfiniBand スイッチ
- 56 TB/秒のネットワーク ファブリック
- 7PB の高性能オールフラッシュ ストレージ
Selene について最も強調すべき点の 1 つは、1 EFLOPS の AI 性能を実現できるということです。もう 1 つは、わずか 16 基の DGX A100 システムを使って、TPCx-BB と呼ばれている、データ分析の重要なベンチマークで新記録を達成し、他のシステムの 20 倍の性能を達成した点です。
このような記録は、AI と分析が科学計算の新たな要件の 1 つとなっている現在では、大きな意味を持っています。
世界中で研究者たちがディープラーニングとデータ分析を使い、最も期待できる領域を予測してから、実験を行っています。このアプローチにより、研究者にとって欠かせない、費用と時間のかかる実験数を削減でき、科学的な成果が出るのを加速できるようになります。
たとえば、まだ TOP500 にランクされていない、6 つのシステムが、先月発表されたばかりの NVIDIA A100 を使って現在構築されています。これらのシステムは、科学の新たな時代の到来を告げるものとなり、HPC と AI の融合を加速させることでしょう。
TOP500 が科学計算のキャンパスを拡大
このようなシステムの 1 つがアルゴンヌ国立研究所にあり、ここの研究員は 24 台の NVIDIA DGX A100 で構成されたクラスタを使い、数十億の薬剤をスキャンして、COVID-19 の治療薬を見つけようとしています。
A100 GPU の初期ユーザーについてのレポートで、アルゴンヌ国立研究所の計算生物学者、アーヴィンド ラマナサン(Arvind Ramanathan) 氏は、次のように述べています。「このような作業の多くは、コンピューターでのシミュレーションが困難です。だから、私たちは AI を使って、いつ、どこで、次のサンプルを採集すべきかをインテリジェントに判断できるようにしました」
また、NERSC (米国エネルギー省管轄国立エネルギー研究科学計算センター) では、6,200 基の A100 GPU を搭載したプレエクサスケールのシステムを使い、いくつかのプロジェクトで AI を活用する予定にしています。
たとえば、あるプロジェクトでは、強化学習によって光源実験を制御して、生成系のモデルを適用することで、高エネルギー物理検出器での費用のかかるシミュレーションを再現しようとしています。
ミュンヘンの研究者たちは、Summit スーパーコンピューターの 6,000 基の GPU を使って、コロナウィルスのタンパク質分析を加速しようとしています。これは、TOP500 の主要なシステムが、倍精度計算によって実行される、従来のシミュレーションを超えて拡張していることが、このことからも見てとれます。
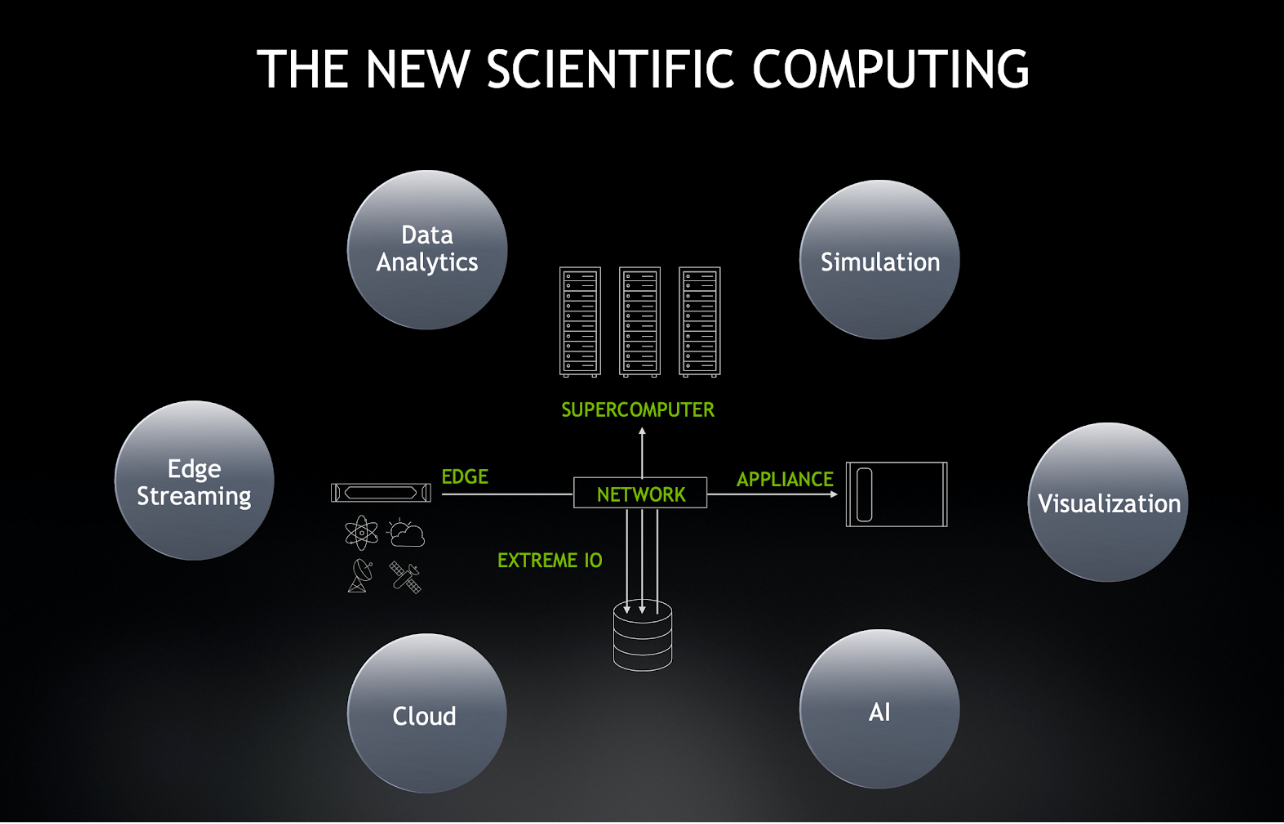
