
ベンチマークは、パフォーマンスを測定するための重要なツールですが、急速に進化する分野では、最新の技術についていくのが困難な場合があります。最近、Intelは、発売が長らく予告されてきたXeon Phiプロセッサについて、一部誤った「事実」を公表しました。
現在、ディープラーニングほど進化の速い分野はほとんどありません。現在のニューラル・ネットワークは、ほんの2、3年前より6倍も深くなっており、よりパワフルです。さらに迅速なトレーニング・パフォーマンスを実現するマルチGPUスケーリングの新しい技術も登場しています。
さらに、NVIDIAのアーキテクチャやソフトウェアでは、KeplerからMaxwellを経て、8基のTesla P100 GPUを持つDGX-1など、最新のPascalベースのシステムに移行することにより、ニューラル・ネットワークのトレーニング時間がこの1年で10分の1未満に短縮されました。
そのため、この分野に新たに参入する企業が、ハードウェアとソフトウェアの両方の面でのあらゆる進展に精通していない可能性があるのはうなずけます。
たとえば、最近、Intelは、いくつかの古いベンチマークを公表し、Knights Landing Xeon Phiプロセッサを使用するディープラーニングのパフォーマンスについて、次のような3つの主張をしています。
- Xeon Phiは、GPUよりも2.3倍迅速なトレーニングが可能 (1)
- Xeon Phiは、ノード全体でGPUよりも38%優れたスケーリングを実現 (2)
- Xeon Phiは、GPUには不可能な128ノードへの強力なスケーリングを実現 (3)
私たちは、これらの主張を検討し、誤解を解きたいと思います。
新しいCaffe対古いCaffe
Intelは、18カ月前に公表されたCaffe AlexNetデータを使用し、4基のMaxwell GPUを搭載したシステムと4台のXeon Phiサーバを比較しました。より最近導入されたCaffe AlexNet(こちらで公表されています)を使用していれば、Intelも、4基のMaxwell GPUを搭載した同じシステムで、4台のXeon Phiサーバよりもトレーニングを30%高速に実行できることに気付いたでしょう。
実際、4台のXeon Phiサーバーよりも、4基のPascalベースのNVIDIA TITAN X GPUを搭載したシステムでは、90%高速にトレーニングを実行し、単一のNVIDIA DGX-1では5倍以上速くなります。
| System | Hours to Train | Speed-up vs Xeon Phi |
|---|---|---|
| PC with 4x NVIDIA TITAN X (Maxwell) *based on NVIDIA Caffe implementation as of March 2015 |
25 Hours | – |
| Four Xeon Phi servers | 10.5 Hours | – |
| PC with 4x NVIDIA TITAN X (Maxwell) *based on publicly available Caffe as of August 2016, cuDNN5 |
8.2 Hours | 1.3x faster than Xeon Phi |
| PC with 4x NVIDIA TITAN X (Pascal) *based on publicly available Caffe as of August 2016, cuDNN5 |
5.5 Hours | 1.9x faster than Xeon Phi |
| NVIDIA DGX-1 | 2 Hours | 5.3x faster than Xeon Phi |
38%優れたスケーリング
Intelは、Caffe GoogleNetのトレーニング・パフォーマンスを32台のXeon Phiサーバーとオークリッジ国立研究所にあるTitanスーパーコンピューターの32台のサーバーで比較しています。Titanは、4年前のGPU(Tesla K20X)と以前のJaguarスーパーコンピューターから引き継がれたインターコネクト・テクノロジを利用しています。一方、Xeon Phiのテスト結果は、最近のインターコネクト・テクノロジに基づいていました。
Baiduは、より最近のMaxwell GPUとインターコネクトを利用し、同社のスピーチ・トレーニングのワークロードが最高でGPU 128基までほぼ直線的に拡張されることを示しています。
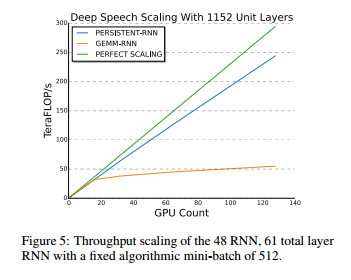
拡張性は、基盤となるプロセッサ同様、コード内のインターコネクトとアーキテクチャの最適化に依存します。GPUは、Baiduをはじめとするお客様に優れたスケーリングを提供しています。
128ノードへの強力なスケーリング
Intelは、128台のXeon Phiサーバーにより、1台のXeon Phiサーバーと比較し、50倍以上高速なパフォーマンスを提供可能であり、GPUにはこのようなスケーリングのデータは存在しないと主張しています。しかし、前述のように、Baiduは、既に最高128基のGPUまでほぼ直線的にスケール・アップした結果を示しています。
私たちは、強力なスケーリングには、脆弱なノードよりも強力なノードの方が適していると考えます。多くのパワフルなGPUを搭載する1台の強力なサーバは、Xeon Phiのように、各ノードがより処理能力の低いプロセッサのソケットを1つないし2つ備えた脆弱なノードの集まりよりも、優れたパフォーマンスを発揮します。たとえば、1つのDGX-1システムは、少なくとも21台のXeon Phiサーバーよりもさらに強力なスケーリング・パフォーマンスを発揮します(DGX-1は、4台のXeon Phiサーバーと比較し、5.3倍高速です)。
AIの時代
ディープラーニングには、コンピューティングに大変革を起こし、私たちの生活をより良いものにし、ビジネス・システムの効率性とインテリジェンスを向上させ、深い洞察を伴う方法で人類に役立つ進歩をもたらす可能性があります。そのため、私たちは、当社の並列プロセッサの設計を強化し、ソフトウェアとテクノロジを創造して、長年にわたりディープラーニングの性能向上を加速してきました。
ディープラーニングへの私たちの貢献は、深く、幅広いものです。どのフレームワークも、NVIDIAに最適な対応となっており、すべての主要なディープラーニング研究者、研究所、企業でNVIDIAのGPUが使用されています。
私たちが誤った主張をそれぞれ正すことはできますが、古いKepler GPUや旧式のバージョンのソフトウェアに対するディープラーニングのテストの実施は、業界を最新の状態に保つため、簡単に正すことのできる誤りです。
Intelが現在、ディープラーニングの研究を進めていることは素晴らしいことです。これは、近づいているAIの時代に最も重要なコンピューティング革命であり、ディープラーニングは、無視することのできない偉大な技術です。しかし、事実はきちんと確認する必要があります。