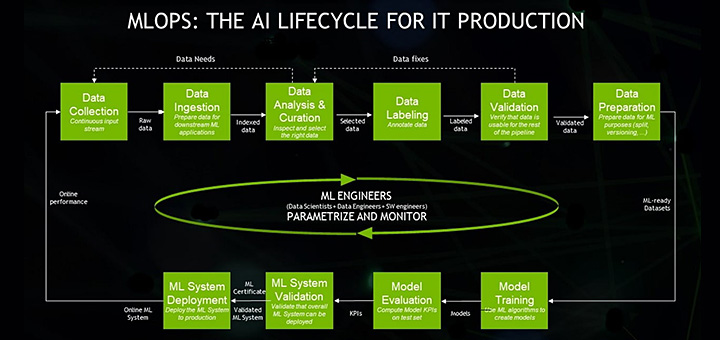
機械学習オペレーション「MLOps」は、拡大を続ける種々のソフトウェア製品やクラウド サービスを活用して企業が AI 運用を成功させるためのベスト プラクティス
MLOps と聞くと毛むくじゃらの一つ目モンスターの名前のように思われるかもしれませんが、実はエンタープライズ AI の成功を意味する頭字語です。
機械学習オペレーション (machine learning operations) の短縮表現である MLOps は、企業が AI 運用を成功させるのに使える一連のベスト プラクティスです。
MLOps は比較的新しい分野ですが、それは AI の商用利用自体がかなり新しいからであると言えます。
MLOps: エンタープライズ AI を主流に押し上げる
AI のビッグバン が鳴り響いたのは 2012 年、ある研究者がディープラーニングを使って画像認識のコンテストで優勝したときでした。その波紋は急速に広がりました。
現在、AI は Web ページを翻訳し、カスタマー サービスへの電話を自動的に転送します。また、病院が X 線を読み取り、銀行が信用リスクを計算し、小売業者が在庫を補充して販売を最適化する支援をしています。
つまり、AI という幅広い分野の一部である機械学習は、ソフトウェア アプリケーションと同じくらい主流になろうとしているのです。だからこそ、機械学習の運用プロセスは、IT システムの運用業務と同じくらい定型的なものにならなければなりません。
DevOps の上に重なる機械学習
MLOps は既存の規範である DevOps の上にモデル化されています。DevOps は、エンタープライズ アプリケーションを効率的に書き、展開し、運用するための最新プラクティスで、対立の絶えないソフトウェア開発者 (Devs) と IT 運用チーム (Ops) の共同作業を可能にする方法として 10 年前に始まりました。
MLOps ではそのチームに、データセットをキュレートし、それを分析する AI モデルを構築するデータ サイエンティストが加わります。また、これらのモデルによるデータセット運用を、統制が取れ自動化された手法で行う機械学習エンジニアも含まれます。
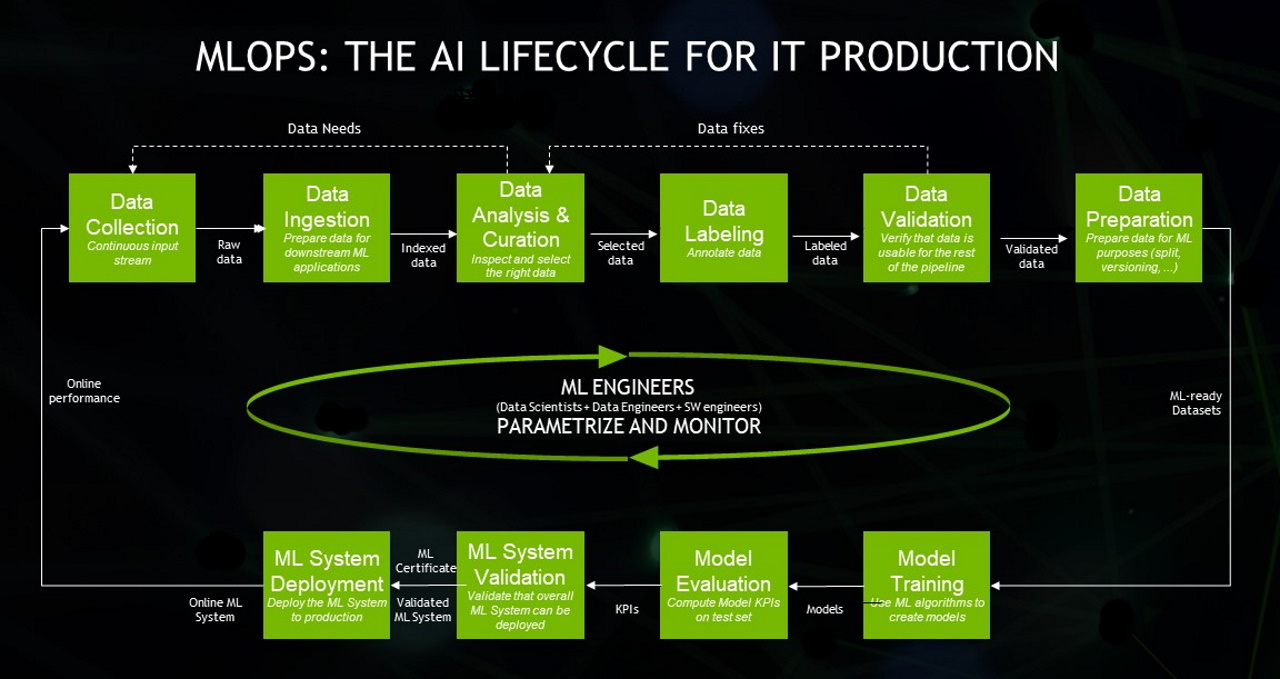
 MLOps は、機械学習、アプリケーション開発、IT 運用を組み合わせます。出典: Neal Analytics
MLOps は、機械学習、アプリケーション開発、IT 運用を組み合わせます。出典: Neal Analytics
これはマネジメントが難しいだけでなく、本来のパフォーマンスにとっても大きな挑戦です。データセットは膨大な上に増え続けており、リアルタイムで変化することもあります。AI モデルは、実験、調整、再トレーニングのサイクルを通じて注意深く追跡しなければなりません。
