
GPU Technology Conference (GTC) 2019 において、NVIDIA は、Jetson Nano 開発者キット を発表しました。これは、組込み設計者や研究者、個人開発者がコンパクトで使いやすいプラットフォームに本格的なソフトウェアを実装して最先端の AI を活用できるようにするコンピューターで、現在 99 ドルで手に入れることができます。Jetson Nano は、64 ビット クアッドコア ARM CPU と 128 コアの NVIDIA GPU により、472 GFLOPS の演算性能を発揮します。さらに、5W/10W の電力モードと 5V の DC インプットを備えた、効率的で低電力のパッケージには、4 GB の LPDDR4 メモリーが含まれています。
新たにリリースされた JetPack 4.2 SDK はグラフィックス アクセラレーションを備えた Ubuntu 18.04 をベースとした、Jetson Nano 向けの包括的なデスクトップ Linux 環境を実現し、NVIDIA CUDA Toolkit 10.0 に対応しているほか、cuDNN 7.3 や TensorRT 5.0 といったライブラリを備えています。さらに、この SDK により、TensorFlow や PyTorch、Caffe、Keras、MXNet といった、オープンソースの広く普及している機械学習 (ML) フレームワークだけでなく、OpenCV や ROS のようなコンピューター ビジョンおよびロボティクス開発のためのフレームワークもネイティブにインストールすることができます。
JetPack 4.2 SDK は、これらのフレームワークならびに NVIDIA の主要 AI プラットフォームと完全な互換性があるため、AI ベースの推論を従来よりも簡単に Jetson に展開できます。Jetson Nano は複雑なディープ ニューラル ネットワーク (DNN) の多くのモデルでリアルタイムのコンピューター ビジョンおよび推論を実現します。これらの機能により、マルチセンサーの自律動作ロボットやインテリジェントなエッジでの分析機能を備えた IoT デバイス、先進 AI システムが生み出せるようになります。またML フレームワークを用いることでJetson Nano 上でローカルに実装されたネットワークを再トレーニングする転移学習も可能です。
Jetson Nano 開発者キットは、実装面積がわずか 80x100mm で、4 つの高速 USB 3.0 ポート、MIPI CSI-2 カメラ コネクター、HDMI 2.0 と DisplayPort 1.3、ギガビット イーサネット、M.2 Key-E モジュール、MicroSD カード スロット、および 40 ピン GPIO ヘッダーを備えています。ポートと GPIO ヘッダーは、多くの一般的な周辺機器、センサー、ならびに NVIDIA が GitHub でオープンソース公開している、3D プリンタで制作が可能なディープラーニング用 JetBot といった、すぐに使用できるプロジェクトと即座に組み合わせることができます。
この開発者用キットは、SD カードのスロットを備えたあらゆる PC で初期化およびBSPイメージの取り込みができる、リムーバブル MicroSD カードから起動します。この開発者用キットは、Micro USB ポートまたは DC 5V のバレル型コネクターのいずれかから、簡単に電力を供給することができます。カメラ コネクターは、Jetson エコシステム パートナーより発売されている 8MP IMX219 ベースのモジュールなど、お買い求めやすい価格の MIPI CSI センサーと互換性があります。さらに、JetPack でドライバー対応されている、Raspberry Pi カメラ モジュール v2 との互換性もあります。表 1 は、主要な仕様を示しています。
| 処理 | |
|---|---|
| CPU | 64 ビット クアッドコア ARM CPU A57 @ 1.43GHz |
| GPU | 128 コア NVIDIA Maxwell @ 921MHz |
| メモリー | 4GB 64ビット LPDDR4 @ 1600MHz | 25.6 GB/s |
| ビデオ エンコーダー* | 4Kp30 | (4x) 1080p30 | (2x) 1080p60 |
