NVIDIA Blackwell プラットフォームは、Baseten、DeepInfra、Fireworks AI、Together AI などの主要な推論プロバイダーに広く採用されており、トークンあたりのコストを最大 10 分の 1 に削減しています。そして今、NVIDIA Blackwell Ultra プラットフォームはこの勢いをエージェント型 AI にもたらしています。
AI エージェントとコーディング アシスタントは、ソフトウェア プログラミング関連の AI クエリの爆発的な成長を促進しており、OpenRouter の State of Inference レポートによると、その成長率は昨年 11% から 約 50% に伸びています。これらのアプリケーションでは、マルチステップのワークフロー全体にわたってリアルタイムの応答性を維持するための低レイテンシと、コードベース全体にわたりリーズニングする際のロング コンテキストが要求されます。
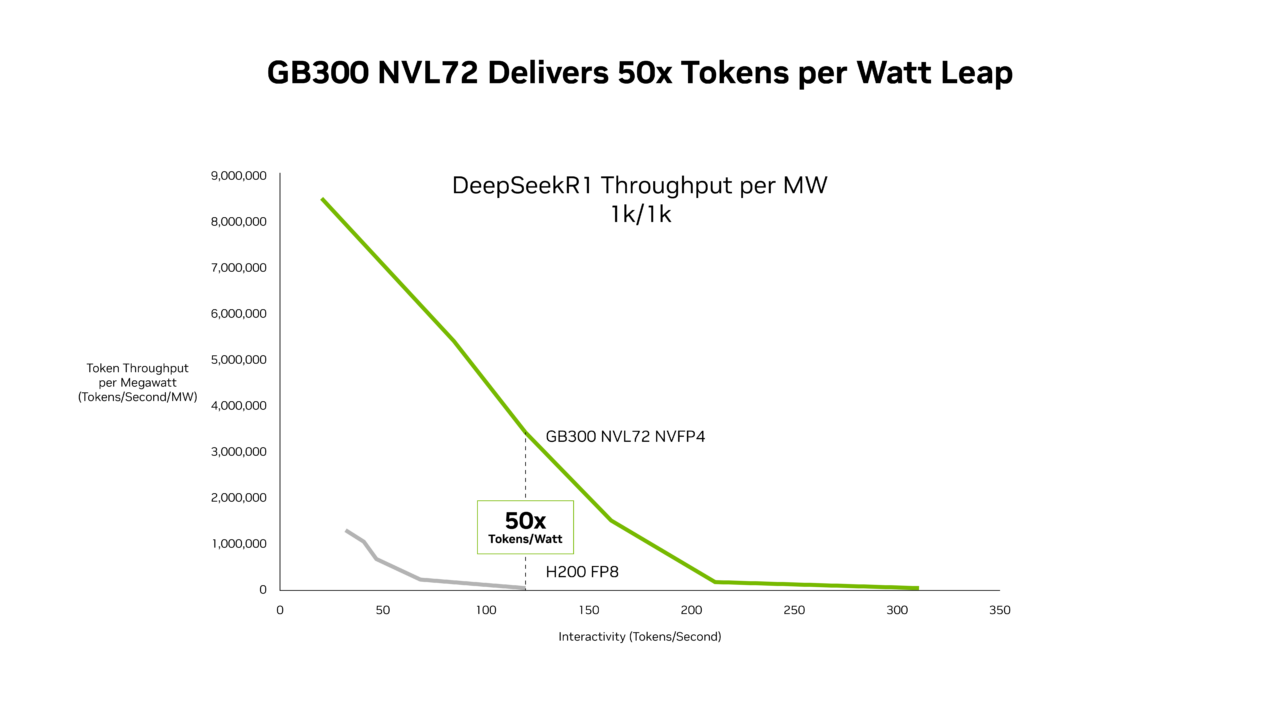
SemiAnalysis InferenceX の最新パフォーマンス データによると、NVIDIA のソフトウェア最適化と次世代 NVIDIA Blackwell Ultra プラットフォームの組み合わせは、その両面において画期的な進歩をもたらしています。NVIDIA GB300 NVL72 システムは、NVIDIA Hopper プラットフォームと比較して、メガワットあたりのスループットが最大 50 倍向上しており、その結果、トークンあたりのコストを 35 分の 1 に削減します。
NVIDIA の緊密な協調設計は、チップ、システム アーキテクチャ、ソフトウェア全体にわたるイノベーションにより、エージェント型コーディングからインタラクティブ コーディング アシスタントまでの AI ワークロード全体のパフォーマンスの高速化と同時に、大幅なコスト削減を実現します。

GB300 NVL72 は低レイテンシ ワークロードで最大 50 倍のパフォーマンス向上を実現
