 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
NVIDIA H100 Tensor コア GPU は、前例のないスケーリングとソフトウェアの進歩により、最新の業界標準テストで新記録を樹立
NVIDIA の AI プラットフォームは、最新の MLPerf 業界ベンチマークにおいて、AI トレーニングとハイ パフォーマンス コンピューティングの水準を引き上げました。
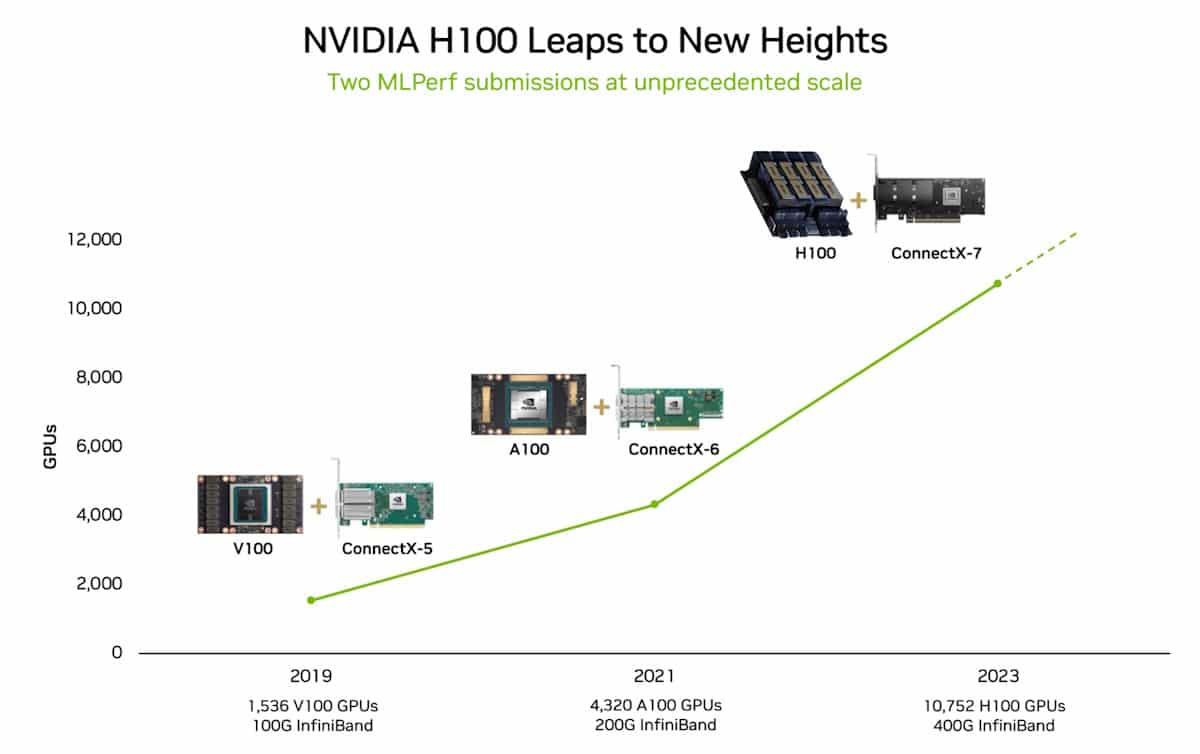
数多くの新記録やマイルストーンの中で、生成 AI における ひとつの結果が際立っています。10,752 基の NVIDIA H100 Tensor コア GPU と NVIDIA Quantum-2 InfiniBand ネットワーキングを搭載した AI スーパーコンピューターである NVIDIA Eos は、1,750 億のパラメーターを持つ GPT-3 モデルを10 億のトークンでトレーニングするベンチマークを、わずか 3.9 分で完了しました。
これは、わずか 6 ヶ月前にこのテストが導入されたときに NVIDIA が記録した 10.9 分から、3 倍近くも高速化したことになります。
このベンチマークでは、人気の高い ChatGPT サービスを支える完全な GPT-3 データセットの一部を使用しています。外挿すると、Eos では完全なデータセットをわずか 8 日でトレーニングを行うことができ、これは 512 基の A100 GPU を使用する以前の最先端のシステムよりも 73 倍高速です。
トレーニング時間の短縮は、コストを削減し、エネルギーを節約し、市場投入までの時間を短縮します。これは、LLM をカスタマイズするためのフレームワークである NVIDIA NeMo のようなツールを使って、あらゆるビジネスが大規模言語モデルを採用できるようにするための重要な要件です。
今回の新しい生成 AI テストでは、1,024 基の NVIDIA Hopper アーキテクチャ GPU が、Stable Diffusion Text-to-Image モデルに基づくトレーニング ベンチマークを 2.5 分で完了し、この新しいワークロードに高いハードルを設定しました。
生成 AI は私たちの時代の最も変革的なテクノロジであるため、MLPerf は、この 2 つのテストを採用することで、AI のパフォーマンスを測定する業界標準としてのリーダーシップを強化しました。
システムのスケーリングが急拡大
最新の結果は、MLPerf ベンチマークにこれまでで最も多くのアクセラレーターを使用したことにもよります。10,752 基の H100 GPU は、NVIDIA が 3,584 基の Hopper GPU を使用した 6 月の AI トレーニングにおけるスケーリングをはるかに上回りました。
GPU の数が 3 倍になったことで、パフォーマンスは 2.8 倍に向上し、ソフトウェアの最適化もあり 93% の効率を実現しました。
