Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
リアルタイムの自然言語理解によって、インテリジェント マシンやインテリジェント アプリケーションとの関わり方に変革が起こる
人間と機械の間で質の高い会話をするためには、応答は迅速で、インテリジェントで、自然な言い回しでなければなりません。
しかしこれまで、リアルタイム音声アプリケーションを強化する言語処理ニューラルネットワークの開発者は、残念なトレードオフを抱えてきました。それは、応答を迅速にすると質が犠牲になり、インテリジェントに拘ると応答が遅すぎるというものです。
なぜなら、人間の会話は非常に複雑だからです。会話で発する文はすべて、共有する文脈と、そこに至るまでの双方向のやり取りに基づいています。その場でのみ通じるジョークから文化的な言及や言葉遊びまで、人間は止まることなく非常に微妙なニュアンスを持たせた話し方をします。会話の応答は最後まで続き、しかもほぼ瞬時に発話されます。友人同士における会話では、話し相手が言葉を発する前に、相手が何を言うかを予想しています。
対話型 AI とは
真の対話型 AI とは、人間のような会話を行い、文脈を理解し、インテリジェントな応答を提供できる音声アシスタントのことです。このような AI モデルは当然、大規模で非常に複雑です。
ただし、モデルが大きくなるほど、ユーザーの質問と AI の応答の間の遅延が長くなります。会話の切れ目が0.3 秒以上空くだけでも、不自然に聞こえることがあります。
NVIDIA GPU、対話型 AI ソフトウェア、CUDA-X AI ライブラリを使用することで、大規模な最先端の言語モデルを迅速にトレーニングおよび最適化して、わずか数ミリ秒 (ミリ秒 = 1000 分の 1 秒) で推論を実行できます。これは、高速な AI モデルと大規模で複雑な AI モデルの間に存在するトレードオフを解消する大きな進歩です。
これらのブレイクスルーにより、開発者はこれまでで最も高度なニューラルネットワークを構築、展開できるようになるため、真の対話型 AI を実現するという目標に一歩近づくことになります。
GPU に最適化された言語理解モデルは、ヘルスケア、小売、金融サービスなどの業界の AI アプリケーションに統合でき、スマート スピーカーやカスタマー サービスの電話で使用される高度なデジタル音声アシスタントを可能にします。このような高性能の対話型 AI ツールを使用することにより、さまざまな分野の企業が顧客とのやり取りにおいて、これまで達成できなかった水準のパーソナライズされたサービスを提供できるようになります。
対話型 AI に求められる応答の速さ
自然な会話における応答間の切れ目は一般に約 300 ミリ秒です。AI が人間のような双方向のやり取りを再現するには、多層タスクの一部として 12 個以上のニューラルネットワークを順番に、しかも 300 ミリ秒以内に実行しなければならないでしょう。
質問に回答するには、ユーザーの音声をテキストに変換する、テキストの意味を理解する、文脈に合った最適な回答を検索する、Text-to-Speech ツールを使用して音声で回答するなどの手順を踏むことになります。これらの手順それぞれで、複数の AI モデルを実行する必要があります。したがって、個々のネットワークの実行に許される遅延は、約 10 ミリ秒以下になります。