Signal65 の最近の分析によると、NVIDIA GB200 NVL72 はハードウェアとソフトウェアの緊密な協調設計により、NVIDIA Hopper プラットフォームと比較して、ワットあたりのトークン数が 10 倍以上増加しており、その結果、トークンあたりのコストを 10 分の 1 に削減します。この大幅なパフォーマンス向上は、基盤となるスタックが改良されるにつれて、さらに拡大し続けています。
Mixture of Experts (MoE) 推論における Blackwell NVL72 のスループットは、NVIDIA TensorRT-LLM、NVIDIA Dynamo、Mooncake、および SGLang チームによる継続的な最適化により、すべてのレイテンシ目標にわたって大幅に向上し続けています。たとえば、低レイテンシ ワークロードにおける GB200 のパフォーマンスは、NVIDIA TensorRT-LLM ライブラリの改良により、わずか 4 か月前と比較して最大 5 倍向上しています。
- GPU カーネルのパフォーマンス向上:効率と低レイテンシへの最適化により、Blackwell の膨大なコンピューティング能力の最大活用とスループットの向上に貢献します。
- NVIDIA NVLink 対称メモリ:GPU 間の直接メモリ アクセスを可能にし、通信を効率化します。
- PDL (Programmatic Dependent Launch):前のカーネルのセットアップ フェーズが完了する前に次のカーネルのセットアップ フェーズを開始することで、アイドル時間を最小限に抑えます。
Blackwell Ultra GPU を搭載した GB300 NVL72 は、これらのソフトウェアの進歩をもとに、Hopper プラットフォームと比較して、メガワットあたりのスループットの限界を 50 倍に押し上げています。
このパフォーマンス向上は優れた経済性にもつながり、NVIDIA GB300 はすべてのレイテンシ範囲において、Hopper プラットフォームに比べて低コストです。最も大きな削減効果が得られるのは、エージェント型アプリケーションが動作する低レイテンシ時で、Hopper プラットフォームと比較して 100 万トークンあたりのコストを最大 35 分の 1 に削減します。
