
NVIDIA Ampere アーキテクチャが演算処理を 2 倍にアップし、さまざまなニューラルネットワークの処理を高速化
ゲームのジェンガをプレイしたことがあるなら、AI のスパース性のことがある程度わかるでしょう。
プレイヤーは木のブロックを相互に交差させながら柱状に積み上げます。それから、それぞれのプレイヤーが交替で、柱を倒さないようにしながら、ブロックを1つずつ取り除いていきます。
最初は簡単ですが、どんどん難しくなり、誰かが抜いたブロックによってタワーが崩壊します。
数年間にわたって、研究者たちはスパース性を使って AI を高速化しようする数々の試みで、ジェンガのようなことをしてきました。研究者たちは、AI の驚異的な精度を破綻させずに、ニューラルネットワークから不要なパラメーターをできるだけ多く引き抜こうとしてきました。
目標は、ディープラーニングに必要となる行列の乗算の山をできるだけ削りとり、良い結果が出るまでの時間を短縮することです。これまで、大きな結果を収めた人はいません。
これまで研究者たちは、ニューラルネットワークの重みの 95% 程度を取り出すために、さまざまなテクニックを駆使してきました。しかしその後、節約した時間よりも多くの時間を費やして、合理化されたモデルの精度を取り戻すために、大規模な手順を作り出さなければなりませんでした。そして、あるモデルでうまくいった手順が、他のモデルではうまくいきませんでした。
今までは。
数字で見るスパース性
NVIDIA Ampere アーキテクチャでは、NVIDIA A100 GPU にネットワークの重みの微細化されたスパース性を利用する第 3 世代の Tensor コアを導入しました。これらのコアは、ディープラーニングの中心となる行列の積和演算処理の精度を犠牲にすることなく、密な演算の最大 2 倍のスループットを提供します。
テストでは、画像分類や物体検知、言語翻訳といった、多様な AI タスクにて、このスパース性に対するアプローチが、密な演算を使用するアプローチと同じ程度の精度が維持されることが示されました。また、畳み込みニューラルネットワークや再帰型ニューラルネットワーク、ならびにアテンションベースのトランスフォーマーでもテストされました。
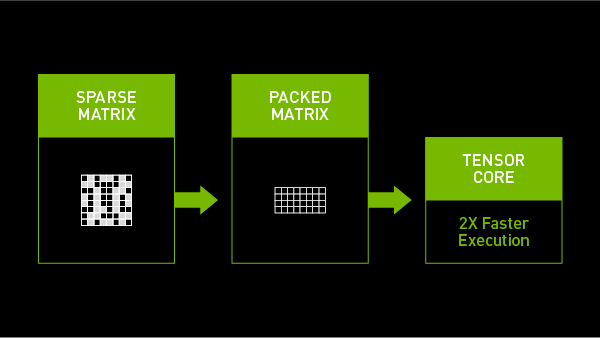 A100 は、疎な行列をまとめて、AI 推論タスクを高速化
A100 は、疎な行列をまとめて、AI 推論タスクを高速化内部の演算速度の向上は、アプリケーション レベルでは大きな効果をもたらします。スパース性を活用することで、A100 GPU は自然言語処理の最先端モデルである BERT (Bidirectional Encoder Representations from Transformers) を、密な演算を使用した場合に比べて 50% 上回る速度で実行することができます。
NVIDIA Ampere アーキテクチャは、ニューラルネットワークにたくさん存在する小さな値を利用して、できる限り広範囲の AI アプリケーションに効果を与えようとします。具体的に言えば、ニューラルネットワークの重みを半分取り除いて、つまり 50% のスパース性で学習するための方法を定義しています。
正しくやれば、少ないほど効果大
研究者の中には、ニューラルネットワークの層からチャネル全体を切り取る、きめの粗い枝刈り (プルーニング) 手法を使う人もいますが、これはしばしばネットワークの精度を下げてしまいます。NVIDIA Ampere アーキテクチャのアプローチでは、精度をそれほど損なうことのない、きめの細かいプルーニング手法を利用した構造的スパース性を採用し、ユーザーはモデルを再学習するときに、検証することができます。
ネットワークが適切にプルーニングされると、A100 GPU が残りの作業を自動化します。
A100 GPU の Tensor コアは疎行列を効率的に圧縮し、適切な密度の演算を可能にします。行列内の値がゼロの場所を効果的に省略することにより、計算量が少なくなり、電力と時間を節約します。疎行列を圧縮することにより、貴重なメモリと帯域幅の使用量も削減できます。
最新の GPU におけるスパース性の役割についての全体像を知るには、NVIDIA の創業者/CEO のジェンスン フアン (Jensen Huang) の基調講演をご覧ください。さらに詳しい情報は、スパース性のウェビナーにご登録いただくか、NVIDIA Ampere アーキテクチャの全容を記した、詳細な記事をお読みください。
スパース性への対応は、AI と HPC の処理性能を新たな高みに引き上げる、NVIDIA Ampere アーキテクチャの多様な新機能の 1 つです。詳細は、以下のテーマを採り上げた NVIDIA ブログをお読みください。
- 精度の高い演算フォーマットである、TensorFloat-32 (TF32) により、AI の学習と一部の HPC タスクを最大 20 倍高速化
- 倍精度の Tensor コアにより、HPC シミュレーションの速度を最大 2.5倍に
- マルチインスタンス GPU (MIG) の導入で、GPU の生産性が最大 7 倍に
- または、NVIDIA A100 GPU についてのウェブページをご覧ください