
どの分野であれ、専門医になる上で重要なのは「経験」です。
症状をどう解釈するか、重篤な状況下で次の一手をどう打つか、どのような治療を施すか――これらの判断がつくかどうかは、ひとえにそれまでに積み重ねてきた訓練と、それをどれだけ実践に活かす機会があったかで決まります。
AI アルゴリズムの場合、「経験」とは「大規模で、多様性に富んだ、上質のデータセット」だと言い換えることができます。しかし、そのようなデータセットを手に入れることは、とりわけ医療分野では、これまで困難とされてきました。
医療機関は独自のデータ ソースに頼る必要がありましたが、それには患者の人口統計や、使用している機器、専門分野によって偏りが生じてしまう可能性があります。でなければ、必要とするすべての情報を集めるために他の機関から得たデータをプールする必要がありました。
しかし、フェデレーテッド ラーニング (Federated Learning) なら、AI アルゴリズムがさまざまな場所に存在する幅広いデータから経験を得ることができるようにすることが可能です。
このアプローチでは、互いに機密性の高い臨床データを直接共有せずに複数の組織が共同でモデルを開発することができます。
幾度かトレーニングを繰り返すうちに、共有モデルは 1 つの機関が内部で保有するデータよりもはるかに幅広いデータにさらされます。
フェデレーテッド ラーニングのしくみ
医療シナリオに導入される AI アルゴリズムは、最終的には、臨床に耐えられるほどの精度に到達していなければなりません。大まかに言えば、その AI アルゴリズムが利用される応用分野のゴールド スタンダードと同じか、それ以上のものに達成していなければならないということです。
特定の医療分野で専門医として認められるには、一般的に 15 年の現場経験が必要とされます。おそらくそのような専門医が目にする症例数は、年間およそ 1 万 5,000 件、キャリア全体にしておよそ 22 万 5,000 件になります。
それが、約 2,000 人に 1 人の割合で発症するような珍しい疾患ともなれば、30 年の経験を持つ専門医でさえ、特定条件の症例を目にする機会はせいぜい 100 件ある程度でしょう。
専門医と同等の水準を満たすモデルをトレーニングするには、AI アルゴリズムに大量の症例を入力する必要があります。さらにそれらの症例は、モデルが実際に利用される臨床環境を十分に表すものでなければなりません。
しかし、現時点で最大のオープン データセットに含まれている症例の数は 10 万件です。
しかも重要なのはデータセットの数ばかりではありません。その多様性も重要で、性別、年齢、人口統計、周囲環境の異なる患者から得たサンプルを取り込む必要があります。
