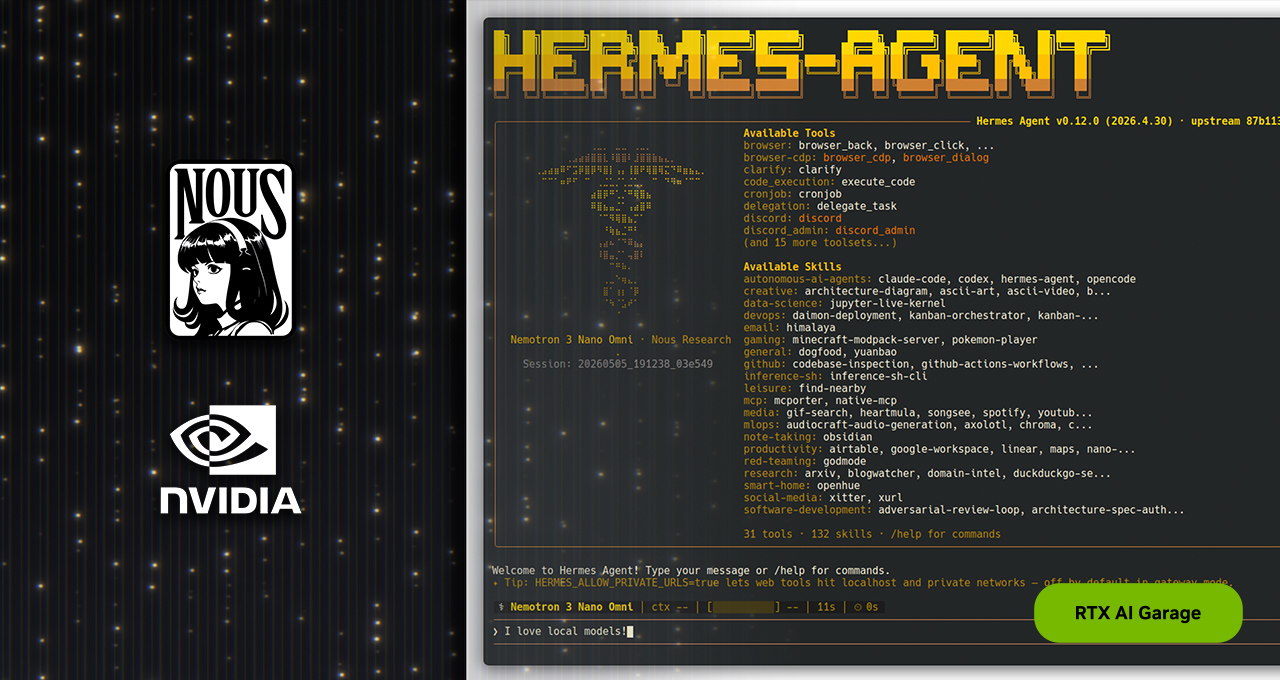
エージェント型 AI は、ユーザーの仕事の進め方を変えつつあります。OpenClaw の成功に続き、コミュニティでは新たなオープン ソースのエージェント型フレームワークが注目されています。その最新作である Hermes Agent は、わずか 3 か月足らずで GitHub のスター数が 14 万を超え、先週時点での OpenRouter によると、世界で最も利用されているエージェントとなっています。
Nous Research が開発した Hermes は、信頼性と自己改善という、従来エージェントでは実現が困難とされてきた 2 つの特性を重視して設計されています。設計段階からプロバイダーやモデルに依存しないように作られており、常時稼働のローカル環境に最適化されているため、NVIDIA RTX PC、NVIDIA RTX PRO ワークステーション、NVIDIA DGX Spark といったハードウェアは、Hermes を 24 時間 365 日フルスピードで動作させるのに最適です。
Alibaba が開発した高性能なオープン ウェイトの大規模言語モデル (LLM) の新シリーズである Qwen 3.6 は、Hermes のようなローカル エージェントの実行に最適です。Qwen 3.6 の 27B および 35B パラメータのモデルは、前世代の 120B および 400B パラメータ モデルを凌駕する性能を発揮し、NVIDIA RTX および DGX Spark 上で動作することで、エージェント型 AI を加速させます。
Hermes: ローカル AI エージェントの機能を向上
よく利用されている他のエージェントと同じく、Hermes はメッセージング アプリと連携し、ローカル ファイルやアプリケーションにアクセスでき、24 時間 365 日稼働します。しかし、Hermes は以下の 4 つの特長において際立っています。
- 自己進化型スキル: Hermes は自分のスキルを記述し改良します。エージェントは複雑なタスクに遭遇するたび、あるいはフィードバックを受けるたびに、学習内容をスキルとして保存するため、時間とともに適応能力が上がり、自己を改善していきます。
- 独立したサブエージェント: Hermes はサブエージェントを、限定されたコンテキストとツール群を持つ、サブタスク専用の短命かつ独立したワーカーとして扱います。これにより、タスク構成が整理され、エージェントの混乱が最小限に抑えられ、Hermes はより小さなコンテキスト ウィンドウで動作できるようになります。これはローカル モデルにとって理想的な仕組みです。
- 設計段階からの信頼性確保: Nous Research は、Hermes に同梱されるすべてのスキル、ツール、プラグインを厳選し、ストレステストを実施しています。その結果、Hermes は、300 億パラメータ規模のローカル モデルであっても、他の多くのエージェント フレームワークで必要とされるような絶え間ないデバッグ作業は不要で、問題なく動作します。
- 同じモデルでもより優れた結果: 異なるフレームワーク間で同一のモデルを用いた開発者による比較では、Hermes の方が一貫して優れた結果を示しています。その違いはフレームワークにあります。Hermes は単なる薄いラッパーではなく、能動的なオーケストレーション層であり、タスクごとに実行するのではなくデバイス上に常駐するエージェントを実現します。
Hermes エージェントとその基盤となる LLM はどちらもローカルで動作するように設計されているため、ハードウェアの品質がユーザー体験の品質を直接左右します。NVIDIA RTX GPU は、まさにこのようなワークロード向けに設計されています。
Qwen 3.6: データセンターレベルのインテリジェンスをローカルで
最新の Qwen 3.6 モデルは、高い評価を得ている Qwen 3.5 シリーズを基盤とし、ローカル AI エージェントをさらに飛躍的に向上させました。新しい Qwen 3.6 35B モデルは、約 20GB のメモリで動作するにもかかわらず、70GB 以上のメモリを必要とする 1,200 億パラメータ モデルを凌駕します。
さらに、Qwen 3.6 27B はより多くのアクティブ パラメータを持つ新しい高密度モデルであり、Qwen 3.5 397B のような 4,000 億パラメータ モデルと同等の精度を実現しながら、サイズはわずか 16 分の 1 に抑えられています。ハイエンドの RTX GPU 上で動作することで、高速な体験に必要な計算能力をモデルに提供します。
これらのモデルは、Hermes のようなローカル エージェントに最適であり、NVIDIA GPU や DGX Spark を使用することで最も高速に実行できます。NVIDIA Tensor コアは AI 推論を高速化し、スループットの向上と遅延の削減を実現します。これにより、Hermes は複数ステップのタスク処理や自身のスキル改良を、数分ではなく数秒でできるようになります。
