 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
RAPIDS データサイエンス ソフトウェアと DGX A100 の組み合わせで、19.5 倍の TPCx-BB のベンチマーク記録を達成
NVIDIA が、TPCx-BB として知られているビッグデータ分析の標準的なベンチマークにて、記録を 20 倍近く上回る快挙を達成しました。
NVIDIAは 16 台の NVIDIA DGX A100 システムで、オープンソース データサイエンス ライブラリのスイートであるRAPIDS を使い、ベンチマークをわずか 14.5 分で実行しました。CPU でのこのベンチマークの現在の記録は、4.7 時間です。使用した DGX A100 システムは、合計 128 基の NVIDIA A100 GPU を搭載し、NVIDIA Mellanox ネットワーキングを使用していました。
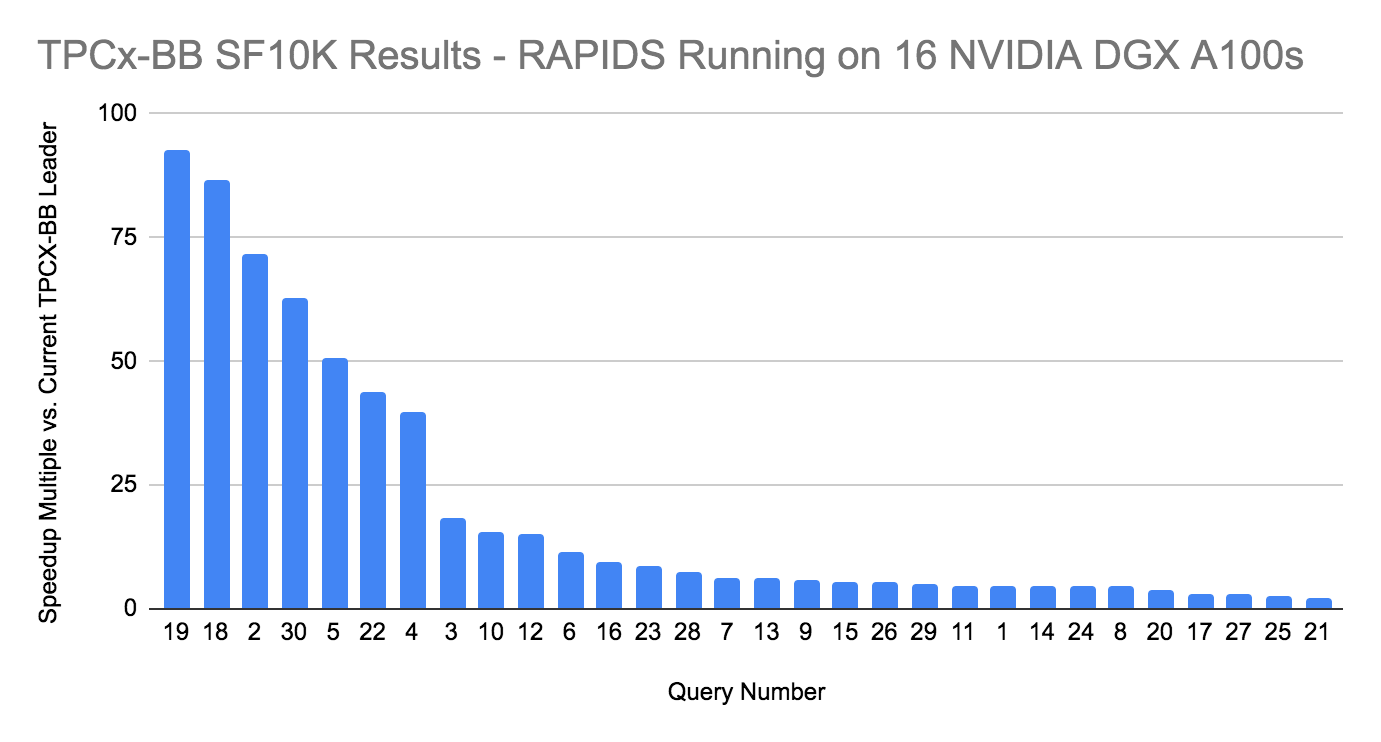 TPCx-BBのベンチマークは、30のクエリでの結果です。16台のDGX A100システム上でRAPIDSを実行することで、10TBのテストでは、クエリごとに上記のような相対的なパフォーマンス向上を実現しています。
TPCx-BBのベンチマークは、30のクエリでの結果です。16台のDGX A100システム上でRAPIDSを実行することで、10TBのテストでは、クエリごとに上記のような相対的なパフォーマンス向上を実現しています。すべてのシステムが性能をフルに発揮: ソフトウェアとハードウェアが一体となり、驚異的な記録を達成
今日、先進的な組織はAIを使って洞察力を得ています。TPCx-BB ベンチマークは、SQL と構造データでの機械学習、ならびに自然言語処理および非構造データを組み合わせたクエリを特徴としており、現代のデータ分析ワークフローに見られる多様性を反映しています。
これらの非公式の結果が新たな標準となっており、この新しい標準を大きく上回るブレイクスルーが、NVIDIA のソフトウェアとハードウェアのエコシステムを通じて利用可能となっています。
ベンチマークを実行するために、NVIDIA はデータ処理と機械学習には RAPIDS を、水平スケーリングには Dask を、超高速通信には UCX オープンソース ライブラリを使い、これらすべてを DGX A100 で高速処理しました。
DGX A100 システムでは、単一のソフトウェア デファインド プラットフォームで、分析、AI の学習や推論を効果的に行えます。DGX A100 は、NVIDIA の最新の Ampere アーキテクチャをベースにした NVIDIA A100 Tensor コア GPU と NVIDIA Mellanox ネットワーキングを、簡単に拡張できるターンキー システムに統合しています。
並列処理で他にはない性能を発揮
