
画期的な AI モデルのスタートはどれも、トレーニングの実行から始まります。そうしたトレーニングのジョブを支えるインフラは、チームがどれほどの速さでイテレーションを繰り返せるか、どんな規模のモデルを構築できるか、ジョブが安定して完了できるか、といったあらゆる要素を左右します。
モデルの規模、複雑さ、インテリジェンスが進化するにつれ、トレーニングのインフラに求められる要件も高くなっています。
MLPerf Training 6.0 (AI トレーニングの性能を評価する、ピアレビューを経た厳格な業界ベンチマークの最新版) において、NVIDIA Blackwell プラットフォームは全カテゴリーで首位を獲得し、以下の点を実証しました。
- すべてのベンチマークにおいて最速のトレーニング
- NVIDIA Blackwell NVL72 システムを用いた 8,192 基の GPU による最大規模のトレーニング
- 本スイートに含まれる 7 つのベンチマークすべてで結果を提出した唯一のプラットフォーム
NVIDIA は、徹底した協調設計を通じて構築された単一のプラットフォームに、性能、拡張性、信頼性を集約しました。これにより、AI モデル開発企業は最先端モデルのリリースの迅速化、トレーニング コストの最小化、および早期の収益化を実現できるようになります。
性能: すべてのベンチマークにおいて最速のトレーニング
MLPerf Training 6.0 では、Mixture-of-Experts (MoE) アーキテクチャの重要性が高まっていることを受け、DeepSeek-V3 671B と GPT-OSS-20B という 2 つの新しい MoE 事前トレーニング ワークロードがスイートに追加されました。NVIDIA のプラットフォームは、すべてのベンチマークで結果を提出した唯一のプラットフォームであり、7 つすべてのベンチマークにおいて最速のトレーニングを実現しています。

今回のラウンドで、NVIDIA は NVIDIA GB200 NVL72 および GB300 NVL72 の両ラックスケール システムで結果を提出しました。各ラックスケール システム内では、第 5 世代 NVIDIA NVLink スイッチが 72 基すべての GPU を高帯域幅で接続し、計算リソースとメモリを統合したプールとして機能させることで、システム全体を 1 つの巨大な GPU として動作させることが可能になっています。
大規模な MoE トレーニングでも、MoE 推論と同じく all-to-all 通信が課題となります。つまり、トークンを GPU 間でルーティングして適切なエキスパート サブネットワークに到達させる必要があるのですが、NVLink の帯域幅の優位性こそが、大規模な環境においてこれを高速かつ効率的に実現する要因となります。
また NVIDIA は、大規模および小規模の事前トレーニング、ならびにファインチューニングの各ワークロードにおいて、厳しい精度要件を満たしつつパフォーマンスを向上させる、NVFP4 トレーニング手法も紹介しました。NVIDIA は、さまざまなモデル アーキテクチャにおいて低精度トレーニングの技術革新を推進し続けており、直近では NVFP4 を用いて、5,500 億パラメータという巨大な NVIDIA Nemotron 3 Ultra モデルの事前トレーニングを行っています。
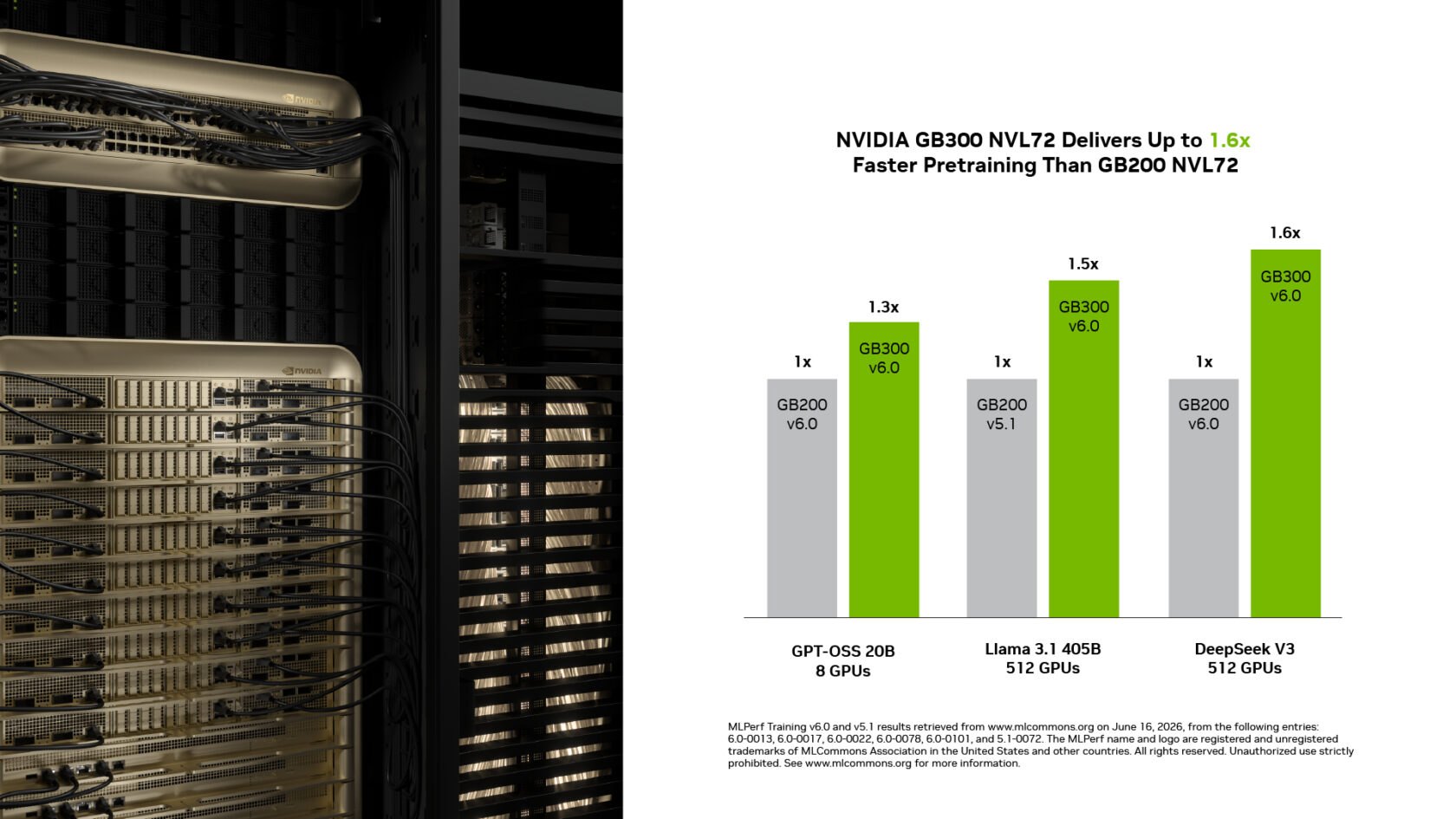