たとえ個々の医療機関が何十万件もの記録や画像が含まれたアーカイブを保有していたとしても、それらのデータ ソースはサイロ化された状態で保管されていることが一般的です。その主な理由としては、医療データが個人情報であり、必要な患者の同意と倫理的承認がなければ使用することができないという点が挙げられます。
フェデレーテッド ラーニングは、データを一か所に保管する必要性をなくすことで、ディープラーニングを分散化する手法です。代わりに、モデルのトレーニングがさまざまな場所で繰り返し行われます。
たとえば、3 つの病院がチームを組み、脳腫瘍の画像を自動的に分析するためのモデルを開発することにしたとしましょう。
クライアントとサーバー間でフェデレーションを構成するアプローチをとると、集中型サーバーが全体的なディープ ニューラルネットワークを管理し、参加している病院には、それぞれ各自のデータセットでトレーニングを行うためのコピーが渡されることになります。
ローカルでモデルのトレーニングを数回繰り返したら、参加病院は最新バージョンのモデルを集中型サーバーに送り返すとともに、それぞれのデータセットを各自の安全なインフラストラクチャ内に保存します。
集中型サーバーは、全参加病院から受け取ったモデルを集約します。その後、最新のパラメーターが参加病院と共有されるので、各病院はローカルでのトレーニングを続けることができます。
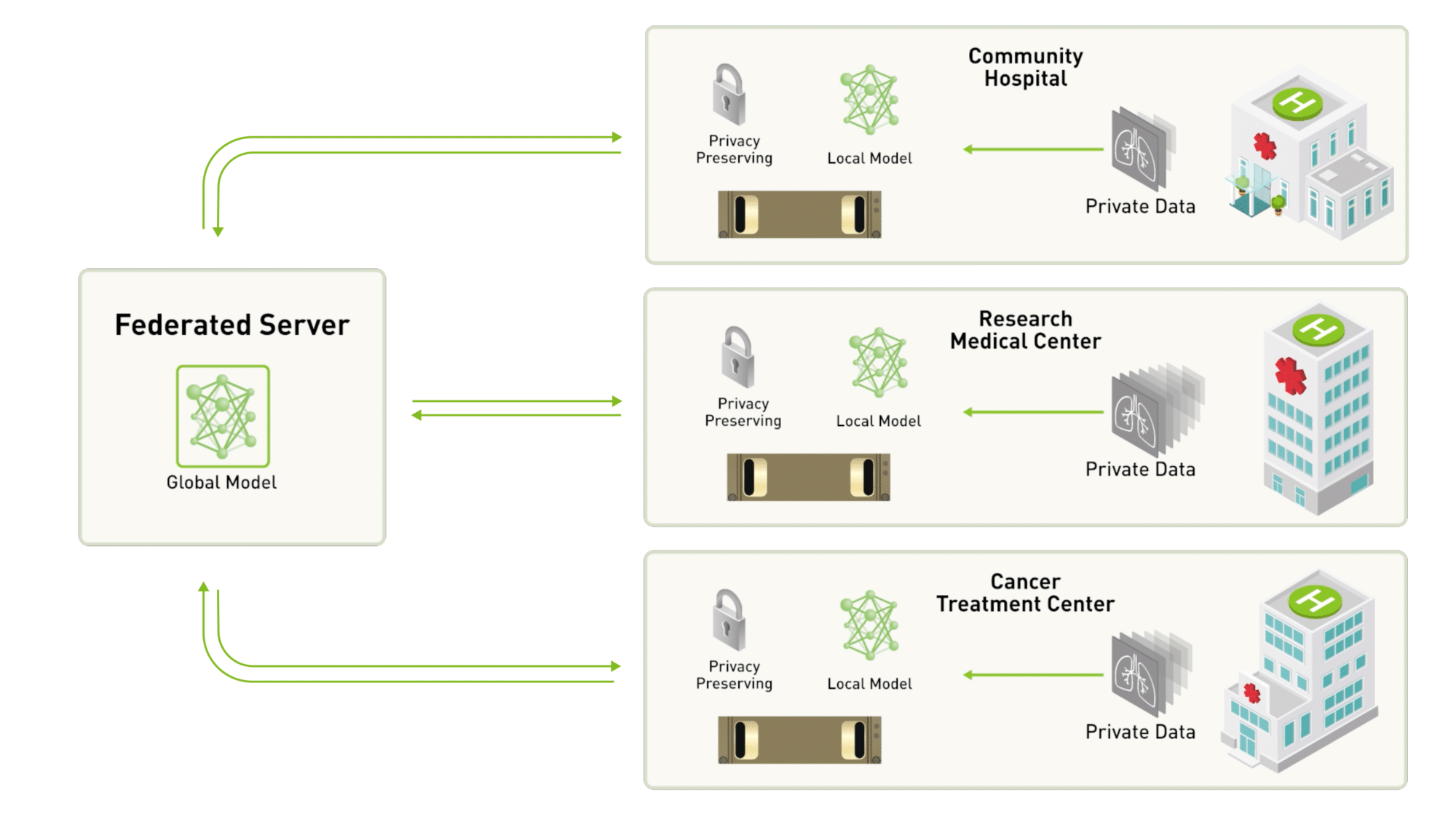 フェデレーテッド ラーニングの集中型サーバー アプローチ
フェデレーテッド ラーニングの集中型サーバー アプローチいずれかの病院がトレーニング チームから外れることになった場合でも、特定のデータに依存していないため、モデルのトレーニングが中断されることはありません。同様に、いつでも新しい病院がトレーニングに参加することができます。
これはフェデレーテッド ラーニングの数あるアプローチの 1 つに過ぎません。すべてのアプローチに共通するのは、参加している全ての医療機関ローカル データから全体的な知識を得ることができる、つまり、全員が勝者となるという点です。
フェデレーテッド ラーニングを選ぶ理由
フェデレーテッド ラーニングはまだ、患者データの安全性を確保するために、依然として導入に慎重になる必要があります。しかし、機密性の高い臨床データのプールを必要とするアプローチの課題のいくつかに対処できる可能性があります。
フェデレーテッド ラーニングの場合、臨床データを医療機関の独自のセキュリティ対策の外に持ち出す必要がありません。各医療機関がそれぞれの臨床データを引き続き管理します。
これにより患者の機密情報を取り出すことが難しくなるため、フェデレーテッド ラーニングは、AI アルゴリズムのトレーニング用により大規模で多様性に富んだデータセットを構築できる可能性をチームにもたらします。