TPCx-BB は、現実世界の ETL (抽出、変換、ロード) ならびに機械学習のワークフローを対象とした、エンタープライズ向けのビッグデータ ベンチマークです。このベンチマークの 30 のクエリには、在庫管理や価格分析、販売分析、レコメンデーション システム、顧客セグメンテーション、センチメント分析といったユースケースが含まれています。
分散コンピューティング システムがすでに着実な進歩を続けているにもかかわらず、このようなビッグデータのワークロードは今でも、CPU で処理する際のボトルネックになっています。DGX A100 での RAPIDS の結果は、これまで CPU のみのシステムで測定されてきたTPCx-BB ベンチマークを GPU で実行することによる画期的な可能性を示しています。
このベンチマークでは、RAPIDS ソフトウェアのエコシステムと DGX A100 システムが、演算、通信、ネットワーキングおよびストレージ インフラストラクチャを加速しています。この統合が、データサイエンスのワークロードを大規模に処理する際の新たな基準を生み出しています。
ビッグデータ スケールでの効率的なベンチマーク処理
SF10000 TPCx-BB の規模において、NVIDIA のテストは、10 テラバイトを越えるデータのワークロード処理の結果を示しています。
この規模では、クエリが複雑になると実行時間が急速にはね上がり、その結果、データセンターのスペース、サーバー機器、電力、冷却および IT の専門知識などのコストが増加するようになります。エラスティックな DGX A100 アーキテクチャは、このような課題に対処します。
また、NVIDIA のハードウェア パートナーが提供する、新しい NVIDIA A100 Tensor コア GPU システムにより、データサイエンティストは、A100 の画期的な性能を活用してワークロードを加速するという選択肢も得られるようになります。
オープンソースの加速とコラボレーション
RAPIDS TPCx-BB ベンチマーク は、たくさんのパートナーおよびオープンソース コミュニティが参加する、進行中のプロジェクトです。
TPCx-BB のクエリには、RAPIDS データフレーム ライブラリ、cuDF、RAPIDS 機械学習ライブラリ、cuML、CuPy、BlazingSQL および Dask を活用した、一連の Python スクリプトが主要なライブラリとして実装されています。また、ユーザー デファインド機能にカスタムのロジックを実装するためには Numba が、名前付きエンティティ認識には spaCy が使用されています。
これらの結果は、RAPIDS と 広範な PyData のエコシステムがなければ達成不可能だったでしょう。
RAPIDS についての詳しい情報は、rapids.ai ウェブサイトをご覧ください。