そのため MLOps には、企業の成長とともに規模を変えられる強力な AI インフラストラクチャが必要です。その基盤として、多くの企業が NVIDIA DGX システムや、NVIDIA のソフトウェア ハブである NGC で入手できるCUDA-X、その他のソフトウェア コンポーネントを使用しています。
データ サイエンティストのためのライフサイクル追跡
AI インフラストラクチャが整備されていれば、企業のデータ センターは MLOps ソフトウェア スタックの以下の要素を階層化できます。
- データ ソースとそこから作られたデータセット
- 履歴と属性がタグ付けされた AI モデルのリポジトリ
- データセット、モデル、実験を、そのライフサイクルを通じて管理する、自動化された機械学習パイプライン
- これらのジョブの実行を簡略化するためのソフトウェア コンテナー (通常は Kubernetes をベースとする)
1 つのプロセスにまとめるには、関連する仕事がかなり多いと言えます。
データ サイエンティストには、外部ソースと内部のデータ レイクからのデータセットを切り貼りする自由が必要です。それでいて、その仕事とデータセットは注意深くラベル付けされ、追跡される必要があります。
同じように、タスクにすぐ使えるようよく調整された優れたモデルを作り上げるには、実験と反復が必要です。そのためには、柔軟なサンドボックスや堅固なリポジトリが必要になります。
また、データ サイエンティストがプロトタイプ、テスト、プロダクションを通してデータセットとモデルを運用する機械学習エンジニアと連携することも必要です。このプロセスでは、モデルを簡単に解釈し再現できるよう、自動化を行い、細部に注意を払うことが求められます。
現在、これらの機能はクラウドコンピューティング サービスの一部として利用できるようになってきました。機械学習を戦略的に重視する企業は、増え続けるベンダーが提供する MLOps サービスまたはツールを使って、独自の AI センター オブ エクセレンスを創設しています。
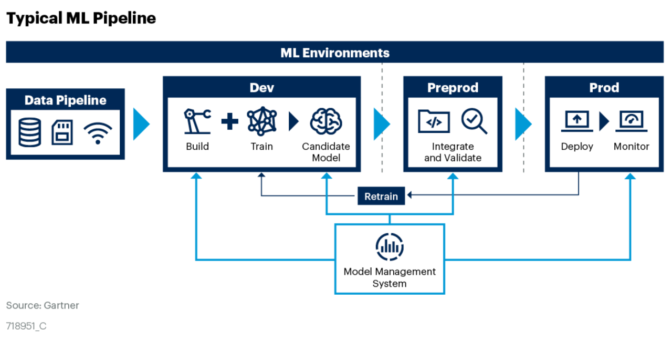 Gartner による機械学習パイプラインの考え方
Gartner による機械学習パイプラインの考え方
大規模なプロダクションにおけるデータ サイエンス
初期のころ、Airbnb、Facebook、Google、NVIDIA、Uber などの企業は、これらの機能を自分達で作らなければなりませんでした。
NVIDIA の AI インフラストラクチャ ディレクターであるニコラス コムチャツキー (Nicolas Koumchatzky) は次のように述べています。「可能なかぎりオープンソース コードを使おうとしましたが、多くの場合、私たちが大規模にやりたいと思っていることを実現するソリューションはありませんでした。
