
NVIDIA は、科学と産業の進歩を促すアプローチである、ハイパフォーマンス コンピューティングにおける AI に重点を置いた新たな業界指標の 5 項目中 4 項目でトップを獲得
MLPerf HPCは、ハイパフォーマンス コンピューティング分野の科学アプリケーションにおける AI パフォーマンスの業界ベンチマークです。MLPerf HPC 1.0 のテスト 5 項目中 4 項目で、NVIDIAのテクノロジを搭載したシステムがトップを獲得しました。
これは、2018 年 5 月に初公開されたディープラーニングの業界ベンチマークである MLPerf の最新ラウンドの結果です。MLPerf HPC は、スーパーコンピューター上でのシミュレーションを AI によって高速化、強化するスタイルのコンピューティングに対応しています。
分子動力学、天文学、気候シミュレーションにおける最近の進歩は、いずれも HPC と AI を利用して科学的ブレイクスルーを達成したものです。そうした流れから、科学界と産業界のユーザーの間ではエクサスケール AI を導入する動きが広がっています。
ベンチマークの測定対象
MLPerf HPC 1.0 では、HPC センターにおいて一般的な次の 3 種類のワークロードに関する AI モデルのトレーニングを測定しました。
- CosmoFlow:望遠鏡から得られた画像内の物体の詳細を推定します。
- DeepCAM:気候データからの台風や大気の川の検出をテストします。
- OpenCatalyst:分子中の原子間に働く力をどの程度正確に予測できるかを追跡します。
各テストは 2 つの部分で構成されています。1 つはシステムがモデルをトレーニングする速度を測定するもので、強スケーリングと呼ばれます。もう 1 つは弱スケーリングと呼ばれ、システムの最大スループット、つまり所定の時間内にトレーニング可能なモデルの数を測定するものです。
昨年の MLPerf 0.7で記録された強スケーリングのトップ スコアと比較して、NVIDIA は CosmoFlow で 5 倍、DeepCAM では約 7 倍のパフォーマンスを達成しました。
OpenCatalyst ベンチマークの強スケーリングでは、米国ローレンス バークレー国立研究所の Perlmutter Phase 1 システムが、6,144 基の NVIDIA A100 Tensor コア GPU のうちの 512 基を使用してトップ スコアを記録しました。
弱スケーリング カテゴリでは、NVIDIA が DeepCAM で 1 ジョブ当たり 16 ノード、256 ジョブを同時に実行してトップを獲得しました。すべてのテストは、NVIDIA の社内システムであり、世界最大規模の産業用スーパーコンピューターである NVIDIA Selene (ブログトップの画像) で行いました。