各モデルの実行に時間がかかると、応答が遅くなり、ぎこちなくて不自然な会話になってしまいます。
このようなわずかな遅延しか許されない中で開発が求められる現在の言語理解ツールの開発者は、前述のトレードオフを許容せざるを得なくなります。チャットボットでは高品質で複雑なモデルを使用できます。チャットボットの場合、遅延は音声インターフェイスほど重要ではないからです。一方、開発者はあまり大規模ではない言語処理モデルに頼ることもできますが、より迅速に結果を提供できる代わりに微妙なニュアンスの応答ができません。
NVIDIA Jarvis は開発者向けのアプリケーション フレームワークで、双方向型アプリに求められる 300 ミリ秒のしきい値をはるかに下回る速度で実行できる高精度の対話型 AI アプリケーションを構築できます。企業の開発者は、NVIDIA DGX システム上で 10 万時間以上のトレーニングを経た最先端のモデルを始めから使用することができます。
企業は、Transfer Learning Toolkitを使用して転移学習を適用し、自分たちのカスタム データでこれらのモデルを微調整できます。これらのモデルは、企業独自の専門用語を理解してユーザーの満足度を高めるといった用途に適しています。モデルは、NVIDIA の高性能推論 SDK である TensorRT を使用して最適化され、データセンターで実行および拡張できるサービスとして展開できます。さらに、音声と視覚を一緒に使用して、デバイスとのやり取りをより自然で人間らしいものにするアプリを作成することができます。Jarvis により、以前は AI の専門家だけが試みることしかできなかった世界クラスの対話型 AI テクノロジをあらゆる企業が使用できるようになります。
未来の対話型 AI での音声はどう聞こえるか
電話の通話におけるツリー構造のアルゴリズムなどの基本的な音声インターフェイス (「新しいフライトを予約するには、『予約』と言ってください」などの指示) はトランザクション型であり、事前にプログラムされたキューを介してユーザーを移動する一連の手順と応答が必要です。微妙なニュアンスの質問を理解し、電話の相手からの質問にインテリジェントに回答できるのは、通話のツリー構造の最後にいる人間のエージェントだけの場合もあります。

現在市場に出回っている音声アシスタントは、非常に多くのことを実行していますが、使用しているパラメータは数十億ではなく数百万で、それほど複雑ではない言語モデルに基づいています。これらの AI ツールでは、発話された質問に答える前に「ただ今お調べしております」などの応答をすることにより、会話の流れが途切れることがあります。または、質問への応答を会話で行うのではなく、ウェブの検索結果のリストを表示します。
真の対話型 AI は、ここからさらに飛躍するでしょう。理想的なモデルとしては、銀行の明細書や検診結果のレポートについて個人的な質問を正確に理解できるレベルの複雑さや、シームレスな自然言語でほぼ瞬時に応答できるレベルの迅速さが考えられます。
このテクノロジのアプリケーションには例えば、患者が予約と経過観察用の血液検査をスケジューリングするのを支援する診療所の音声アシスタントや、荷物の出荷が遅れる理由を説明して返品分と同額のストア クレジットを提供できる小売業界での音声 AI などがあるでしょう。