| ビデオ デコーダー* | 4Kp60 | (2x) 4Kp30 | (8x) 1080p30 | (4x) 1080p60 |
| インターフェース | |
| USB | 4x USB 3.0 A (ホスト) | USB 2.0 Micro B (デバイス) |
| カメラ | MIPI CSI-2 x2 (15 ポジション フレックス コネクター) |
| ディスプレイ | HDMI | ディスプレイ ポート |
| ネットワーク | ギガビット イーサネット (RJ45) |
| ワイヤレス | M.2 Key-E および PCIe x1 |
| ストレージ | MicroSD カード (少なくとも 16GB UHS-1 推奨) |
| その他 I/O | (3x) I2C | (2x) SPI | UART | I2S | GPIO |
* 総スループットでの並行ストリームの最大数を示しています。対応のビデオ コード: H.265、H.264、VP8、VP9 (VP9デコードのみ)
開発者キットは、260 ピンのSODIMM 形式システムオンモジュール
(SoM) がベースになっています。この SoM には、プロセッサ、メモリーおよびパワーマネージメント回路が含まれています。Jetson Nano コンピューティングモジュールは 45x70mm のサイズで、量産システムへの実装を行うための組込み設計者向けとなっており、129 ドルの価格 (発注数量が 1,000 個の場合) で 2019 年 6 月から出荷開始の予定です。この量産製品向けのコンピューティングモジュールには、16GB の eMMC オンボードストレージ、ならびに PCIe Gen2 x4/x2/x1、MIPI DSI、追加の GPIO、および x4 で最大 3 台または x4/x2 の構成で最大 4 台のカメラに接続する、12 レーン MIPI CSI-2 を備えた、拡張 I/O が含まれています。Jetson の統合されたメモリー サブシステムは、CPU、GPU およびマルチメディア エンジンによって共有され、簡素化されたZeroCopy センサーからの取り込みによって処理パイプラインを効率化することができます。

図 2. 260 ピンのエッジ コネクターを備えた、45X70mm のJetson Nano コンピューティングモジュール
ディープラーニング推論のベンチマーク
Jetson Nano はTensorFlow や PyTorch、Caffe/Caffe2、Keras、MXNe といった、普及している ML フレームワークのフル ネイティブ バージョンを含む、多様な先進ネットワークを実行することができます。これらのネットワークは画像認識、物体の検知と位置確定、姿勢評価、セマンティック セグメンテーション、動画の向上、ならびにインテリジェントな分析といったロバストな機能を実装することで、自律動作マシンや複雑な AI システムを構築するのに使用することができます。
以下の図 3 は、オンラインで入手可能な主要モデルを対象とした、推論ベンチマークの結果を示しています。この推論ではバッチサイズ 1 で精度を FP16 と設定し、JetPack 4.2 に含まれているNVIDIA の TensorRT アクセラレーション ライブラリ が使用されました。Jetson Nano は多くのシナリオにおいてリアルタイムでの推論を可能にし、複数の高解像度のビデオ ストリームを処理することができます。
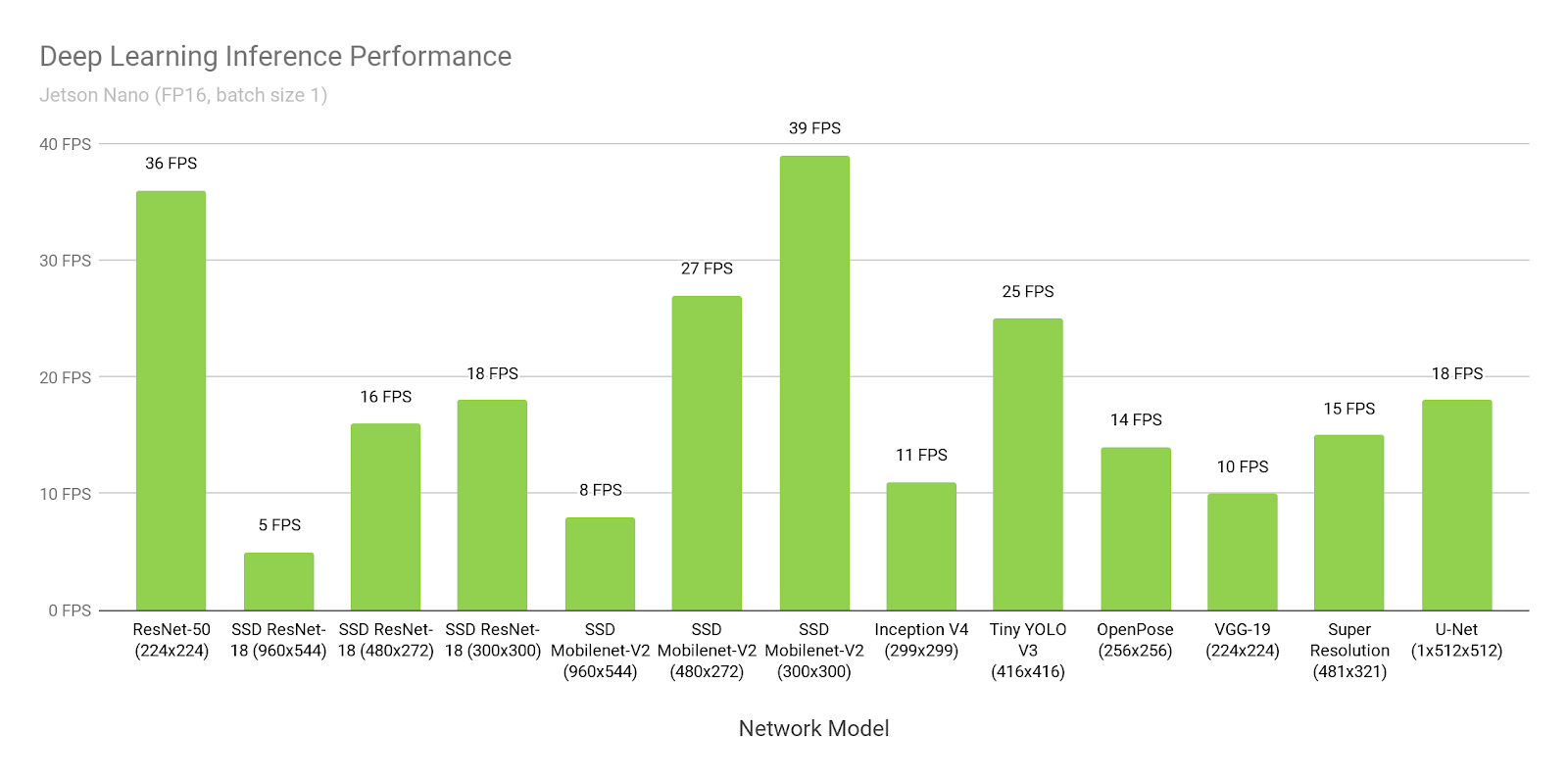
図 3:精度 FP16、バッチサイズ 1 の設定でJetson Nano において TensorRT を使用したときの様々なディープラーニング学習推論ネットワークのパフォーマンス
以下の表 2 には、Raspberry Pi 3、Raspberry Pi 3とIntel Neural Compute Stick 2の組み合わせソリューション、および Google Edge TPU Coral Dev Board といった他のプラットフォームのパフォーマンスを含めた結果が記載されています。
| モデル | 用途 | フレームワーク | NVIDIA Jetson Nano | Raspberry Pi 3 | Raspberry Pi 3 + Intel Neural Compute Stick 2 | Google Edge TPU Dev Board |
