NVIDIA Ampere アーキテクチャの MIG モードにより、A100 GPU 上で 7 つのジョブを並行して実行
夏の休憩時間、水飲み場の長い列のいちばん最後に並んでいたのを覚えていますか? それでは、そこの水飲み場に蛇口がいくつもあり、全員に冷たくておいしい水が同時に行き渡っているところを想像してみてください。
これがマルチインスタンス GPU (MIG) の基本的な考え方で、NVIDIA Ampere アーキテクチャでは、これが可能になるのです。
MIG では、1 つの NVIDIA A100 GPU を最大 7 つの独立した GPU に分割します。これらが同時に機能し、それぞれがメモリ、キャッシュおよびストリーミング マルチプロセッサを備えています。これにより、A100 GPU は従来の GPU に比べて最大 7 倍の利用率で、サービス品質 (QoS) を保証することができます。
MIG モードの A100 は、最大 7 つの異なるサイズの AI または HPC のワークロードを組み合わせて実行できます。この機能は、一般的に最新の GPU の全性能を必要としない、AI 推論ジョブに特に役に立ちます。
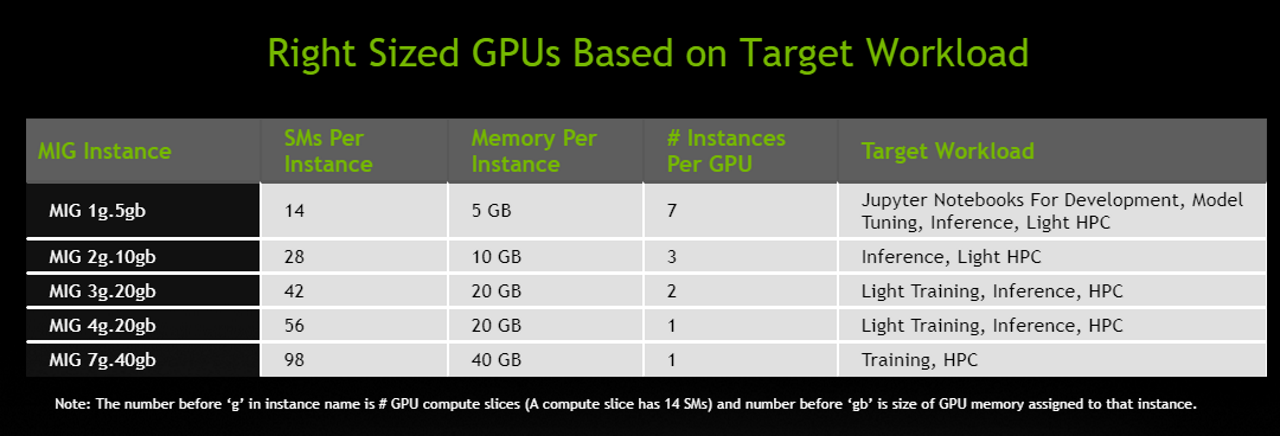
たとえば、ユーザーはそれぞれが 20 ギガバイト (GB) のメモリを持つ MIG インスタンスを 2 つ作成することや、10 GB のインスタンスを 3 つ作成することも、5 GB のインスタンスを 7 つ作成することもできます。ユーザーは、それぞれのワークロードに適した組み合わせで作成できます。
 システム管理者は推論、学習および HPC のワークロードを組み合わせてスケジュールして、1 基の A100 GPU 上で同時に実行可能
システム管理者は推論、学習および HPC のワークロードを組み合わせてスケジュールして、1 基の A100 GPU 上で同時に実行可能MIG は GPU インスタンスを分離して実行するため、障害の分離が可能になり、あるインスタンスの問題が同じ物理 GPU で実行されている他のインスタンスに影響を与えません。それぞれのインスタンスの QoS が保証されているので、ユーザーは自身のワークロードに求められているレイテンシとスループットが得られることを保証されます。
クラウド サービス プロバイダーやその他の企業では、MIG によって自社の GPU サーバーの利用率が上がり、ユーザーに最大 7 倍の GPU インスタンスを提供することができます。
Google Cloud の主席ソフトウェア エンジニアであるティム ホッキン (Tim Hockin) 氏は、次のように述べています。「NVIDIA は、Google Cloud の戦略的パートナーであり、当社では NVIDIA がお客様のためにイノベーションをもたらすことを喜ばしく思っています。MIG は、共有の Kubernetes クラスタにおいて、GPU の効率性と利用率を新たなレベルに引き上げることを可能にします。当社では、NVIDIA および Kubernetes コミュニティとともに、これらの共有 GPU でのユースケースを実現し、それらが Google Kubernetes Engine を通じて利用されるのを楽しみにしています」
MIG により、企業での推論が飛躍的に向上
エンタープライズ ユーザーの場合、MIG により、AI モデルの開発と展開の両方を加速できるようになります。
MIG により、最大 7 人のデータ サイエンティストに専用の GPU への同時アクセスを提供し、ディープラーニング モデルをファインチューニングして最適な精度と性能を得る作業を並行して行えるようになります。これは時間のかかる作業ですが、多くの場合、それほど演算能力を必要としないので、MIG の優れたユースケースと言えます。
