
AI トレーニングの業界標準テストにおいて、NVIDIA H100 Tensor コア GPU がエンタープライズ ワークロードの世界記録を樹立、A100 がハイパフォーマンス コンピューティングの基準を引き上げる
NVIDIA H100 Tensor コア GPU は、NVIDIA MLPerf 推論ベンチマークを制覇しデビューした 2か月後、業界団体の最新の AI トレーニング テストで、エンタープライズ AI ワークロードの世界記録を樹立しました。
これらの結果から、高度な AI モデルの構築と導入に向けて最高のパフォーマンスを求めるユーザーには、H100 が最高の選択肢であることが示されています。
MLPerf は、AI パフォーマンスを測定するための業界標準です。このベンチマークは、Amazon、Arm、百度、Google、ハーバード大学、Intel、Meta、Microsoft、スタンフォード大学、トロント大学など、幅広い企業や研究機関から支持されています。
本日公表された、他の MLPerf のベンチマークでも、NVIDIA A100 Tensor コア GPU が昨年達成したハイパフォーマンス コンピューティング (HPC) の基準を引き上げました。
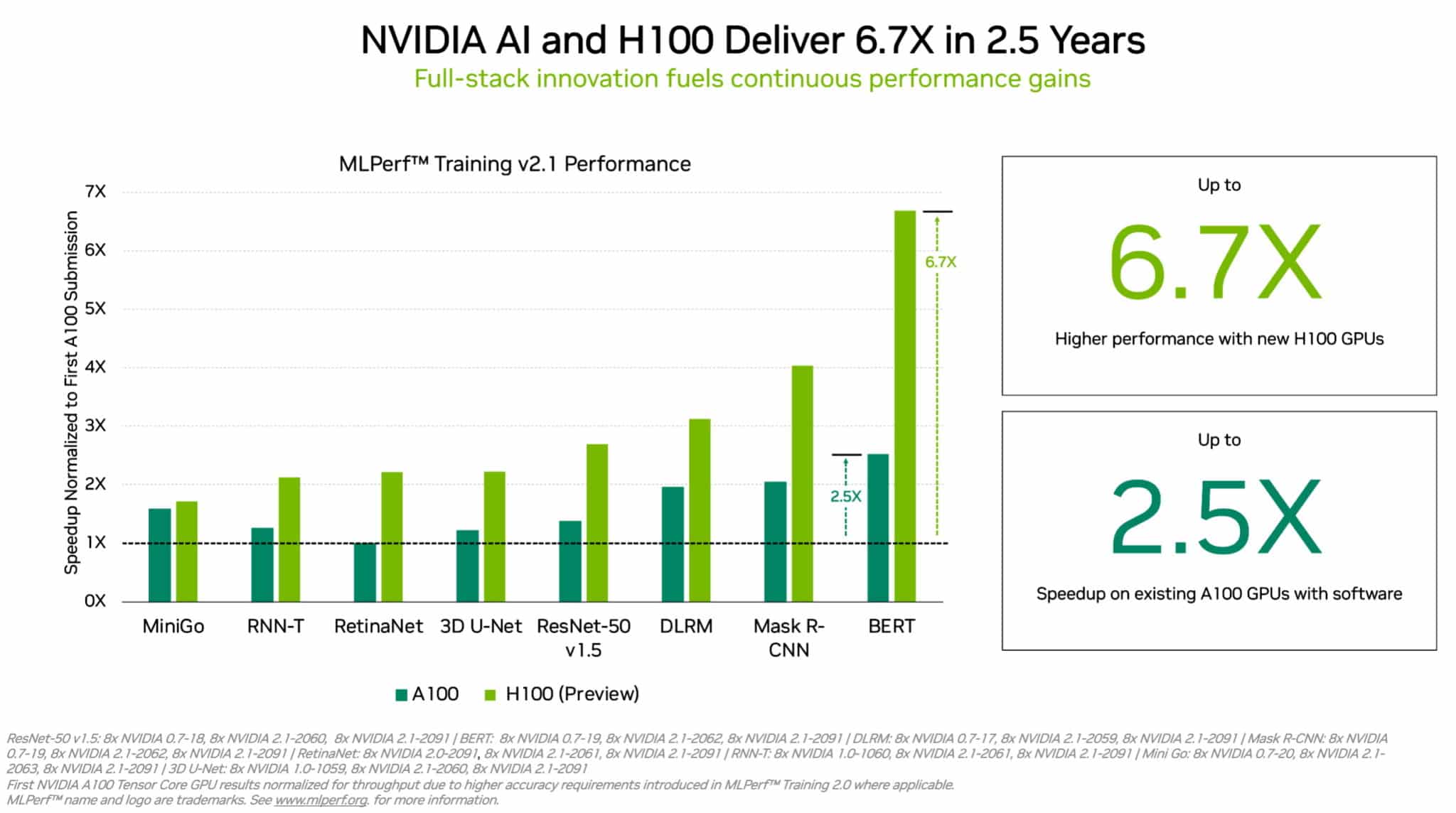
NVIDIA H100 GPU は、MLPerf トレーニングに初めてテスト結果を提出した際の A100 GPU と比較して最大 6.7 倍高速でした。
H100 GPU (別名Hopper) は、8 つの MLPerf エンタープライズ ワークロードのすべてでモデル トレーニングの世界記録を樹立しました。前世代の GPU でMLPerf トレーニングのテスト結果を初めて提出した時と比較して、最大 6.7 倍のパフォーマンス向上を実現しました。同じ比較では、現在の A100 GPU は、ソフトウェアの進歩により 2.5 倍の能力を備えています。
Hopper は Transformer Engine を搭載しており、自然言語処理の一般的な BERT モデルのトレーニングで特に優れていました。これは、MLPerf AI モデルの中で最大かつ最も高いパフォーマンスを必要とするモデルの 1 つです。