NVIDIA GB300 NVL72 は GB200 NVL72 と比較して最大 1.6 倍の性能を実現: 今回のラウンドでは、GB300 NVL72 は同等のスケールにおいて GB200 NVL72 よりも最大 1.6 倍高速なトレーニングを実現しています。この性能向上は、NVFP4 による演算密度の向上、メモリ容量の拡大、および GPU のピーク性能維持を可能にする電力上限の引き上げといった、Blackwell Ultra の鍵となる機能によって実現されています。
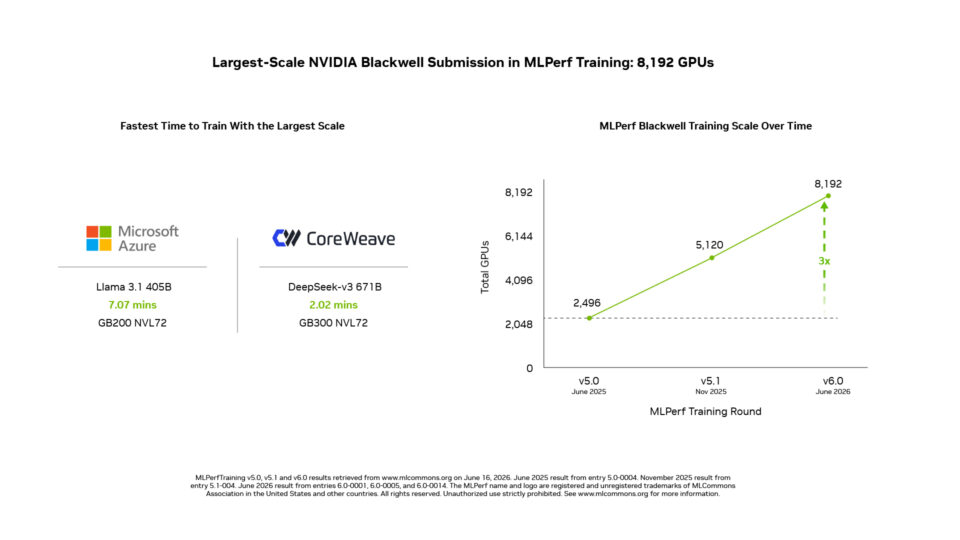
規模: MLPerf Training における最大規模の Blackwell クラスター
大規模な分散トレーニングを支援するため、NVIDIA は NVIDIA Quantum InfiniBand と NVIDIA Spectrum-X Ethernet という、2 つの相互補完的なスケールアウト ネットワーキング プラットフォームを提供しています。これにより、データセンターは自社のインフラに最適化された大規模クラスタを柔軟に構築できます。
このスイートで最大の MoE モデルである DeepSeek-V3 671B において、NVIDIA は GB200 NVL72 システムを使用して GPU 8,192 基規模までスケールアップした結果を提出しました。これは、MLPerf Training において Blackwell アーキテクチャを採用した提出結果として、現時点で最大規模のものです。
また、NVIDIA は、このスイートに含まれる最大規模の高密度 LLM の一つである Llama 3.1 405B において、NVIDIA GB200 NVL72 システムを使用した GPU 5,120 基規模での結果も提出しました。
今回の結果には、システム アーキテクチャ、ネットワーキング、ソフトウェアの各分野における NVIDIA とパートナー各社との緊密な共同エンジニアリングの成果も反映されています。
- Microsoft Azure は、GB200 NVL72 システムを使用して Llama 3.1 405B のトレーニングを GPU 8,192 基規模に拡張し、07 分で基準となる品質目標に到達しました。これは、このベンチマークにおける最短のトレーニング時間です。
- CoreWeave は、DeepSeek-V3 671B のトレーニングにおいて最速の記録を達成しています。Spectrum-X Ethernet ネットワークで接続された GB300 NVL72 システムを使用し、GPU 8,192 基規模で 02 分の品質目標達成を記録しました。
大規模環境での信頼性: 本番運用を見据えた設計
本番のトレーニング環境では、数十万基の GPU を使用して、数週間から数か月に及ぶトレーニングが実行されることがあります。これ程の規模では、効果的なトレーニング スループットを実現するために、システムの性能だけでなく、長期にわたって再現性を確保するレジリエンスが不可欠です。
MLPerf Training v6.0 における前述の結果は、NVIDIA プラットフォームの優れた性能を如実に物語っています。レジリエンスに関して、NVIDIA のプラットフォームは以下の 2 つの側面を念頭に設計されています。