このような高度な対話型 AI ツールの需要が高まっています。2020 年までに検索の 50% が音声で行われていると推定され、2023 年までに 80 億台のデジタル音声アシスタントが使用されるようになると予想されています。
BERT とは
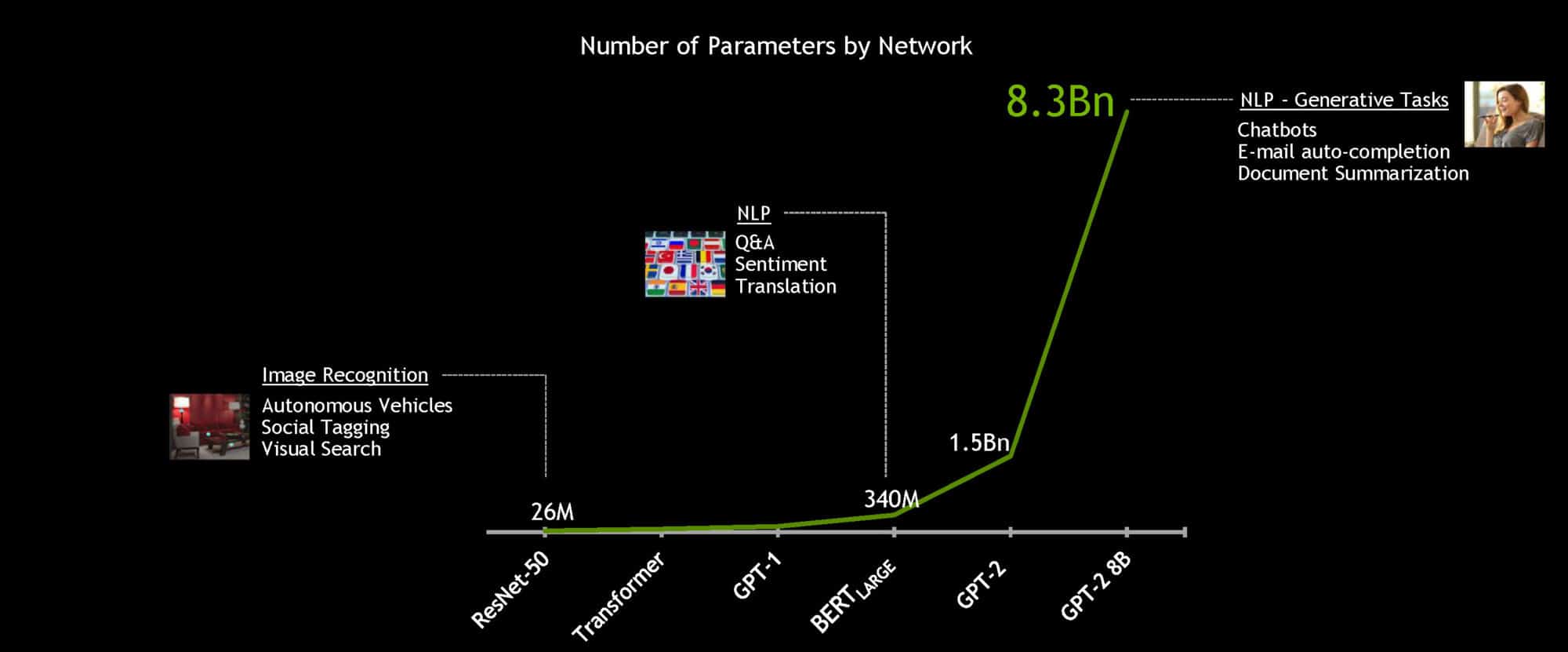
BERT (Bidirectional Encoder Representations from Transformers) は発表された当時、自然言語理解の分野で世界最高精度を達成した大規模な計算量の多いモデルです。微調整をすることで、読解、感情分析、質疑応答といった幅広い言語タスクに適用できます。
33 億語の英語テキストから成る膨大なコーパスを用いてトレーニングされた BERT は、言語の理解に非常に優れており、場合によっては平均的な人間よりも優れています。BERT の強みは、ラベル付けがされていないデータセットでトレーニングでき、最小限の変更で幅広いアプリケーションに一般化できることです。
同じ BERT を使用して複数の言語を理解し、微調整して、翻訳、オート コンプリート、検索結果のランク付けなどの特定のタスクを実行できます。このように汎用性が高いことから、複雑な自然言語理解の開発において広く選ばれるテクノロジとなっています。
BERT の基盤となるTransformer 層は、attention という手法を適用し、リカレント ニューラル ネットワークの代替となっています。attention とは、前後にある最も関連性の高い単語に注意 (attention) を向けることで文を解析する手法です。
例えば、「窓の外に crane があります」という文は、「湖畔にある小屋の」で始まるか「私のオフィスの」で始まるかに応じて、crane が鳥のツルを指すか建設現場のクレーンを指すかが変わってきます。BERT のような言語モデルは、双方向のエンコードまたは無指向のエンコーディングと言われる方法を用いることで文脈の手掛かりを使用でき、どのような場合にどの意味が適用されるかについて優れた理解力を発揮します。
BioBERT (生物医学論文用) や SciBERT (科学出版物用) など、現在の様々な分野の主要な言語処理モデルは BERT をベースとしています。
NVIDIA のテクノロジが Transformer ベースのモデルを最適化する方法
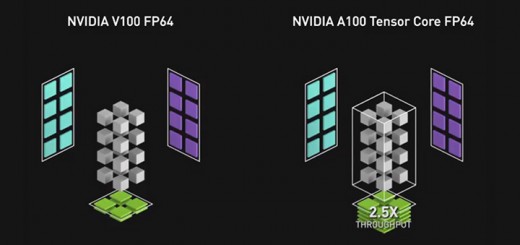
NVIDIA GPU の並列処理機能と Tensor コア アーキテクチャにより、複雑な言語モデルを操作する際のスループットとスケーラビリティが向上し、BERT の学習と推論の両方で記録的な性能が実現します。
強力な NVIDIA DGX SuperPOD システムを使用すると、トレーニング時間に通常は数日かかる 3 億 4000 万パラメータの BERT-Large モデルを 1 時間以内にトレーニングできます。しかし、リアルタイムの対話型 AI の場合、最も重要なスピードアップは推論です。
NVIDIA の開発者は TensorRT ソフトウェアを使用して、1 億 1,000 万パラメータの BERT-Base モデルを推論向けに最適化しました。このモデルを NVIDIA T4 GPU 上で動作させ、Stanford Question Answering Dataset でテストしたところ、わずか 2.2 ミリ秒で応答を導き出しました。SQuAD という呼び方でも知られるこのデータセットは、文脈を理解するモデルの能力を評価する代表的なベンチマークです。