モデルの実行準備ができると、MIG により、単一の GPU で最大 7 つの推論ジョブを同時に処理できるようになります。これは、GPU のフル性能を必要としない、小規模で低レイテンシのモデルを含む、バッチサイズが 1 の推論ワークロードに最適です。
Postmates の人工知能担当ディレクターであるチェンユー グオ (Zhenyu Guo) 氏は、次のように述べています。「NVIDIA のテクノロジは、当社の配達ロボット プラットフォームである Serve に欠かせません。MIG により、導入するすべてのGPUを最大限に活用することができます。変わり続けるワークロード要件に合わせて演算リソースを動的に再構成し、クラウドベース インフラストラクチャを最適化して、効率化と費用削減が最大化を実現できるようになります」
IT/DevOps 向けに構築
ユーザーは、AI および HPC 向けに MIG の利点を得るために、CUDA プログラミング モデルを変更する必要はありません。MIG は、既存の Linux オペレーティング システム、ならびに Kubernetes およびコンテナーで動作します。
NVIDIA は A100 向けのソフトウェアを用意しており、これにより MIG を構築できます。このソフトウェアには、GPU ドライバ、NVIDIA の CUDA 11 ソフトウェア (近日リリース)、アップデートされた NVIDIA コンテナー ランタイム、および NVIDIA デバイス プラグインを通じて入手可能な、Kubernetes の新しいリソース タイプが含まれています。
MIG と NVIDIA 仮想コンピュート サーバー (vComputeServer) を組み合わせれば、Red Hat Virtualization および VMware vSphere といったハイパーバイザーの管理および監視が可能になります。この組み合わせは、ライブ マイグレーションやマルチテナンシーといった人気の機能にも対応する予定です。
Red Hat のマーケティング担当ディレクターであるチャック ドゥビューク (Chuck Dubuque) 氏は、次のように述べています。「当社のお客様は、分離とセキュリティを提供しつつ、仮想マシンで実行するマルチテナントのワークフローを管理する必要性が高まっています。NVIDIA A100 GPU の新しいマルチインスタンスの GPU 機能により、クラウドからエッジに至る Red Hat のプラットフォームで、新しい多様な種類の AI アクセラレーション ワークフローを実行できるようになります」
NVIDIA A100 とそのソフトウェアを導入することで、ユーザーは物理的に複数の GPU を使っているときのように、新たな GPU インスタンスで、ジョブの監視やスケジュールが可能になります。
詳しい詳細
A100 GPU の MIG の役割についての全体像を知るには、NVIDIA の創業者/CEO である ジェンスン フアン (Jensen Huang) の基調講演をご覧ください。さらに詳しい情報は、MIG のウェビナーにご登録いただくか、NVIDIA Ampere アーキテクチャの全容を記した、詳細な記事をお読みください。
MIG は、NVIDIA Ampere アーキテクチャのさまざまな新機能の 1 つであり、AI の学習、推論および HPC の処理性能を新たな高みに引き上げるものです。詳細は、以下のテーマを採り上げた NVIDIA ブログをお読みください。
- TensorFloat-32 (TF32) アクセラレーテッド フォーマットにより、AI の学習と一部の HPC タスクを最大 20 倍高速化
- 倍精度の Tensor コアにより、HPC シミュレーションと AIを最大 2.5倍に高速化
- スパース性への対応により、AI 推論の計算スループットを 2 倍向上
- その他は、A100 GPU についてのウェブページをご覧ください