初めて MLOps という言葉を聞いたとき、まさに私たちがいま作っているものであり、私が以前 Twitter で構築していたものであると気づきました」
コムチャツキーのチームは NVIDIA で、NVIDIA DRIVE (自動運転車の製作とテストのためのプラットフォーム) をホストする MLOps ソフトウェアである MagLev を開発しました。MLOps のための基盤の一部として、MagLev は NVIDIA Container Runtime と Apollo (大規模なクラスターで実行されている Kubernetes コンテナーを管理、監視するために NVIDIA が開発したコンポーネント群) を使用しています。
Kubernetes コンテナーを管理、監視するために NVIDIA が開発したコンポーネント群) を使用しています。
NVIDIA で MLOps のための基盤を築く
コムチャツキーのチームは、DGX POD という GPU クラスターをベースにした NVIDIA の社内 AI インフラストラクチャ上でジョブを実行しています。ジョブを開始する前に、インフラストラクチャの担当者は自分たちがベスト プラクティスを用いているかどうかを確認します。
NVIDIA のマイケル ヒューストン (Michael Houston) は次のように述べています。まず、「すべてをコンテナーの中で実行する必要があります。そうすることで、AI アプリケーションに必要なライブラリやランタイムを後になって探し回るという途方もない苦労をせずに済みます」。ヒューストンのチームは、米国でトップクラスの強力な産業コンピューターに最近ランクインした Selene (DGX SuperPOD のひとつ) を含む、NVIDIA の AI システムを構築しています。
チームの他のチェックポイントとして、ジョブは以下のような点も満たさなければなりません。
- コンテナーの起動は承認済みの手順で行う
- ジョブが複数の GPU ノードにまたがって実行可能であることを確認する
- 潜在的なボトルネックを特定するためにパフォーマンス データを確認する
- ソフトウェアがデバッグ済みであることを確実にするためにプロファイル データを確認する
Neal Analytics で 1 年前に MLOps のコンサルティング業務を始め、MLOps の定義を述べる記事を書いたデータ サイエンティストのエドウィン ウェブスター (Edwin Webster) 氏によれば、今日のビジネスにおいて、MLOps プラクティスの成熟度は大きく異なるといいます。データ サイエンティストがいまだに個人のノート PC にモデルを保管している企業もあれば、全部入りのサービスを求めて大手のクラウドサービス プロバイダーに頼る企業もあるといいます。
MLOps の成功事例 2 つ
ウェブスター氏はクライアントの成功事例を 2 つ紹介してくれました。