|---|---|---|---|---|---|---|
| ResNet-50 (224×224) |
分類 | TensorFlow | 36 FPS | 1.4 FPS | 16 FPS | DNR |
| SSD ResNet-18 (960×544) |
物体検知 | TensorFlow | 5 FPS | DNR | DNR | DNR |
| SSD ResNet-18 (480×272) |
物体検知 | TensorFlow | 16 FPS | DNR | DNR | DNR |
| SSD ResNet-18 (300×300) |
物体検知 | TensorFlow | 18 FPS | DNR | DNR | DNR |
| SSD Mobilenet-V2 (960×544) |
物体検知 | TensorFlow | 8 FPS | DNR | 1.8 FPS | DNR |
| SSD Mobilenet-V2 (480×272) |
物体検知 | TensorFlow | 27 FPS | DNR | 7 FPS | DNR |
| SSD Mobilenet-V2 (300×300) |
物体検知 | TensorFlow | 39 FPS | 1 FPS | 11 FPS | 48 FPS |
| Inception V4 (299×299) |
分類 | PyTorch | 11 FPS | DNR | DNR | 9 FPS |
| Tiny YOLO V3 (416×416) |
物体検知 | Darknet | 25 FPS | 0.5 FPS | DNR | DNR |
| OpenPose (256×256) |
姿勢評価 | Caffe | 14 FPS | DNR | 5 FPS | DNR |
| VGG-19 (224×224) |
分類 | MXNet | 10 FPS | 0.5 FPS | 5 FPS | DNR |
| Super Resolution (481×321) |
画像処理 | PyTorch | 15 FPS | DNR | 0.6 FPS | DNR |
| Unet (1x512x512) |
セグメンテーション | Caffe | 18 FPS | DNR | 5 FPS | DNR |
メモリー容量の制限、対応していないネットワーク レイヤ、あるいはハードウェアおよびソフトウェアの制限といった理由で、DNR (実行せず)という結果がところどころに記載されてあります。機能を固定したニューラル ネットワーク アクセラレーターの場合、ハードウェアが特定のレイヤの処理だけに対応している、あるいは重大なデータ転送ペナルティを避けるために、ネットワーク ウエイトとネットワーク アクティベーションが一部のオンチップ キャッシュにのみ適応している、といった理由から、対応しているユースケースの幅が比較的狭くなっていることがあります。それによりニューラル ネットワーク アクセラレーターで行われるべき処理がハードウェアで対応してないレイヤを動作させるときにホスト CPU に頼ったり、フレームワークの簡素化されたサブセット(たとえばTFLite)に対応しているモデル コンパイラに依存したりすることがあります。
Jetson Nanoの場合は、フレキシブルなソフトウェアとフレームワークへのフル対応、メモリー容量、ならびに統合メモリー サブシステムにより、多様なバッチ サイズの複数のセンサー ストリームを含む、複数の異なったネットワークを、フル HD の解像度に至るまで並行して実行することができます。上記のベンチマークは広く普及しているネットワークをサンプルにしたものですが、ユーザーは上記以外の多様なモデルやカスタム アーキテクチャをJetson Nanoに実装しても同様に推論パフォーマンスを加速させることができます。さらに、Jetson Nano は DNN 推論だけに用途が限られているわけではありません。FFT や BLAS、LAPACK 演算などのアルゴリズムをにユーザー定義の CUDA カーネルと共に用いることでJetson Nano の CUDA アーキテクチャをコンピューター ビジョンやデジタル信号処理 (DSP) に活用することもできます。
マルチストリームのビデオ分析
