
子犬は数週間で、ある決まった行動をすればおいしいおやつをもらえたり、もっと抱っこしてもらえたり、お腹をさすってもらえたりすることを学ぶことができますが、ご褒美のない行動に関してはそうはいきません。正の強化という仕組みにより、ペットの犬はやがて、リスを追いかけるよりも人間の側にいる方が報酬をもらえる可能性が高いと予想するようになります。
深層強化学習はロボティクスや複雑な戦略問題に利用する AI モデルをトレーニングするための手法ですが、原理は同じです。
強化学習では、ソフトウェア エージェントが実際の環境または仮想環境とやり取りし、報酬からのフィードバックを頼りにして、目標を達成するための最良の方法を学習します。トレーニング中の子犬の脳のように、強化学習のモデルは環境や報酬について得られた情報を使用して、エージェントが次に実行すべきアクションを決定します。
これまで、ほとんどの研究者はCPU と GPU を組み合わせて強化学習モデルを実行していました。これは、環境のシミュレーション、報酬の計算、次に実行するアクションの選択、実際のアクションの実行、そして経験からの学習といったプロセスにおけるさまざまな段階に対して、コンピューターのさまざまな部分が対処しているということです。
ただし、CPU コアと強力な GPU との切り替えは本来ならば非効率なことであり、強化学習のトレーニング プロセス中の複数のポイントでシステムのメモリの一部分から別の部分へのデータ転送を行う必要があります。これは例えるなら、新しい概念を理解する前に、教室から教室へ、さらには図書館へ、大量の本やメモを持ち歩かなければいけない学生のようなものです。
Isaac Gym を使用することで、NVIDIA の開発者は、代わりに強化学習のパイプライン全体を GPU で実行できるようになり、大幅なスピードアップだけでなく、モデルの開発に必要なハードウェア リソースの削減も実現します。
ここからは、この画期的な進歩が深層強化学習のプロセスにとってどのような意味を持つのか、そして開発者にはどれだけのアクセラレーションがもたらされるかを説明していきます。
GPU 上での強化学習: シミュレーションの後で実際のアクションへ
ヒューマノイド ロボットが階段を上り下りするといった、ロボティクスのタスク用に強化学習モデルをトレーニングする場合、現実の世界よりもシミュレーション環境を使用する方がはるかに速く、安全で、簡単です。シミュレーションでなら、1 回のタスクで数千時間分の経験をすぐに積むことができる仮想ロボットを開発者は山ほど作成できます。