MLPerf の結果によって、企業は情報に基づいて購入決定を下すための自信を得ることができます。このベンチマークは、コンピューター ビジョン、自然言語処理、レコメンダー システム、強化学習など、現在最も一般的な AI ワークロードを網羅しているからです。このテストは同業者のレビューを受けているため、結果は信頼に値します。
HPC の新たな頂点を極める A100 GPU
別の MLPerf HPC ベンチマーク スイートでは、A100 GPU が、スーパーコンピューターで実行される要求の厳しい科学ワークロードにおいて、すべてのトレーニング AI モデルのテストを制覇しました。この結果は、NVIDIA の AI プラットフォームが、世界で最も厳しい技術的な課題に対応可能であることを示しています。
たとえば A100 GPU は、2 年前に MLPerf HPC の第 1 ラウンドで記録された最高結果を 9 倍上回るスピードで、宇宙物理学向けの CosmoFlow テストの AI モデルをトレーニングしました。A100 は同じワークロードで、他製品と比較して、1 チップあたり最大で実に 66 倍高いスループットも実現しました。
HPC ベンチマークでトレーニングされるのは、宇宙物理学、気象予報、分子動力学法の研究用モデルです。これらの分野は、創薬をはじめとする多数の技術的分野の一部であり、AI を導入して科学の進歩を実現しています。
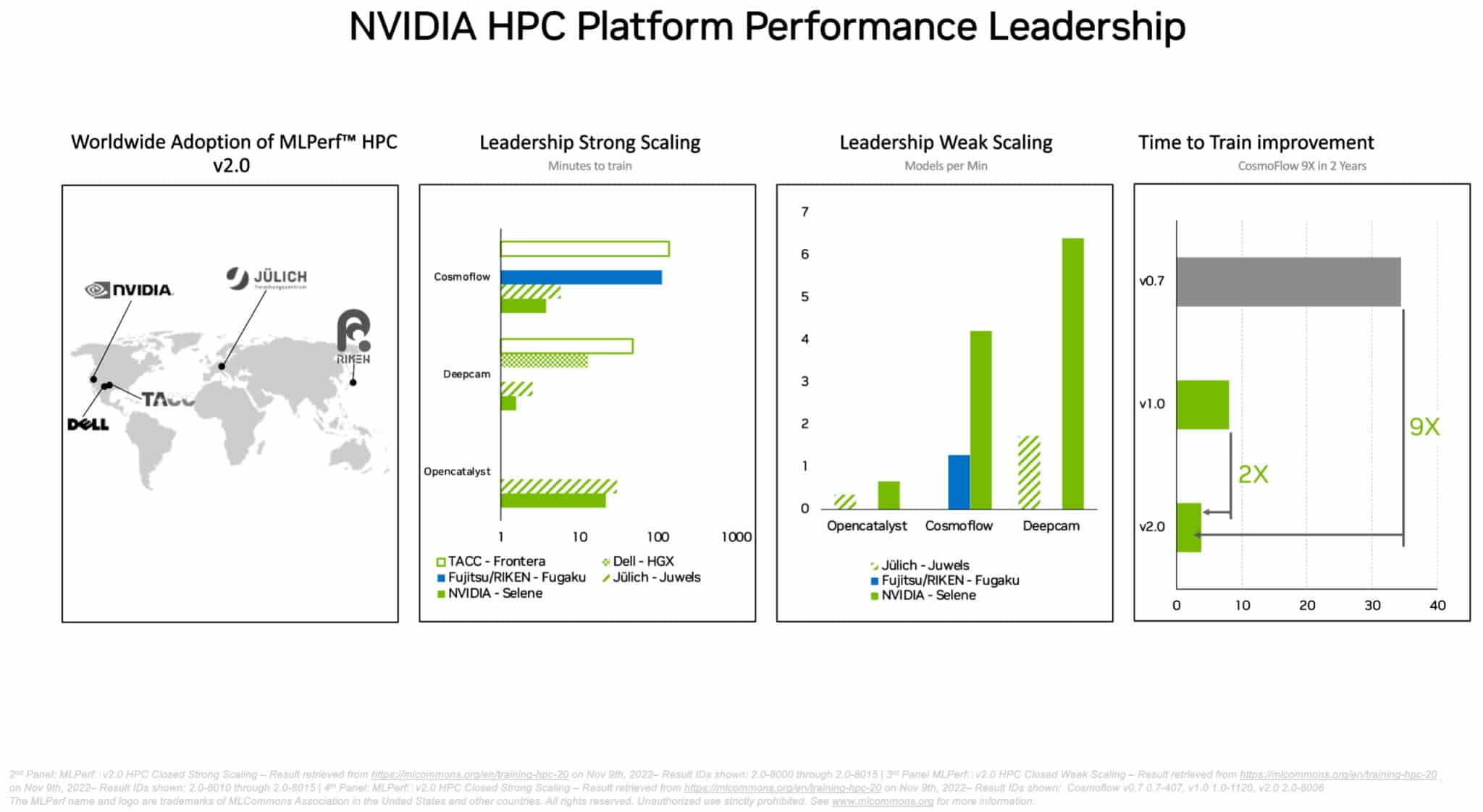
世界中のテストで、A100 GPU がトレーニングのスピードとスループットをリードしました。
アジア、ヨーロッパ、米国の各スーパーコンピューター センターが、MLPerf HPC テストの最新ラウンドに参加しました。DeepCAM ベンチマークでは、NVIDIA A100 GPU を利用してデビューした Dell Technologies が優れた結果を獲得しています。
比類なきエコシステム