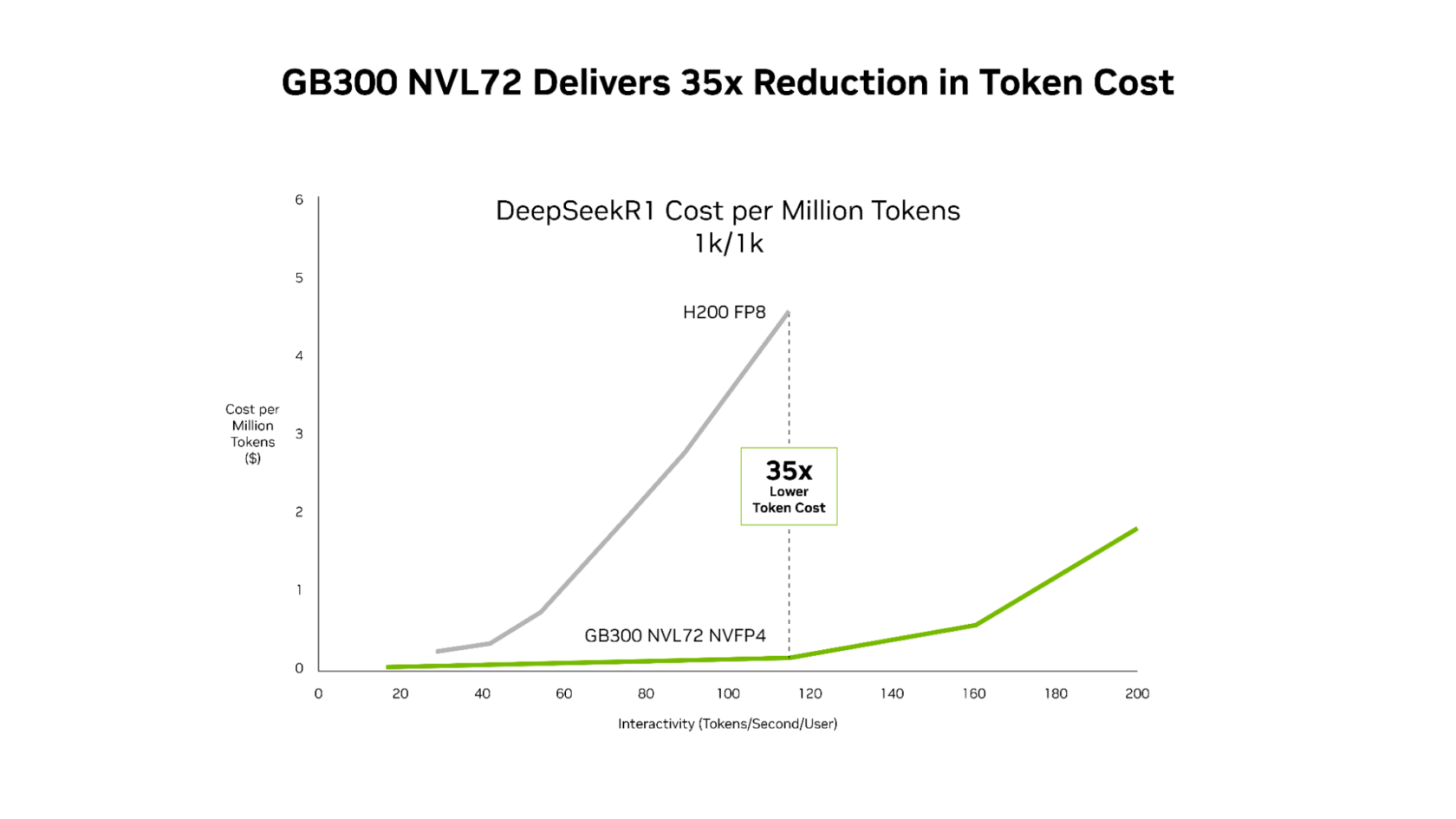
この徹底的なソフトウェア最適化と次世代ハードウェアの組み合わせにより、AI プラットフォームは、マルチステップのワークフロー全体で 1 ミリ秒単位の積み重ねが重要となるエージェント型コーディングやインタラクティブ アシスタントのワークロードにおいて、より多くのユーザーにリアルタイムのインタラクティブな体験を提供できるようになります。
GB300 NVL72 はロング コンテキスト ワークロードで優れた経済性を発揮
GB200 NVL72 と GB300 NVL72 はどちらも超低レイテンシを効率的に実現しますが、ロング コンテキストのシナリオでは GB300 NVL72 のメリットが最も明確に現れます。入力が 128,000 トークン、出力が 8,000 トークンのワークロード (コードベースを横断してリーズニングを行う AI コーディング アシスタントなど) の場合、GB300 NVL72 は GB200 NVL72 と比較してトークンあたりのコストを最大 1.5 分の 1 に削減します。
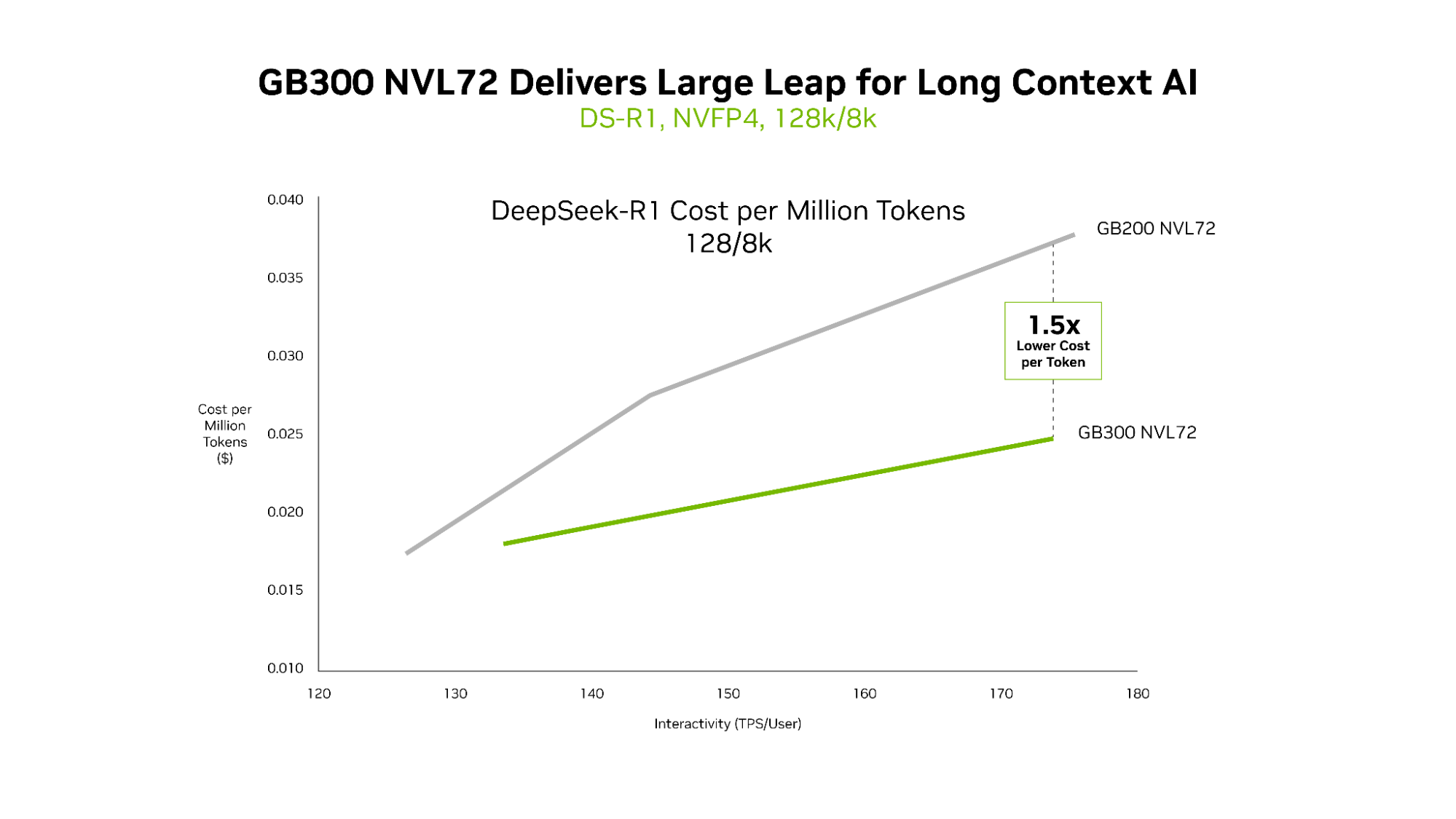
エージェントがコードを読み込むにつれて、コンテキストは増大します。その結果、エージェントはコードベースをより深く理解できるようになりますが、それと同時により多くの計算が必要になります。Blackwell Ultra は、1.5 倍の NVFP4 コンピューティング性能と 2 倍のアテンション処理速度を実現しており、エージェントがコードベース全体を効率的に理解することを可能にします。
エージェント型 AI のためのインフラ