LLM は毎年 1 桁ずつ成長しているため、効率的なスケーリングは生成 AI における重要な要件です。最新の結果は、世界最大のデータセンターであっても、前例のない課題に対応できる NVIDIA の能力を示しています。
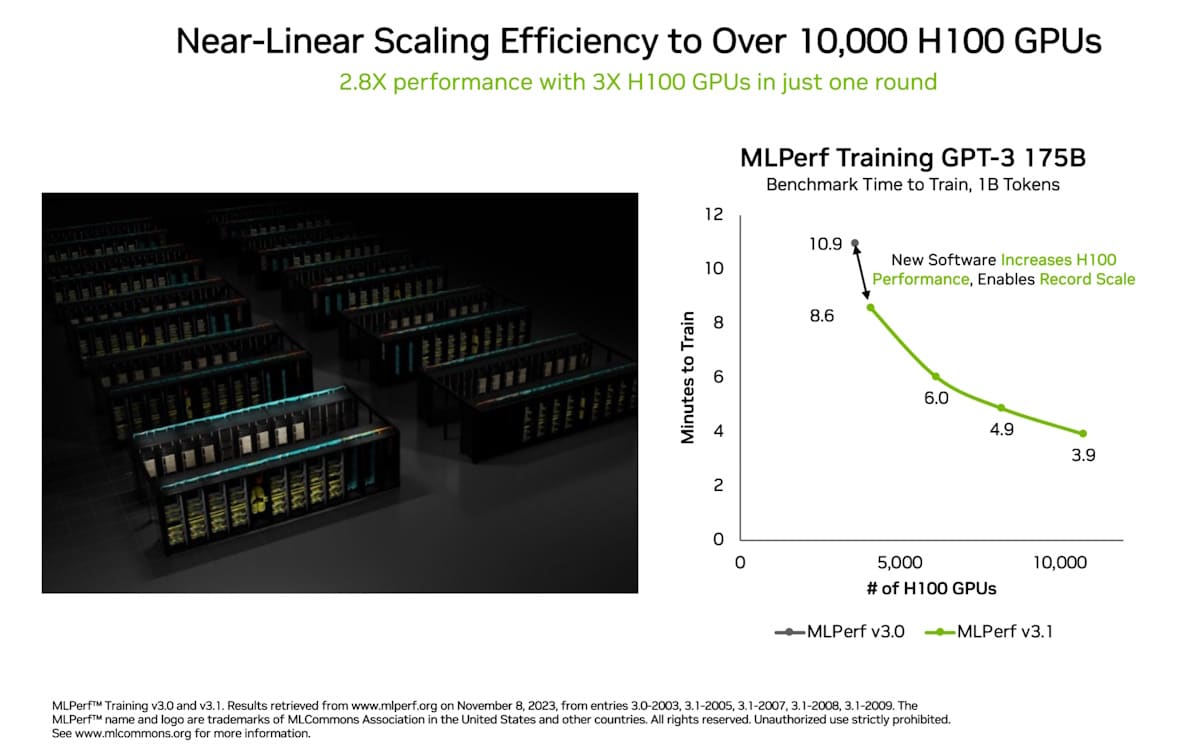
この成果は、Eos と Microsoft Azure が今回のラウンドで使用したアクセラレーター、システム、ソフトウェアの革新的なフルスタック プラットフォームのおかげです。
Eos と Azure は共に、10,752 個の H100 GPU を採用し、別々の結果を提出しました。どちらも差が 2% 以内の同等の性能を達成し、データセンターとパブリック クラウドの展開における NVIDIA AI の効率性を実証しました。

NVIDIA は、幅広い重要な仕事に Eos を活用しています。最先端のコンピュータ グラフィックス向けの AI 搭載ソフトウェアである NVIDIA DLSS のような取り組みや、次世代 GPU の設計を支援する生成 AI ツールである ChipNeMo のような NVIDIA Research のプロジェクトを推進するのに役立っています。
ワークロードを超えた進歩
NVIDIA は今回のラウンドで、生成 AI の進歩に加え、いくつかの新記録を樹立しました。
例えば、H100 GPU は、レコメンダー モデルのトレーニングにて、前回のラウンドよりも 1.6 倍高速なパフォーマンスを達成しました。レコメンダー モデルは、ユーザーがオンラインで探しているものを見つけるのを助けるために広く利用されていています。また、コンピュータ ビジョン モデルの RetinaNet では、パフォーマンスが 1.8 倍に向上しました。
これらの向上は、ソフトウェアの進歩とハードウェアの拡張の組み合わせによるものです。
NVIDIA は、今回もまた、すべての MLPerf のテストを実施した唯一の企業でした。H100 GPU は、9 つのベンチマークのそれぞれにおいて、最速のパフォーマンスと最大のスケーリングを示しました。

高速化は、巨大な LLM をトレーニングしたり、NeMo のようなフレームワークを使ってビジネスの特定のニーズに合わせてカスタマイズしたりするユーザーにとって、市場投入までの時間の短縮、コストの削減、エネルギーの節約につながります。
ASUS、Dell Technologies、富士通、GIGABYTE、Lenovo、QCT および Supermicro を含む 11 のシステム メーカーが、今回の提出に NVIDIA AI プラットフォームを使用しました。
NVIDIA のパートナーが MLPerf に参加しているのは、AI プラットフォームやベンダーを評価する顧客にとって、MLPerf が貴重なツールであることを理解しているからです。
HPC ベンチマークが拡大