Jetson Nano は最大 8 つの HD フルモーション ビデオストリームをリアルタイムで処理することが可能で、ネットワーク ビデオ レコーダー (NVR) やスマート カメラ、IoT ゲートウェイ向けの低消費電力かつインテリジェントなビデオ分析 プラットフォームとしてエッジに実装できます。NVIDIA の DeepStream SDK はZeroCopy と TensorRT によって、エンドツーエンドの推論パイプラインを最適化し、エッジならびにオンプレミスのサーバーにおいて究極の性能を発揮します。下の動画ではJetson Nano がフル解像度かつ 500 メガピクセル/秒 (MP/s) のスループットで実行されるResNet ベースのモデルを使い、8 つの 1080p30 のストリームで並行して物体検知を行っております。
以下図4 のブロック図は、ギガビット イーサネットを介して入力される、最大 8 つのデジタル ストリームの取り込みおよびディープラーニングを活用した分析処理を行うために Jetson Nano を利用している NVR アーキテクチャの例を示しています。このシステムは、500 MP/s で H.264/H.265 をデコードし、250 MP/s で H.264/H.265 ビデオをエンコードできます。

図 4.Jetson Nano と 8 台の HD カメラを使った場合の参考 NVR システム アーキテクチャ例
Jetson Nano 対応の DeepStream SDK は2019 年第 2 四半期にリリースが予定されています。この新しいリリースの通知はDeepStream 開発者プログラムへの登録によって受け取ることができます。
JetBot
図 5 のNVIDIA JetBot は新しいオープンソースの自律動作ロボティクス キットで、AI を活用したディープラーニング ロボットを 250 ドル未満で作成できるように、すべてのソフトウェアおよびハードウェア プランが公開されております。このハードウェア リストには、Jetson Nano、IMX219 8MP カメラ、3D プリントが可能なシャシー、バッテリー パック、モーター、I2C モーター ドライバーおよびアクセサリーが含まれています。

図 5. Jetson Nano を活用したオープンソースのディープラーニング自律動作ロボット用キット、NVIDIA JetBot は、250 ドル未満で組み立てが可能
このプロジェクトではモーターの制御や障害物検知、て人や家庭内にある物体を追跡できるようにするための訓練、ならびにJetBot がフロア全面の経路を辿れるように訓練するための Python コードの書きかたの実例が、Jupyter notebook を通して簡単に学ぶことができます。コードを拡張しAI フレームワークを利用すれば、JetBotに新しい機能を追加することができます。
JetBot 用の ROS ノードも用意してあるので、ROS Melodic への対応によってSLAM や最先端のパス プランニングといった、ROS ベースのアプリケーションや機能の実装もできるようになっています。JetBot 用 ROS ノードがあるGitHub リポジトリでは、ロボットへの実装の前に仮想環境で AI の新たな振る舞いを開発およびテストできる、Gazebo 3D ロボティクス シミュレーター用のモデルも用意されています。この Gazebo シミュレーターはカメラの合成データも生成し、Jetson Nano によって実行されます。
Hello AI World
Hello AI World は、Jetson を使用しAI のパワーを初めて経験するための最適な手段です。JetPack SDK と NVIDIA TensorRT が備わった Jetson Nano 開発者キットを使い、わずか数時間程度で一連のディープラーニング推論のデモを立ち上げ、リアルタイムの画像分類と物体検知 (事前にトレーニングされたモデルを使用) を実行することができます。このチュートリアルは、コンピューター ビジョン関連のネットワークに焦点を当てたもので、実際のカメラを接続して行います。また、C++ で書かれた認識プログラムのコードを自分自身で簡単に書けるようになります。ディープラーニング ROS ノードの利用により、これらの認識、検知およびセグメンテーションの推論機能を ROS に統合させ、ロボティクスの先進のシステムおよびプラットフォームに実装することができます。このようなリアルタイム推論ノードを、既存の ROS アプリケーションに簡単に適用させることができるのです。図 6 は、いくつかの実例を示しています。