DGX Spark: 常時稼働型エージェント型コンピューター
Hermes のようなエージェントは、リクエストへの応答、複数ステップのタスクの計画、自律的な実行、自己改善という継続的な動作を前提に設計されています。NVIDIA DGX Spark は、終日稼働する持続的なエージェント型ワークフローのために構築された、コンパクトで効率的なスタンドアロン マシンであり、Hermes にとって理想的なパートナーです。
128GB の統合メモリと 1 ペタフロップスの AI 性能を備えた NVIDIA DGX Spark は、1,200 億パラメータの Mixture-of-Experts モデルを終日実行し続けることができます。さらに、新しい Qwen 3.6 35B モデルは、より少ない占有容量で同等のインテリジェンスを実現するため、より高速に動作するだけでなく、ユーザーがワークロードを並行して実行する容量が得られます。
パフォーマンスと使いやすさを最大限に引き出すために、Hermes 向けの DGX Spark Playbook をご覧ください。また、NVIDIA の「Build It Yourself」エージェント型 AI シリーズで開催予定のハンズオン セッションにご登録いただくと、NemoClaw と OpenShell を使った自律型 AI エージェントの構築方法を学ぶことができます。
NVIDIA DGX Spark は NVIDIA のパートナーから注文可能です。マーケットプレイスをご覧ください。
NVIDIA ハードウェア上で Hermes を利用開始する
NVIDIA ハードウェア上で Hermes をローカルで実行するのは簡単です。
まずは Hermes の GitHub リポジトリにアクセスし、お使いのローカル モデルやランタイムと組み合わせてみてください。Hermes は、llama.cpp、LM Studio、Ollama を介して、Qwen 3.6 と連携して実行できます。Hermes Agent には、ローカル エージェントを最も簡単に構築できるよう、LM Studio と Ollama のサポートが標準で付属しています。
パーソナル エージェントの最先端を探求するローカル AI 愛好家の方にも、ワークフロー用のローカル ツールを構築する開発者の方にも、NVIDIA ハードウェア上の Hermes は他に類を見ないほど高性能で信頼性の高い基盤を提供します。
NVIDIA RTX ハードウェア向けに最適化された最新のオープン モデルとエージェントに関する最新情報を RTX AI Garage で配信中です。今後の情報にぜひご期待ください。
#ICYMI: RTX AI Garage の最新情報
✨ NVIDIA RTX PRO GPU は、llama.cpp を使用した Qwen 3.6 モデルの実行において、トークン生成を最大 3 倍高速化します。エージェントがマルチステップのタスクを処理してスキルを改良することでワークフローをシームレスに維持するための、ローカル AI に必要なリアルタイム応答性を実現します。
Google の Gemma 4 26B および 31B モデルが NVFP4 チェックポイントとして利用可能になり、NVIDIA Blackwell GPU 上でさらに高速なパフォーマンスを実現します。NVFP4 チェックポイントを Google の新しいマルチトークン予測ドラフターと組み合わせることで、出力品質を同等に保ちながら最大 3 倍高速な推論が可能になり、最先端のリーズニングを NVIDIA GPU 上でローカルに実行できるようになります。
Mistral Medium バージョン 3.5 (4 月にリリース) には llama.cpp および Ollama との互換性アップデートが含まれており、NVIDIA RTX PRO および DGX Spark システムで実行できます。
🦞 NVIDIA は先日、NVIDIA NemoClaw を発表しました。これは、セキュリティを強化しローカルモデルをサポートすることで NVIDIA デバイスにおける OpenClaw の体験を最適化するオープン ソースのスタックです。NemoClaw は Windows Subsystem for Linux (WSL2) をサポートするようになり、Microsoft プラットフォームを利用する愛好者や開発者も利用できるようになりました。こちらのステップバイステップの Playbook を参考に、DGX Spark で NemoClaw を使い始めてみましょう。
Facebook、Instagram、TikTok、X で NVIDIA AI PC をフォローしましょう。また、RTX AI PC ニュースレターにご登録いただくと、最新情報を入手できます。
LinkedIn と X で NVIDIA Workstation をフォローしてください。
ソフトウェア製品情報については、お知らせをご覧ください。