TF32 に対応した、NVIDIA の Ampere アーキテクチャが単精度処理を高速化し、精度を保ち、コードの変更も不要
すべてのコンピューティングと同じように、AI をうまく動かすには演算が必要になります。ディープラーニングはまだ若い分野であるため、学習と推論の両方でどのような種類の演算が必要かについて、今も活発な議論が続いています。
NVIDIA は 11 月に、AI とハイパフォーマンス コンピューティングでよく使用される、単精度、倍精度、半精度、および混合精度といった演算のフォーマットの違いについての説明を行いました。先日、AI で広く使用されている単精度モデルでの学習性能を向上させるための新たなアプローチが、NVIDIA Ampere アーキテクチャに導入されました。
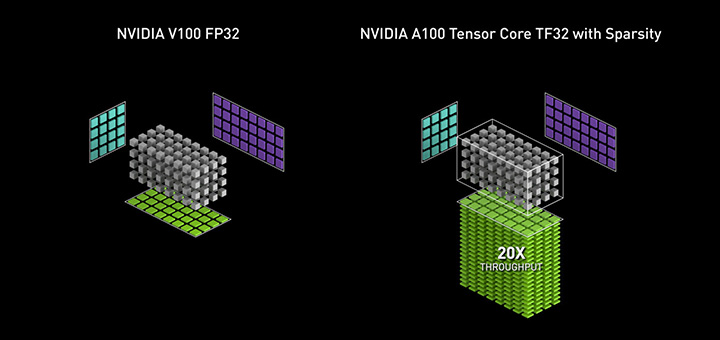
TensorFloat-32 (TF32) は、AI や一部の HPC アプリケーションの中心で使用されている、行列演算 (テンソル演算とも呼ばれています) を処理するための、NVIDIA A100 GPU の新しい演算モードです。A100 GPU の Tensor コアで実行される TF32 は、Volta GPU での単精度浮動小数点演算 (FP32) に比べて最大で 10 倍の高速化を可能にします。A100 で TF32 を構造的疎性と組み合わせることで、Volta と比較して性能が最大 20 倍向上します。
新たな計算の理解
少し逆戻りして、TF32 がどのように動作するのか、どこで使うのがふさわしいのかを見てみましょう。
演算のフォーマットは定規のようなものです。フォーマットの指数部のビット数によって、その範囲、つまりどれくらい大きな物体を測れるかが決まります。フォーマットの精度、つまり定規の線の細かさは、仮数、つまり基数または小数点のあとの浮動小数点数の部分に使用されるビット数によって決まります。
良いフォーマットはうまくバランスが取れています。ビット数が多くなると処理が遅くなり、メモリも膨れ上がるので、精度を実現するのに適切なビット数を使用しなければなりません。
下の図、TF32 がハイブリッドであり、テンソル演算のためにバランスを取ったものであることを示しています。
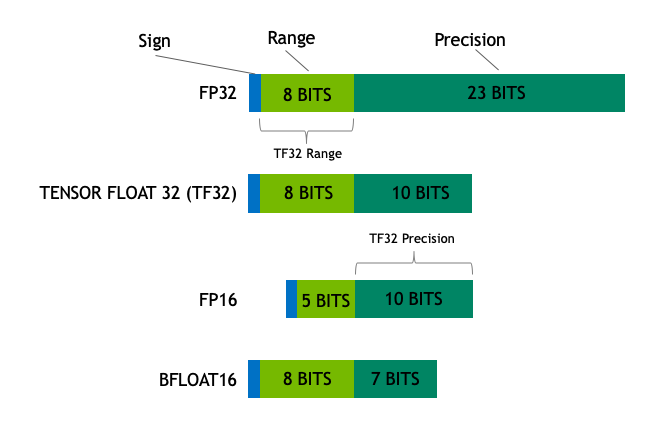 TF32 は範囲と精度の性能を両立
TF32 は範囲と精度の性能を両立TF32 は半精度 (FP16) の計算と同じように 10 ビットの仮数を使っています。これは、AI ワークロードの精度要件には十分な余裕があることを示しています。また、TF32 は FP32 と同じ 8 ビットの指数を採用しているので、同じ数値範囲をサポートすることができます。
この組み合わせにより、TF32 は 単精度演算でディープラーニングや多くの HPC アプリケーションの中心部分である大規模な積和演算処理をするための FP32 に代わる優れたフォーマットとなります。
NVIDIA ライブラリを使ったアプリケーションでは、ユーザーはコードを変更する必要なく、TF32 の利点を得られるようになります。TF32 Tensor コアは、FP32 の入力で演算処理を行い、FP32 で結果を生成します。行列ではない演算では引き続き FP32 が使われます。
最大の性能を発揮するために、A100 では 16 ビットの演算機能も強化されています。FP16 と Bfloat16 (BF16) の両方に対応し、TF32 の倍の速度で動作します。自動混合精度を利用すれば、わずか数行のコードを追加するだけでさらに 2 倍の処理性能を得ることができます。
TF32 がすばらしい成果を立証中
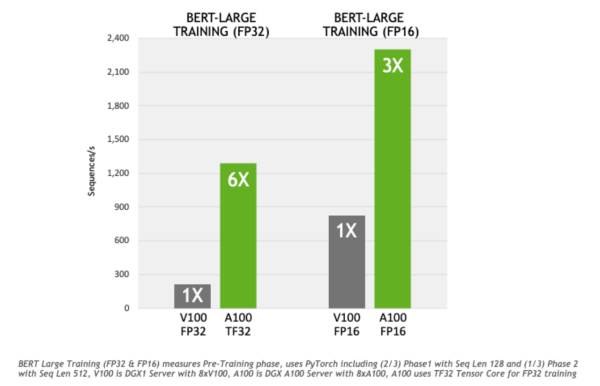
FP32 との比較では、TF32 は、最も負荷の高い 対話型 AI モデルの 1 つである BERT の学習で 6 倍の高速化を示しています。行列計算に依存する他の AI の学習や HPC アプリケーションレベルでの結果は、ワークロードによって異なります。
TF32 の精度を検証するために、コンピューター ビジョンから自然言語処理、レコメンダー システムに至る、多様なアプリケーションで、広範な AI ネットワークを学習させました。これらネットワークのすべてで、FP32 と同じ収束精度の挙動が確認できました。