実世界でのみテストした場合、トレーニング中のロボットが落下したり、物体にぶつかったり、誤った取り扱いをしたりする可能性があり、ロボット自体の機械や、ぶつかった物体、またはその周囲に損害を与える恐れがあります。シミュレーションでのテストでは、強化学習モデルが想定外の出来事にも対処できる練習をするためのスペースを設けることができ、現実の世界に移行しても失敗が少なくなります。
今日の一般的なシステムでは、NVIDIA PhysX シミュレーション エンジンが、強化学習のプロセスの経験収集フェーズを NVIDIA GPU 上で実行します。しかし、トレーニング アプリケーションにおけるその他のステップでは、開発者は従来通り CPU を使用してきました。
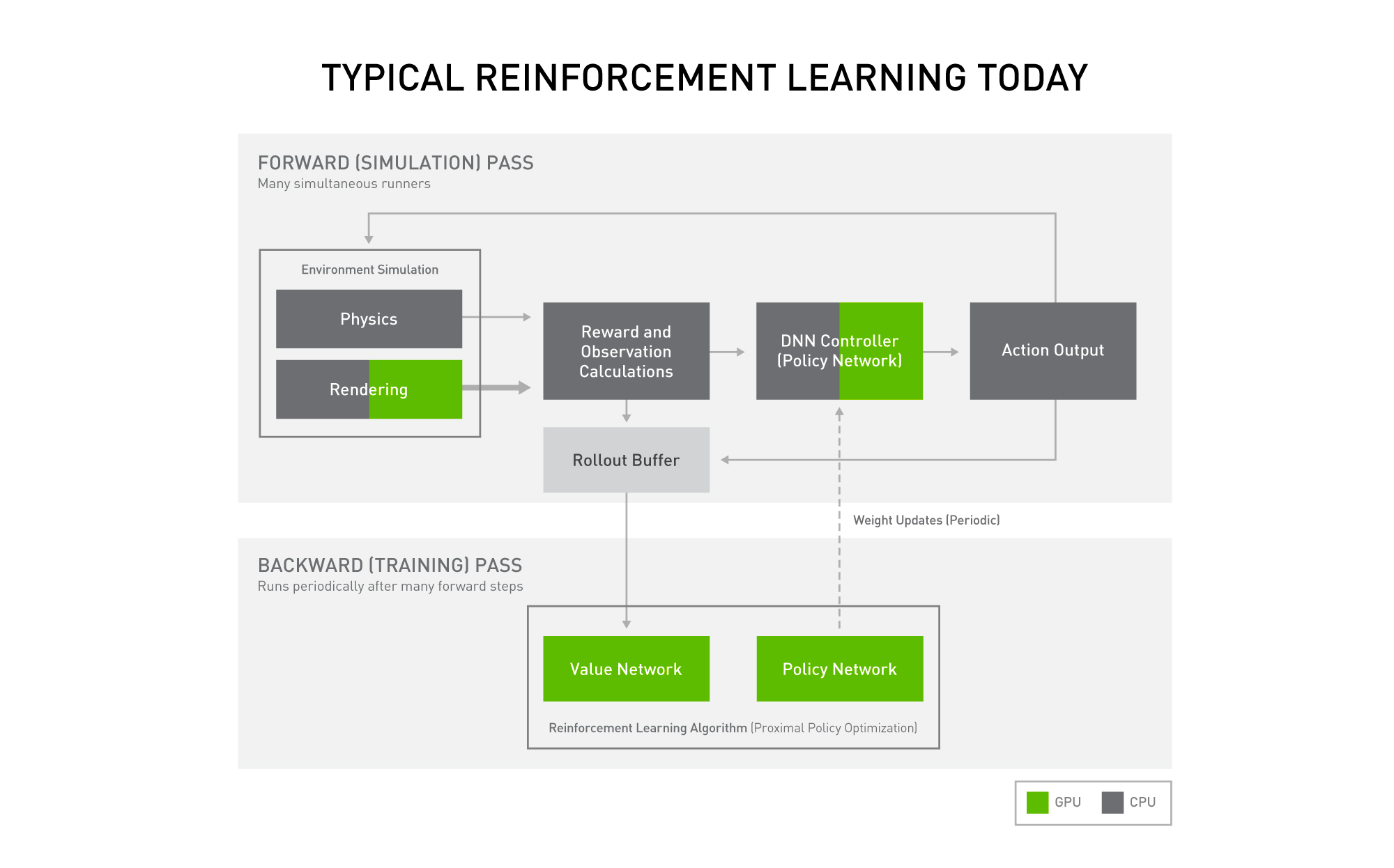 従来の深層強化学習では、CPU と GPU のコンピューティング リソースを組み合わせて使用するため、大量のデータ転送が必要です。
従来の深層強化学習では、CPU と GPU のコンピューティング リソースを組み合わせて使用するため、大量のデータ転送が必要です。強化学習のトレーニングでは、フォワード パスとよばれる処理を行うことが重要です。フォワード パスではまず、システムが環境をシミュレートし、世界の状態に関する一連の観察結果を記録し、どれだけエージェントが成功できたかと、その成功に対する報酬を計算します。
記録された観察結果はディープラーニングの「ポリシー」ネットワークへ入力され、エージェントが実行するアクションはそこで選択されます。観察結果と報酬はどちらも保存され、トレーニング サイクルの後半で使用されます。
最後に、アクションがシミュレーターに戻され、それに応じて環境の残りの部分が更新されます。
こうしたフォワード パスを数回繰り返した後、強化学習モデルは振り返りを行い、選択したアクションが効果的であったかどうかを評価します。この情報は、ポリシー ネットワークの更新に使用され、サイクルはモデルの改善点から再開されます。
Isaac Gym による GPU のアクセラレーション
この強化学習のトレーニング サイクル中に CPU と GPU の間でデータをやり取りするオーバーヘッドをなくすために、NVIDIA の研究者はプロセスのステップをすべて GPU で実行するアプローチを開発しました。それが Isaac Gym です。Isaac Gym は、PhysX シミュレーション エンジンと PyTorch の Tensor 型 API を含むエンドツーエンドのトレーニング環境です。