AI、データ分析およびエッジでのストリーミングが、サイエンティフィック コンピューティングを再定義。
ディープラーニングや分析の分野に進出している科学者たちは、クラウド コンピューティング サービスも上手に活用しており、ネットワークのエッジにある、リモートの装置からのデータ ストリーミングも行っています。これらの要素は、以下のような、NVIDIA が加速している、現代の科学計算の 4 つの柱となっています。
- シミュレーション: COVID-19 との戦いにおいて、オークリッジ国立研究所の研究者たちは、Summit スーパーコンピューターに搭載した GPU で AutoDock を実行し、24 時間で 20 億以上の化合物のシミュレーションを行っています。
- AI とデータ分析: Spark 3.0 の GPU アクセラレーションにより、重要で、時間のかかる、機械学習パイプラインの前工程をスピードアップさせることが可能になっています。
- サイエンティフィック エッジ ストリーミング: 先頃 CERN が、大型ハドロン衝突型加速器内の分子衝突イベントで生成される、膨大な量のデータを NVIDIA GPU で 500 分の 1 に縮小できるようになると発表しました。
- ビジュアライゼーション: NVIDIA の IndeX および Magnum IO ソフトウェアが、世界最大規模のインタラクティブなリアルタイム ボリューム ビジュアライゼーションである、火星探査機のビジュアライゼーションを可能にしています。
これらは、クラウドからネットワーク エッジまでを網羅した、AI および分析の加速を研究者と企業の両方が求めているという、大きなトレンドの一部分に過ぎません。このような理由があるため、世界最大規模のクラウド サービス プロバイダーが、世界の大手 OEM と足並みを揃えて NVIDIA GPU を導入しています。
このようにして、最新の TOP500 リストでも、AI と HPC を一般化しよういう、NVIDIA の取り組みが如実に反映されるようになっています。リーダーシップのあるコンピューティング能力を構築したい企業は、世界で最もパワフルなシステムで活用されている DGX システムのような、NVIDIA のテクノロジを利用することができます。
最後に、NVIDIA はTOP500 リストの第 1 位を獲得した、日本の富岳スーパーコンピューターを生み出したエンジニアの皆さまにお祝い申し上げます。このことは、Arm が、ハイパフォーマンス コンピューティングにおける、より現実的で、実行可能性の高い選択肢となっていることを示しています。NVIDIA が、CUDA で加速されるコンピューティング ソフトウェア ライブラリを Arm プロセッサ アーキテクチャで利用できるようにすると 1 年前に発表したのは、このことも理由の 1 つとなっていました。