そのため NVIDIA では、ニューラルネットワークの主要な演算処理を高速化する cuDNN において、TF32 を標準で使用しています。同時に、NVIDIA は AI フレームワークを開発しているオープンソース コミュニティとも連携して、TF32 が A100 GPU での標準学習モードとして採用されるように取り組んでいます。
6 月には、NVIDIA の GPU アクセラレーション ソフトウェアのカタログである NGC にて、開発者は TF32 に対応する TensorFlow フレームワークのバージョンと PyTorch フレームワークのバージョンにアクセスできるようになります。
TensorFlow 製品管理ディレクターであるケマル エル ムジャヒド (Kemal El Moujahid) は、次のように述べています。「TensorFloat-32 は、FP32 レベルの精度を維持しながら、学習と推論のための AI アプリケーションの性能を飛躍的に向上させます。当社では、TensorFlow にて TensorFloat-32 をネイティブにサポートすることで、データ サイエンティストがコードを変更することなく、NVIDIA A100 Tensor コア GPU の劇的な高速化の恩恵を受けられるようにする予定です」
PyTorch チームの広報担当者は、次のように述べています。「機械学習の研究者、データ サイエンティストおよびエンジニアは、解決までの時間を短縮したいと思っています。TF32 が PyTorch にネイティブに統合されると、NVIDIA Ampere アーキテクチャベースの GPU を使用する際に、FP32 の精度を維持しつつ、コードを変更なしで高速化が可能になります」
TF32 が HPC での線形ソルバーを高速化
TF32 は、反復的な行列計算を行うアルゴリズムであり、線形ソルバーと呼ばれている HPC アプリケーションにも有効です。これらのアプリケーションは、地球科学、流体力学、ヘルスケア、物性科学および核エネルギー、ならびに石油ガス探査といった多様な分野で使用されています。
FP32 を使用して FP64 並みの精度を実現する線形ソルバーは、30 年以上にわたって使用されています。昨年、国際熱核融合実験炉の核融合反応についての研究では、混合精度の手法で、NVIDIA FP16 Tensor コアを使った線形ソルバーの処理速度が 3.5 倍になることが実証されました。この研究で使われたものと同じテクノロジは、HPL-AI ベンチマークでの Summit スーパーコンピューターの性能を 3 倍に向上させた研究でも使用されました。
線形システム ソルバーでの TF32 のパワーと堅牢性を実証するために、NVIDIA は、A100 で動作する CUDA 11.0 で cuSOLVER を使い、SuiteSparse の行列コレクションでさまざまなテストを実施しました。これらのテストにおいて、TF32 は、FP16 と BF16 を含む他の Tensor コア モードとの比較で、最も高速で、最も堅牢であるという結果を出しました。
線形ソルバー以外のハイパフォーマンス コンピューティングの他の領域でも、FP32 の行列演算が利用されています。NVIDIA では、業界と連携して、現在 FP32 に依存しているユースケースで TF32 の応用を研究することを予定しています。
詳しい情報
NVIDIA の最新 GPU にて対応している TF32 の役割の全体像を知るには、NVIDIA の創業者/CEO のジェンスン フアン (Jensen Huang) の基調講演をご覧ください。さらに詳しい情報は、混合精度のトレーニングまたはCUDA 計算ライブラリのウェビナーにご登録いただくか、NVIDIA Ampere アーキテクチャの全容を記した、詳細な記事をお読みください。
TF32 は、NVIDIA Ampere アーキテクチャの新機能の 1 つであり、AI と HPC の処理性能を新たな高みに引き上げます。詳細は、以下のテーマを採り上げた NVIDIA ブログをお読みください。
- スパース性への対応により、AI 推論を最大で 50% 改善
- 倍精度の Tensor コアにより、HPC シミュレーションの速度が最大 2.5倍に
- マルチインスタンス GPU (MIG) により、GPU の生産性が最大 7 倍に
- または、NVIDIA A100 GPU についてのウェブページをご覧ください。