 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE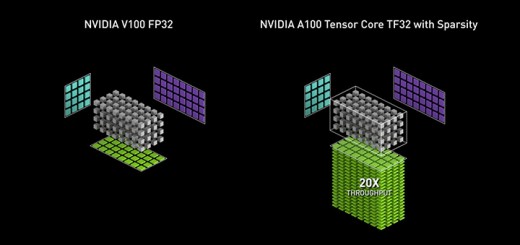
A100 GPUの TensorFloat-32 が AI の学習とHPC を最大 20 倍高速化
TF32 に対応した、NVIDIA の Ampere アーキテクチャが単精度処理を高速化し、精度を保ち、コードの変更も不要
![]()
![]()
TF32 に対応した、NVIDIA の Ampere アーキテクチャが単精度処理を高速化し、精度を保ち、コードの変更も不要
鋼は長い間産業化の象徴でした。AI 時代には、新たな「建材」が最先端データ センターの礎となるでしょう。それが「NVIDIA DGX A100」です。
NVIDIA DGX システムは、AI の展開はよりシンプルに、より速く、より費用対効果の高いものにし、組織のビジネスに最適なアプローチを実現します。
パックマンの 5 万エピソードでトレーニングした敵対的生成ネットワークである GameGAN が、ドットを食べながら進む往年の名作をゲーム エンジンなしで、完全に再現