多くのリアルタイム アプリケーションでのレイテンシのしきい値は 10 ミリ秒です。 高度に最適化された CPU コードでも、処理時間は 40 ミリ秒を超えます。
推論時間を数ミリ秒に短縮することで、BERT を本番環境に導入することが初めて現実的になりました。また、BERT だけでなく、GPT-2、XLNet、RoBERTa といった、Transformer ベースの大規模な自然言語モデルにも同じ方法を使用して高速化することができます。
真の対話型 AI の実現という目標に向けて、言語モデルは時を経ることに成長しています。将来のモデルは現在使用されているモデルよりも何倍も大きくなることでしょう。そのため、NVIDIA は最大級の Transformer ベースの AI である GPT-2 8B を構築してオープンソース化しました。これは、83 億パラメータを持つ言語処理モデルで、BERT-Large の 24 倍の大きさです。
Transformer ベースの自然言語処理アプリケーションの構築方法を学ぶ
NVIDIA Deep Learning Institute では、ドキュメントの分類などのテキスト分類タスク向けの Transformer ベースの自然言語処理モデルを構築する基本的なツールと手法について、インストラクターの指導による実践的なトレーニングを提供しています。この 8 時間のワークショップでは専門家の指導による詳細なトレーニングが用意されており、参加者は以下のことができるように学習します。
- Word2Vec やリカレント ニューラルネットワーク ベースの埋め込みから Transformer ベースの文脈の埋め込みまで、NLP タスクで単語埋め込みが急速に進化してきたかを理解する。
- Transformer アーキテクチャの機能、特に Self-Attention を用いて、RNN なしで言語モデルを作成する方法について知る。
- Self-Supervision を用いて、BERT や Megatron などの Transformer ベースのモデルにおける Transformer アーキテクチャを改善し、NLP をさらに優れたものにする。
- 事前にトレーニング済みの最新の NLP モデルを活用して、テキスト分類、NER、質疑応答などの複数のタスクを解決する。
- 推論の課題を扱い、ライブ アプリケーション用に洗練されたモデルを展開する。
DLI の認定書を獲得して、主題に関する能力を実証し、キャリアの成長に役立てましょう。次回の GTC で開催されるワークショップを受講するか、企業向けのワークショップをリクエストしてください。
対話型 AI や、GPU での BERT のトレーニング、推論向けの BERT の最適化など、自然言語処理におけるプロジェクトの詳細については、NVIDIA 開発者向けブログをご覧ください。
※NVIDIA Jarvis の名称は 2021 年 7 月に NVIDIA Riva に変更されました。
※Transfer Learning Toolkit の名称は 2021 年 8 月に TAO Toolkit に変更されました。