エンタープライズ AI トレーニングのベンチマークでは、Microsoft Azure クラウド サービスを含む計 11 社のパートナーが、NVIDIA A100、A30、A40 の各 GPU を使用したテスト結果を提出しました。テストでは、ASUS、Dell Technologies、富士通、GIGABYTE、Hewlett Packard Enterprise、Lenovo、Supermicro などのシステム メーカーが合計 9 種の NVIDIA-Certified Systems を使用しています。
最新のラウンドでは、少なくともパートナー 3 社が NVIDIA と同様に、8 つの MLPerf トレーニング ワークロードすべてにおけるテスト結果を提出しました。現実のアプリケーションでは多様な AI モデルが要求されることが多いため、汎用性の高さが重要です。
NVIDIA のパートナーが MLPerf に参加した理由は、MLPerfがAI プラットフォームやベンダーを評価する顧客にとって価値あるツールであることを知っているからです。
フル スタックの中身
NVIDIA AI プラットフォームは、チップからシステム、ソフトウェア、サービスまで、フル スタックを提供しています。このため、時間の経過にしたがって、パフォーマンスを継続的に向上させることができます。
たとえば、提出された最新の HPC テストの結果では、NVIDIAの技術ブログに記載された一連のソフトウェアの最適化とテクニックが適用されました。これにより、5 倍に高速化し、ベンチマークの実行時間が 101 分からわずか 22 分へと短縮しました。
別のブログ記事では、NVIDIA がエンタープライズ AI ベンチマーク向けにプラットフォームを最適化した方法が記載されています。例えば、コンピューター ビジョンのベンチマーク向けには、NVIDIA DALI を活用して、データの読み込みと前処理を効率的に行っています。
今回のテストで使用されたソフトウェアはすべて、MLPerf リポジトリから入手可能であり、誰でも世界クラスの結果を得ることができます。NVIDIA は、GPU アプリケーション向けソフトウェア ハブの NGC で提供しているコンテナに引き続き最適化を加えていきます。