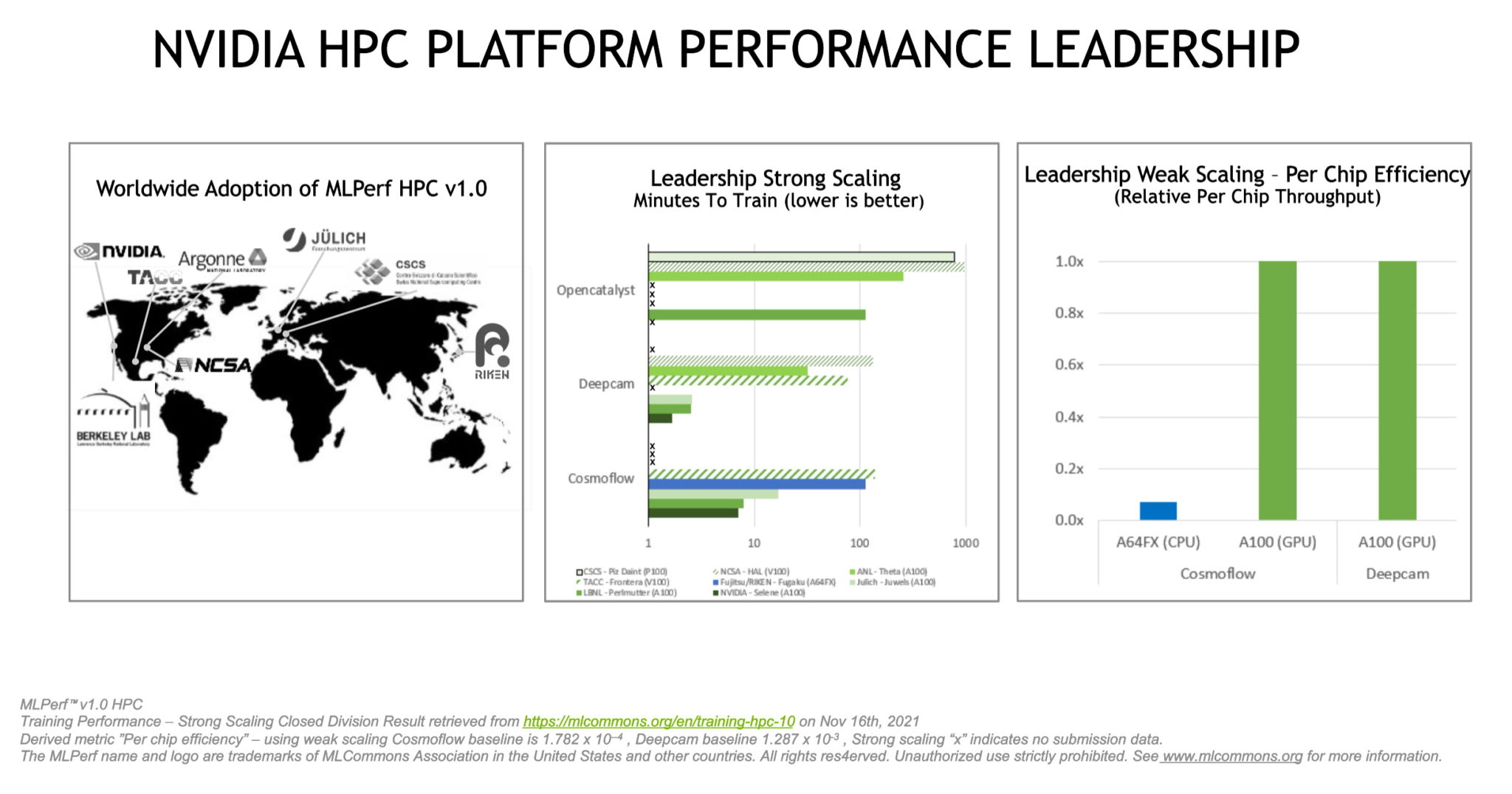 NVIDIA は、モデルのトレーニング速度とチップ当たりの効率の両方でトップ スコアを記録しました。
NVIDIA は、モデルのトレーニング速度とチップ当たりの効率の両方でトップ スコアを記録しました。この最新結果は、NVIDIA AI プラットフォームとそのパフォーマンス リーダーシップの新たな次元を示すものです。NVIDIA がデータセンター、クラウド、ネットワークのエッジにおける AI トレーニングと推論にわたる MLPerf ベンチマークでトップ スコアを記録したのは、今回で 8 回連続となります。
広範なエコシステム
今回のラウンドに参加した 8 機関のうち、7 機関が NVIDIA GPU を活用した結果を提出しました。
その中には、ドイツのユーリッヒ スーパーコンピューティング センター、スイス国立スーパーコンピューティング センター、米国のアルゴンヌ国立研究所、ローレンス バークレー国立研究所、国立スーパーコンピューター応用研究所、およびテキサス アドバンスト コンピューティング センターが名を連ねています。
ユーリッヒ スーパーコンピューティング センター所長のトーマス リッペルト (Thomas Lippert) 氏は、ブログの中で「ベンチマーク テストは、我々のマシンが潜在能力を実際に発揮できることを示しており、AI 分野におけるヨーロッパの地位確保に貢献できました」と述べています。
MLPerf ベンチマークは、Alibaba、Google、Intel、Meta、NVIDIA やその他の企業が主導する業界団体である MLCommons によって支えられています。
達成方法
今回の結果も、フルスタックのソフトウェアを含む、成熟した NVIDIA AI プラットフォームの成果と言えます。
今回のラウンドでは、NVIDIA は誰でも利用可能なツールを使用してコードをチューニングしています。例えば、データ処理を高速化する NVIDIA DALI や、小規模バッチの遅延を削減して 1,024 基以上の GPU まで効率的なスケールアップを可能にする CUDA Graphs などを使用しました。
また、NVIDIA MagnumIO 内の主要コンポーネントである NVIDIA SHARP も利用しました。それによってネットワーク内コンピューティングを実現し、通信を高速化したり、データ操作を NVIDIA Quantum InfiniBand スイッチにオフロードしたりすることが可能になります。
これらのツールの活用方法の詳細は、開発者向けブログをご覧ください。
NVIDIA が今回の提出に使用したソフトウェアはすべて、MLPerf リポジトリから入手可能です。そうしたコードは、NVIDIA のトレーニング済み AI モデル、業界アプリケーション フレームワーク、GPU アプリケーション、その他のソフトウェア リソースのソフトウェア ハブである NGC カタログに定期的に追加されています。