1 つは大手の小売業者で、パブリック クラウド サービスの MLOps 機能を使って AI サービスを構築し、生鮮食料品をいつ在庫補充すべきかを毎日予測することによって、廃棄物を 8~9% 削減しました。小売業者の新進のデータ サイエンティスト チームがデータセットを作り、モデルを構築すると、クラウド サービスが主要な要素をコンテナーに詰め込み、AI ジョブを実行、管理しました。
もう 1 つは PC メーカーで、AI を使ったソフトウェアを開発し、自社製ノート PC のメンテナンスが必要になる時期を予測して、自動的にソフトウェア更新プログラムをインストールできるようにしました。この OEM メーカーは、定評ある MLOps プラクティスと社内のスペシャリストを活用して、3,000 台のノート PC で AI モデルを作成し、テストしました。現在では、最大の顧客に対してこのソフトウェアを提供しています。
Gartner でこの分野の動向を追っているシニア プリンシパル アナリストのシュバンギ バシスト (Shubhangi Vashisth) 氏は、Fortune 100 に含まれる企業の多くが、すべてとは言わないまでも、MLOps を採用していると述べています。「この流れは勢いを増していますが、まだ主流ではありません」
バシスト氏は共同執筆したホワイト ペーパーで、MLOps を始めるための 3 ステップをわかりやすく説明しています。それらは、ステークホルダーを目標に合わせて方向づける、誰が何の責任を持つかを明確にする組織体制を作る、その上で責任と役割を定義するというもので、Gartner は 10 以上の責任や役割を挙げています。
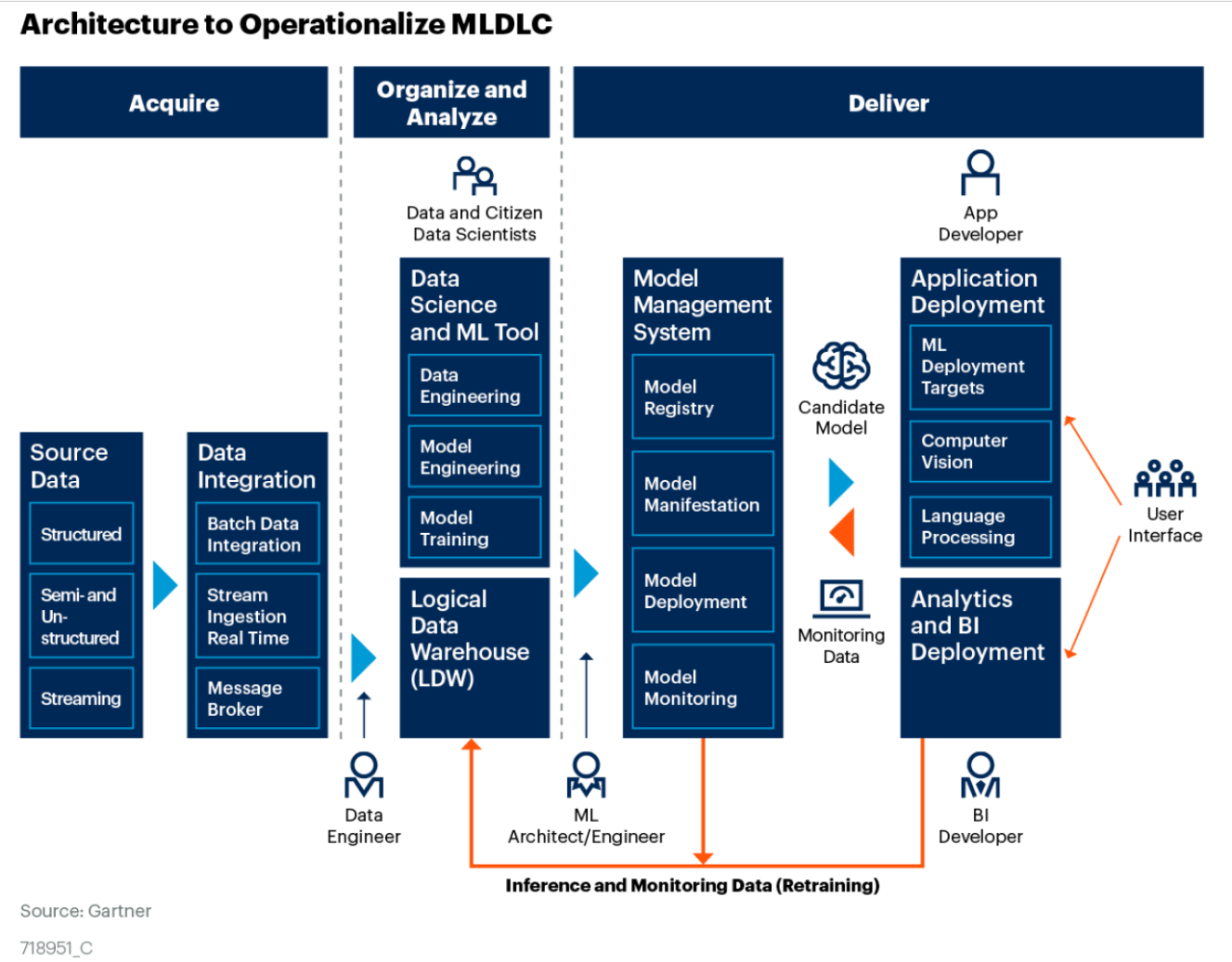 Gartner は、MLOps 全体のプロセスを機械学習開発ライフサイクル (MLDLC: machine learning development lifecycle) と呼んでいます。
Gartner は、MLOps 全体のプロセスを機械学習開発ライフサイクル (MLDLC: machine learning development lifecycle) と呼んでいます。
AIOps、DLOps、DataOps などのバズワードにご用心
この道に沿って広がってきたバズワードの森で迷子にならないようにしましょう。業界は間違いなく、MLOps の周りにエネルギーを集めています。
それに対して AIOps は、IT 部門の自動化のために機械学習を使うという、もっと狭いプラクティスです。AIOps の一部に、IT 運用分析、または ITOA (IT operations analytics) があります。このジョブでは、AIOps が生成するデータを調べて、IT 業務を改善するにはどうすればよいかを導き出します。
同じように、データセットと AI モデルを作成し管理する人やプロセスを表すために、それぞれ DataOps と ModelOps という言葉が考案されました。この 2 つは、MLOps というパズル全体の一部を成す重要なピースです。