- 中断の低減: NVIDIA GPU は、障害を未然に防ぐよう設計されています。GPU がデータセンターに設置される前段階で、NVIDIA は 30 以上の製造テスト段階を経てスクリーニングを行い、潜在的な不具合を早期に検出します。設置後も RAS (信頼性、可用性、保守性) エンジンがチップのほぼ全体を監視し、自己修復機能によって、ワークロードを中断させることなく、検出された不具合を自動的に迂回させます。ネットワーク レベルでは、Spectrum-X Ethernet が数ミリ秒単位で障害リンクを迂回させ、ジョブを中断させることなくファブリックの健全性を維持します。
- 中断発生時の迅速な復旧: NVIDIA Resiliency Extension (NVRx) は、クラスター全体にわたる障害検出、復旧、健全性監視の機能を備え、障害発生時のダウンタイムを最小限に抑えます。性能が低下しているノードを、クラスター全体の動作速度が低下する前に自動的に検出して管理します。ノードで中断が発生した場合、ジョブ全体を再起動するのではなく、直近のチェックポイント (トレーニングの状況を保存したスナップショット) から処理を再開します。
NVIDIA を基盤に構築されるフロンティア AI
今回のラウンドには NVIDIA のエコシステム パートナーも幅広く参加し、ASUSTeK、Microsoft Azure、Cisco、CoreWeave、Dell Technologies、富士通、Giga Computing、Google Cloud、Hewlett Packard Enterprise、Inventec、Krai、Lambda、Nebius、Netweb Technologies India Ltd.、Quanta Cloud Computing (QCT)、ScitiX、Supermicro、TTA といった 19 の組織から注目すべき結果が提出されました。これらのパートナー企業の多くは、NVIDIA インフラ上で、極めて高い負荷を伴う AI トレーニング ワークロードを実行しています。
Dell PowerEdge サーバーを搭載した Dell PowerRack システム内に NVIDIA のインフラを構築している CoreWeave は、このようなワークロードを複数ホストしています。Cohere は、同社のエージェント型 AI プラットフォームである North において、GB200 NVL72 を使用することでトレーニング速度を 3 倍高速化しました。Midjourney は Blackwell クラスター上で同社の v8 画像生成モデルをトレーニングしましたが、現在は今後リリース予定の画像および動画モデルのトレーニングを行っており、CoreWeave 上で Blackwell Ultra GPU の導入規模を拡大しています。
Google Cloud 上では、Thinking Machines Lab が GB300 NVL72 を使用することで、従来世代の GPU と比較してトレーニングおよびサービングの速度を 2 倍に向上させ、最先端モデルの研究や強化学習ワークフローを加速させています。
AI クラウド上で NVIDIA Blackwell および Blackwell Ultra インフラを運用する Nebius は、Higgsfield のモデルのトレーニング時間を約 30% 短縮させました。これにより、現在 2,200 万人のユーザーにサービスを提供し、1 日あたり 600 万件を超える AI コンテンツを生成する Higgsfield のプラットフォームを支えています。
MLPerf Training 6.0 の結果や、その背景にある最適化技術についての詳細な技術情報は、こちらの技術ブログをご覧ください。