主要なクラウド プロバイダーや AI イノベーターは、すでに NVIDIA GB200 NVL72 を大規模に導入しており、さらに GB300 NVL72 の本番導入も進めています。Microsoft、CoreWeave、OCI は、エージェント型コーディングやコーディング アシスタントといった低レイテンシかつロング コンテキストのユース ケース向けに GB300 NVL72 を導入しています。GB300 NVL72 は、トークン コストの削減により、大規模コードベースのリアルタイム リーズニングが可能な新しい種類のアプリケーションを実現します。
CoreWeave のエンジニアリング担当シニア バイス プレジデントである Chen Goldberg 氏は、次のように述べています。「推論が AI 構築の中心となるにつれて、ロング コンテキスト性能とトークン効率が重要になっています。Grace Blackwell NVL72 はこの課題に直接対処します。CKS や SUNK などの CoreWeave の AI クラウドは、GB200 の成功を基盤として、GB300 システムのメリットから予測可能な性能とコスト効率を生み出すように設計されています。その結果、大規模ワークロードを実行するお客様にとって、トークン経済性と推論の有用性の向上につながります」
次世代のパフォーマンスをもたらす NVIDIA Vera Rubin NVL72
NVIDIA Blackwell システムを大規模に導入し、ソフトウェアを継続的に最適化することで、インストール ベース全体にわたってパフォーマンス向上とコスト削減を図り続けることができます。
今後、6 つの新チップを組み合わせて 1 つの AI スーパーコンピューターを形成する NVIDIA Rubin プラットフォームが、さらなる飛躍的なパフォーマンス向上を実現することになります。MoE 推論では、Blackwell と比較してメガワットあたりのスループットが最大 10 倍向上し、100 万トークンあたりのコストは 10 分の 1 に削減されます。さらに、Rubin は Blackwell と比較してわずか 4 分の 1 の GPU 数で大規模 MoE モデルをトレーニングでき、最先端 AI モデルの新たな波を生み出します。
NVIDIA Rubin プラットフォームおよび Vera Rubin NVL72 システムの詳細をご覧ください。