興味深いことに、毎月何千人もの人々が DLOps の意味を検索しています。DLOps はディープラーニングのための IT 運用であると思われているのかもしれません。しかし、ディープラーニングは機械学習というもっと幅広い分野の一部であるため、業界では DLOps ではなく MLOps という言葉が用いられています。
検索は多くても、オンラインで DLOps についての情報を見つけるのは難しいでしょう。それに対し、おなじみの Google や Microsoft、新進気鋭の Iguazio や Paperspace などの企業は、MLOps について詳細なホワイトペーパーを掲載しています。
MLOps: 拡大を続ける種々のソフトウェアとサービス
MLOps の運用を他の誰かに任せたいと思っているユーザーには多くの選択肢があります。
Alibaba、AWS、Oracle などの主要なクラウドサービス プロバイダーは、キーボードからアクセス可能なエンドツーエンドのサービスを提供しています。
作業を複数のクラウドに分散しているユーザーのために、DataBricks の MLFlow が、複数のプロバイダーと、Python、R、SQL などの複数のプログラミング言語で動作する MLOps サービスをサポートしています。他にも、クラウドにとらわれない選択肢として、Polyaxon や KubeFlow などのオープン ソース ソフトウェアがあります。
戦略的なリソースである AI をファイアウォールの後ろで利用したいと考える企業は、ますます増えているサード パーティー製の MLOps ソフトウェアから選ぶことができます。オープンソース コードと比べると、これらのツールには一般的に有益な機能が追加されており、より簡単に使い始められます。
NVIDIA はその中から 6 社の製品を DGX-Ready ソフトウェア プログラムの一部に認定しました。
- Allegro AI
- cnvrg.io
- Core Scientific
- Domino Data Lab
- Iguazio
- Paperspace
ベンダー 6 社はデータセットとモデルの管理ソフトウェアを提供しており、そのすべてで Kubernetes や NGC との連携が可能です。
既製の MLOps ソフトウェアはまだ始まったばかりです。
アナリストのバシスト氏によれば、Gartner は、ModelOp や ParallelM (現在は DataRobot の一部) など 10 あまりのベンダーが MLOps ツールを提供していることを確認しています。プロセス全体が対象とはなっていない製品やサービスには注意が必要だと同氏は述べます。その場合、ユーザーがプログラム間でのデータのインポートとエクスポートを行い、自らつなぎ合わせなければならず、これらは面倒でエラーが発生しやすいプロセスです。