Isaac Gym を使用すると、開発者は 1 つの GPU で数万の環境を同時に運用できます。つまり、以前は数千の CPU コアを備えたデータ センターが必要だった実験を、場合によっては単一のワークステーションでトレーニングできるのです。
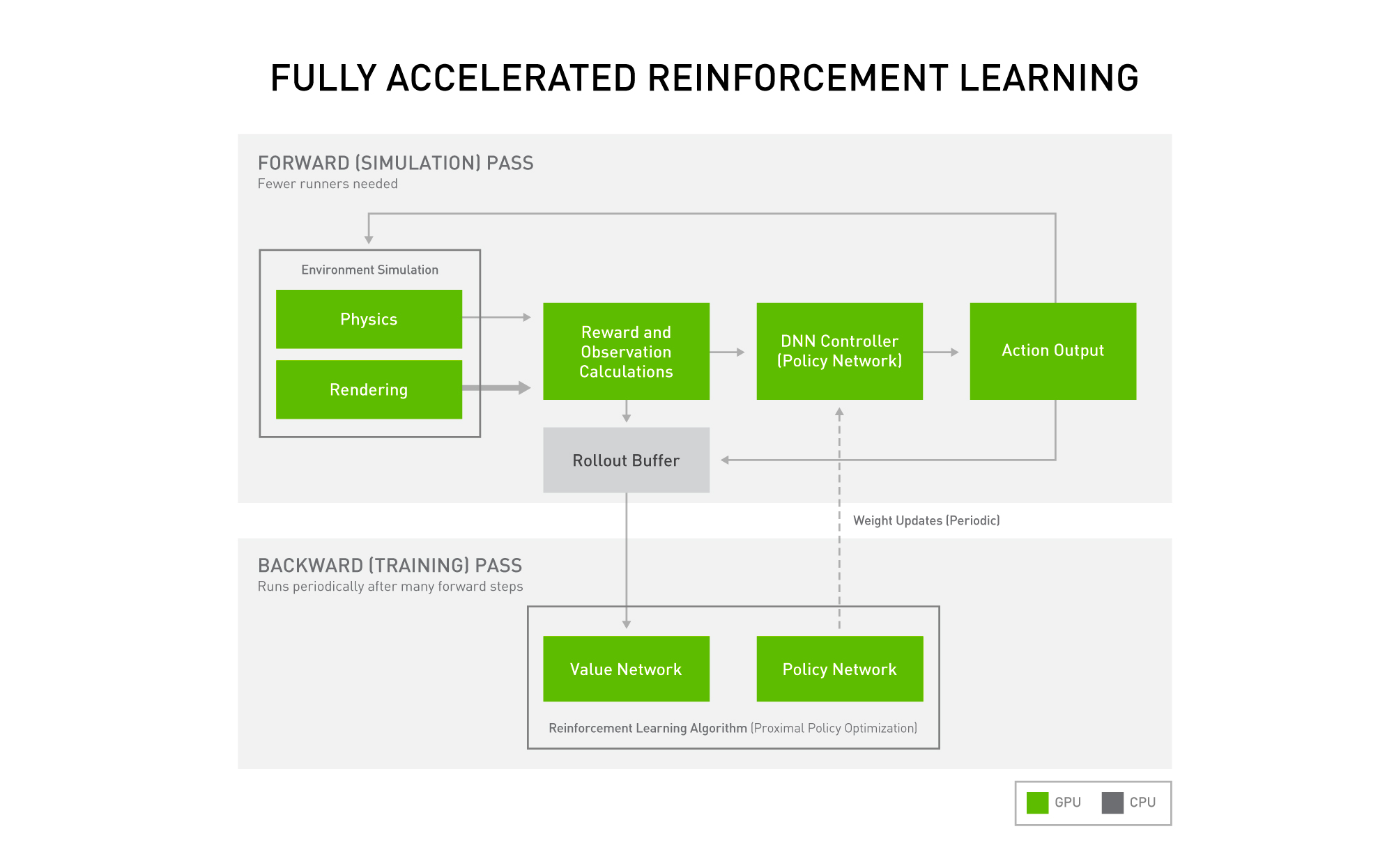 NVIDIA Isaac Gym は、GPU で強化学習のパイプライン全体を実行し、大幅なスピードアップを実現します。
NVIDIA Isaac Gym は、GPU で強化学習のパイプライン全体を実行し、大幅なスピードアップを実現します。必要なハードウェアの量が減ると、大規模なデータ センター リソースにアクセスできない個人研究者でも強化学習を利用しやすくなります。また、プロセスを大幅に高速化することもできます。
ヒューマノイド ロボットを歩行させるといった簡単な強化学習モデルは、Isaac Gym を使用すればわずか数分でトレーニングできます。ただし、エンドツーエンドによる GPU のアクセラレーションが実現したことで、複雑なロボット ハンドにキューブを持たせて特定の位置に置く操作を教えるといった、より難しいタスクにこそ最大限に効果を発揮します。
この問題を解決するには、ロボットがかなり器用でなければならず、ドメインのランダム化を用いたシミュレーション環境が必要です。ドメインのランダム化とは、学習したポリシーを実際のロボットにより簡単に転送できるようにする技術です。
OpenAI による調査によると、このタスクへの取り組みのために、6,000 を超える CPU コアと複数のNVIDIA Tensor コア GPU から成るクラスターを使用し、このタスクを 20 回続けて成功させるために、フィードフォワード ネットワーク モデルを使用した強化学習モデルのトレーニングを約 30 時間必要としました。
Isaac Gym でなら NVIDIA A100 GPU をたった 1 基使用するだけで、NVIDIA の開発者は約 10 時間で同レベルの成功を達成できました。つまり、前述のクラスター全体と比較して、1 基の GPU の性能の方が 3 倍上回っているということになります。
Isaac Gym の詳細については、developer news centerをご覧ください。
上にある動画で紹介しているキューブを操作するタスクでは、Isaac Gym を使用して 1 台の NVIDIA A100 GPU 上でトレーニングを行い、 NVIDIA Omniverseでレンダリングしています。