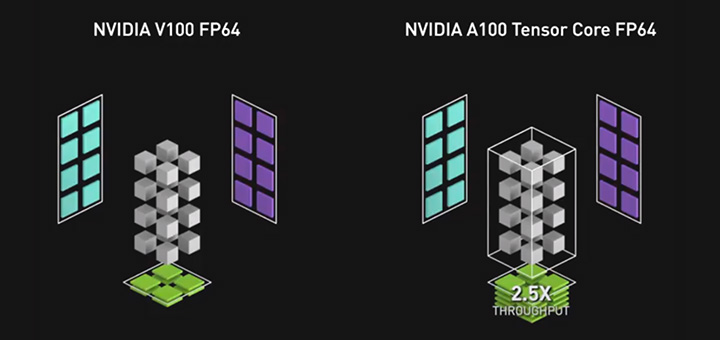
NVIDIA Ampere アーキテクチャにより、シミュレーションおよび反復法ソルバーでの FP64 の演算が最大 2.5 倍スピードアップ
目で見れば、理解も早まります。
シミュレーションは、ブラックホールの謎を理解したり、コロナウイルスのスパイク タンパク質が COVID-19 をどのように引き起こすか見たりするのに役立ちます。また、デザイナーはシミュレーションにより、スポーツカーからジェット エンジンまで、あらゆるもの作り出すことができます。
しかし、シミュレーションは地球上で最も要件の厳しいコンピューター アプリケーションでもあります。多くの高度な演算が必要になるからです。
シミュレーションでは、FP64 と呼ばれる倍精度浮動小数点フォーマットを使用した演算により、数値モデルを可視化します。そのフォーマットのそれぞれの数値はコンピューター内で 64 ビットになるので、今日の GPU が対応している、多数の演算フォーマットの中でも最も演算負荷の高いものの 1 つです。
ハイパフォーマンス コンピューティングを加速させようとする NVIDIA の取り組みにおける、次の大きなステップである NVIDIA Ampere アーキテクチャでは、前世代の GPU に比べて FP64 の演算速度を 2.5 倍に高速化する、第 3 世代の Tensor コアが定義されています。
これは、研究者やデザイナーが一晩中待たされていたシミュレーションが、最新の A100 GPU を使うことによって、数時間で完了することを意味します。
科学と AI の連携
速度の向上は、AI をシミュレーションや実験と組み合わせて、時間の節約となる以下のようなポジティブなフィードバック ループを生み出しています。
最初に、シミュレーションによって、AI モデルの学習を行うデータセットが作成されます。次に、AI とシミュレーションのモデルが同時に実行され、AI モデルが推論によってリアルタイムで結果を出せるようになるまで、お互いの強みを発揮します。学習された AI モデルは、実験やセンサーからデータを取り込み、その洞察をさらに洗練させることもできます。
この手法を使用すると、AI は高解像度のシミュレーションを実行するためのいくつかの関心領域を定義できます。領域を絞り込むことにより、AI は時間のかかる何千ものシミュレーションの必要性を桁違いに大量に削減できます。その後、実行する必要のあるシミュレーションは、A100 GPU で 2.5 倍の速度で実行されます。
FP64 とその他の新機能により、NVIDIA Ampere アーキテクチャをベースとした A100 GPU は、シミュレーションとともに、AI の推論と学習といった、現代の HPC のワークフロー全体に対応する柔軟性のあるプラットフォームとなります。この機能により、開発者はシミュレーション コードを A100 に移行できるようになります。
ユーザーは新しい CUDA-X ライブラリを呼び出して、A100 の FP64 アクセラレーションを利用できます。この GPU の内部には、倍精度行列の積和演算を高速化する新モードである DMMA をサポートする第 3 世代の Tensor コアが搭載されています。
行列演算を加速
1 つの DMMA ジョブでは、1 つのコンピューター命令が従来の 8 つの FP64 の代わりに使われます。その結果、A100 は FP64 演算を他のチップより速く、より少ない作業で高速処理し、時間と電力だけではなく、貴重なメモリと I/O 帯域幅も節約します。
この新しい機能を倍精度 Tensor コアと呼んでいます。HPC アプリケーションにTensor コアのパワーを提供し、完全な FP64 の精度で行列演算を高速化します。
シミュレーション以外でも、反復的な行列演算を行うアルゴリズムである、反復法ソルバーと呼ばれる HPC アプリケーションでも、この新しい機能を利用することができます。これらのアプリケーションには、地球科学、流体力学、ヘルスケア、物性科学および核エネルギー、ならびに石油ガス探査といった多様な分野が含まれます。
世界で最も要件の厳しいアプリケーションに対応するために、倍精度 Tensor コアは、NVIDIA 史上最も大きく、最もパワフルな GPU の内部に搭載されています。A100 には、地球上のどの GPU よりも大きいメモリと帯域幅も備えています。
NVIDIA Ampere アーキテクチャの第 3 世代 Tensor コアは、前のバージョンよりも強化されています。第 3 世代 Tensor コアでは、ユーザーがより困難な問題に対処できるように、さらに大きな 8x8x4 の行列サイズ (Volta では 4x4x4) に対応しています。
これが、計 432 個の Tensor コアが搭載されている A100 が、Volta V100 の処理性能の 2 倍以上である 19.5 FP64 TFLOPS の処理能力を実現している理由の 1 つです。
詳しい情報
NVIDIA の最新 GPU における FP64 の役割についての全体像を知るためには、NVIDIA の創業者/CEO である ジェンスン フアン (Jensen Huang) の基調講演をご覧ください。さらに詳しい情報は、ウェビナーに登録いただくか、NVIDIA Ampere アーキテクチャの全容を記した、詳細な記事をお読みください。
倍精度 Tensor コアは、NVIDIA Ampere アーキテクチャのさまざまな新機能の 1 つであり、AI の学習、推論、および HPC の処理性能を新たな高みに引き上げます。詳細は、以下のテーマを採り上げた NVIDIA ブログをお読みください。