ネットワークのエッジ、特に部分的に接続されているノードや接続されていないノードは、現在の MLOps のサービスが十分に行き届いていない領域であると Neal Analytics のウェブスター氏は述べています。
NVIDIA のコムチャツキーは、コミュニティのために一番欲しいのはデータセットをキュレートし管理するためのツールだと言います。
「データセットのラベル付け、マージ、スライスや、部分的な閲覧は難しいかもしれませんが、それに取り組む MLOps のエコシステムは拡大しつつあります。NVIDIA はこれらを社内で開発してきましたが、業界ではまだ過小評価されていると思います」
長期的には、MLOps にも IDE に相当するもの、たとえばアプリ開発者が頼る Microsoft Visual Studio のような統合ソフトウェア開発環境にあたるものが必要となります。それまでの間、コムチャツキーとそのチームは、AI モデルを可視化しデバッグするツールを自分たちで作ります。
うれしいことに、MLOps を始めるための製品はたくさんあります。
NVIDIA はパートナーのソフトウェアに加え、DGX システムをベースとした AI インフラストラクチャを管理するための、主にオープンソースのツール群を提供しています。そして、それが MLOps の基盤となっています。これらのソフトウェア ツールには以下のようなものがあります。
- 個々のシステムをプロビジョニングするための Foreman と MAAS (Metal as a Service)
- クラスターの構成管理のための Ansible と Git
- 監視とレポート作成のための Data Center GPU Manager (DCGM) と NVIDIA System Management (NVSM)
- GPU に応じたコンテナーを起動するための NVIDIA Container Runtime と、Kubernetes での GPU 管理を簡略化するための NVIDIA GPU Operator
- AI モデルをプロダクションで展開するための Triton Inference Server と TensorRT
- 上記の要素をすべて展開しオーケストレートする方法に関するスクリプトと指示のための DeepOps
これらの多くは NGC や他のオープンソース リポジトリから入手可能です。これらの材料を成功へのレシピに整えて、NVIDIA は DGX POD という GPU クラスターを作るためのリファレンス アーキテクチャを提供しています。
最終的には、それぞれのチームが自らのユースケースに最も適した MLOps 製品とプラクティスの組み合わせを見つける必要があります。企業がデジタル ライフの日常の一部として、スムーズに AI を運用するために自動化された手法を作るというゴールを、みなが共有しています。