スーパーコンピューター上の AI 支援シミュレーションのための別のベンチマークである MLPerf HPC において、H100 GPU は前回の HPC ラウンドでの NVIDIA A100 Tensor コア GPU の最大 2 倍のパフォーマンスを発揮しました。この結果は、2019 年の最初の MLPerf HPC ラウンドから最大 16 倍の向上を示しています。
このベンチマークには、アミノ酸配列からタンパク質の立体構造を予測するモデルである OpenFold をトレーニングする新しいテストが含まれています。OpenFold は、これまで研究者が数週間から数ヶ月かかっていた、ヘルスケアに不可欠な作業を数分で行うことができます。
タンパク質の構造を理解することは、効果的な薬剤を迅速に見つけるための鍵となります。ほとんどの薬剤は、多くの生物学的プロセスを制御するのに役立つ細胞機構であるタンパク質に作用するためです。
MLPerf HPC のテストでは、H100 GPU が OpenFold を 7.5 分でトレーニングしました。OpenFold テストは、2 年前に 128 基のアクセラレータを使用して 11 日間かかった AlphaFold トレーニング プロセス全体の代表的な部分です。
NVIDIA がトレーニングに使用した OpenFold モデルのバージョンとソフトウェアは、創薬のための生成 AI プラットフォームである NVIDIA BioNeMo で間もなく利用可能になります。
今回のラウンドでは、複数のパートナーが NVIDIA AI プラットフォームで提出を行いました。その中には、Dell Technologies、クレムソン大学のスーパーコンピューティング センター、テキサス アドバンスト コンピューティング センター、そして Hewlett Packard Enterprise (HPE) の支援を受けたローレンス バークレー国立研究所も含まれています。
幅広い支持を得るベンチマーク
2018 年 5 月の開始以来、MLPerf ベンチマークは産業界と学界の両方から幅広い支持を得ています。MLPerf ベンチマークをサポートしている組織には、Amazon、Arm、Baidu、Google、ハーバード大学、HPE、Intel、Lenovo、Meta、Microsoft、NVIDIA、スタンフォード大学、トロント大学などが含まれます。
MLPerf のテストは透明性が高く客観的であるため、ユーザーは十分な情報に基づいた購買決定を行うことができます。
NVIDIA が使用したソフトウェアはすべて MLPerf リポジトリから入手できるため、すべての開発者が同じワールドクラスの結果を得ることができます。これらのソフトウェアの最適化は、GPU アプリケーション用の NVIDIA のソフトウェア ハブである NGC で利用可能なコンテナーに継続的に組み込まれます。
MLPerf と今回のラウンドの詳細についてはこちらをご覧ください。