また、フェデレーテッド ラーニングのアプローチを取り入れることで、さまざまな病院、医療機関、研究センターが全員に恩恵をもたらすモデルを共同で構築する活動も促進されます。
フェデレーテッド ラーニングがいかに医療改革に役立つか
フェデレーテッド ラーニングには、AI モデルのトレーニング方法を大きく変える可能性があります。そしてその恩恵は、より広範な医療エコシステムへと広がることが期待されます。
大規模な病院ネットワークがより効果的に連携し合い、機関を越えた安全なデータにアクセスできる恩恵を受けることができると同時に、小規模なコミュニティや地方の病院も専門医レベルの AI アルゴリズムにアクセスできるようになるはずです。
こうして AI が医療現場に持ち込まれることで、臨床データのローカル ガバナンスを守りながらも、さまざまな組織の多様性に富んだ大量のデータをモデル開発に取り入れることが可能になるでしょう。
臨床医は、特定の臨床領域の患者や、身近で遭遇することのない珍しい症例の患者について、幅広い人口統計を示すデータに基づく、より優れた AI アルゴリズムにアクセスできるようになります。その上、結果に不満があれば、いつでもそれらのあるアルゴリズムの継続的なトレーニングに再び寄与することも可能です。
医療系スタートアップは、より幅広いアルゴリズムから学ぶ安全なアプローチのおかげで、最先端イノベーションをより早くの市場にもたらすことができます。
一方、研究機関は、オープン データセットの限られたデータではなく、多岐にわたる実環境データに基づいて、臨床における実際のニーズに向けて取り組みを進めることができるようになるでしょう。
医療による医療のための開発
現在、創薬の向上と AI の恩恵を医療現場にもたらすことを目指して、大規模なフェデレーテッド ラーニングのプロジェクトが次々と生まれています。
たとえば、英国に拠点を置く創薬コンソーシアム MELLODDY は、フェデレーテッド ラーニングの手法が「データの機密性を損なうことなく、世界最大の薬剤化合物に関する共同データセットを AI のトレーニングに利用できるようにする」という両方の長所を製薬パートナーにもたらす理由を実証すべく取り組んでいます。
また、キングス カレッジ ロンドンは、「London Medical Imaging and Artificial Intelligence Centre for Value-Based Healthcare」の活動の一環であるフェデレーテッド ラーニングを用いた独自の取り組みを、脳卒中による障害と神経障害の分類や、がんの根本原因の特定、患者に対する最善の治療法の提案におけるブレイクスルーにつなげたいと考えています。
詳細についてはフェデレーテッド ラーニングをご覧ください。