図 6. Hello AI World と Two Days to a Demo チュートリアルにより、ユーザーはコンピューター ビジョン用のディープラーニングの実装を素早く設計し実行することが可能に
自分自身でモデルのトレーニングを行いたいと望む開発者は、フルバージョンの「Two Days to a Demo」チュートリアルのご利用をお勧めします。このチュートリアルでは転移学習によって画像分類、物体検知およびセマンティック セグメンテーションのモデルの再トレーニングおよびカスタマイゼーションを行うための一連の流れが示されています。転移学習では、特定のデータセットのモデル ウエイトが微調整されますので、モデルを一から訓練する必要はありません。モデルのトレーニングは推論に比べてより多くの演算リソースと時間が必要になるため、転移学習はNVIDIA の GPU を個別に実装した PC またはクラウド インスタンスで行うのがもっとも効果的です。
しかしながら、Jetson Nano はTensorFlow や PyTorch、Caffe などのフルトレーニング フレームワークを実行できますので、他の専用のトレーニング マシンを利用できない方、あるいはトレーニングの実行に時間をかけても問題ないという方はJetson Nanoで転移学習による再トレーニングも行えます。表 3 はImageNet の 22.5GB のサブセットで 200,000枚の画像を用いた Alexnet および ResNet-18 でのトレーニングにおいて、Jetson Nano を使った PyTorch での Two Days to a Demo チュートリアルからの転移学習で得られた結果のいくつかを示しています。
| ネットワーク | バッチ サイズ | エポック当たり時間 | 画像/秒 |
|---|---|---|---|
| AlexNet | 64 | 1.16 時間 | 45 |
| ResNet-18 | 64 | 3.22 時間 | 16 |
エポック当たり時間とは、200K の画像のデータセットのトレーニングを 1 通り行うための所要時間です。分類ネットワークでは、実際に使用するのに適した結果を出すには最低で 2 つから 5 つのエポックが必要になる場合があり、量産モデルでは最適な精度を得られるまでに個々の GPU システムでより多くのエポックにわたってトレーニングする必要があります。ただし、Jetson Nano があれば、夜のうちにネットワークの再トレーニングを行うことで、低コストのプラットフォームでディープラーニングと AI の実験を行えます。すべてのカスタム データセットが上記の例のように 22.5GB もの大きさを持っているわけではありません。そのため、画像/秒はJetson Nano のトレーニング パフォーマンスを示しており、エポック当たり時間にデータセットのサイズ、トレーニング バッチのサイズ、ならびにネットワークの複雑さを反映させたものとなっています。トレーニング時間を増やせばJetson Nano で他のモデルの再トレーニングも行えます。
あらゆる人のためのAI
Jetson Nano の演算性能、コンパクトなサイズならびに柔軟性は、AI を活用したデバイスや組込みシステムを作る開発者に無限の可能性をもたらします。99 ドルの Jetson Nano 開発者キットを今すぐ動かしてみましょう。Jetson Nano 開発者キットは当社の主要グローバル ディストリビューターを通じて販売されるほか、メーカーの流通経路、Seeed Studio および SparkFun でもご購入いただけます。NVIDIA の Embedded Developer Zone からソフトウェアと文書をダウンロードし、open-source projects でJetson Nanoで動かせるいくつかのアプリケーション例を探してみてください。そしてJetson DevTalk forums のコミュニティに参加しさまざまなサポート情報を入手するとともに、皆さまが取り組んだプロジェクトもぜひここでシェアしてください。皆さまの作品を見せていただくのを楽しみしています!