
- NVIDIA Blackwell は、新しい SemiAnalysis InferenceMAX v1 ベンチマークで圧倒的なパフォーマンスと最高の総合的な効率を実現
- InferenceMax v1 は、多様なモデルと実際のシナリオにおけるコンピューティングの総コストを測定する初の独立系ベンチマーク
- 最高の投資収益率:NVIDIA GB200 NVL72 は、比類のない AI ファクトリーの経済性を実現。500 万ドルの投資で 7,500 万ドルの DSR1 トークン収益を生み出し、投資収益率は 15 倍
- 最低の総所有コスト:NVIDIA B200 ソフトウェアの最適化により、gpt-oss で 100 万トークンあたり 2 セントを実現し、わずか 2 か月でトークンあたりのコストを 5 分の 1 に削減
- 最高のスループットとインタラクション性:NVIDIA B200 は、最新の NVIDIA TensorRT-LLM スタックを活用して、gpt-oss で GPU あたり毎秒 60,000 トークン、ユーザーあたり毎秒 1,000 トークンというペースを確立
AI が単発の回答から複雑なリーズニングへと移行するにつれ、推論への需要、そしてそれを支える経済性が爆発的に高まっています。
新しい独立系の InferenceMAX v1 ベンチマークは、実世界のシナリオにおけるコンピューティングの総コストを初めて測定しました。その結果は? NVIDIA Blackwell プラットフォームが圧倒的なパフォーマンスを発揮 し、AI ファクトリー のための比類のないパフォーマンスと最高の総合効率を実現したのです。
NVIDIA GB200 NVL72 システムへの 500 万ドルの投資は、7,500 万ドルのトークン収益を生み出す可能性があります。これは 15 倍の投資収益率 (ROI) に相当し、推論の新たな経済学と言えるでしょう。
NVIDIA のハイパースケールおよびハイパフォーマンス コンピューティング担当バイス プレジデントであるイアン バック (Ian Buck) は、次のように述べています。「推論は AI が日々価値を生み出す場所です。今回の結果は、NVIDIA のフルスタック アプローチが、お客様が AI を大規模に展開するために必要なパフォーマンスと効率性を提供していることを示しています」
InferenceMAX v1 の登場
SemiAnalysis が月曜日にリリースした新しいベンチマーク、InferenceMAX v1 は、Blackwell の推論におけるリーダーシップを際立たせる最新のベンチマークです。主要なプラットフォームで主流のモデルを実行し、幅広いユースケースのパフォーマンスを測定し、誰でも検証できる結果を公開しています。
このようなベンチマークがなぜ重要なのでしょうか?
それは、今日の AI が単なる速度ではなく、大規模な効率性と経済性を求められているからです。モデルがワンショットの応答から多段階のリーズニングとツールの使用へと移行するにつれて、クエリごとに生成されるトークンが大幅に増加し、コンピューティングの需要が劇的に増加しています。
NVIDIA と OpenAI (gpt-oss 120B)、Meta (Llama 3 70B)、DeepSeek AI (DeepSeek R1) とのオープンソース コラボレーションは、コミュニティ主導のモデルが最先端のリーズニングと効率性をどのように進化させているかを示しています。
これらの主要なモデル ビルダーやオープンソース コミュニティとコラボレーションをすることで、NVIDIA は最新のモデルが世界最大の AI 推論インフラ向けに最適化されていることを保証しています。こうした取り組みは、イノベーションの共有がすべての人の進歩を加速する、オープン エコシステムへの幅広いコミットメントを反映しています。
FlashInfer、SGLang、vLLM コミュニティとの緊密なコラボレーションにより、これらのモデルを大規模に駆動するカーネルとランタイムの強化が共同開発されています。
ソフトウェアの最適化により継続的なパフォーマンス向上を実現
NVIDIA は、ハードウェアとソフトウェアの協調設計による最適化を通じて、継続的にパフォーマンスを向上させています。NVIDIA TensorRT LLM ライブラリを搭載した NVIDIA DGX Blackwell B200 システムにおける gpt-oss-120b の初期のパフォーマンスは市場をリードするものでした。しかし、NVIDIA のチームとコミュニティは、オープンソースの大規模言語モデル向けに TensorRT LLM を大幅に最適化しました。
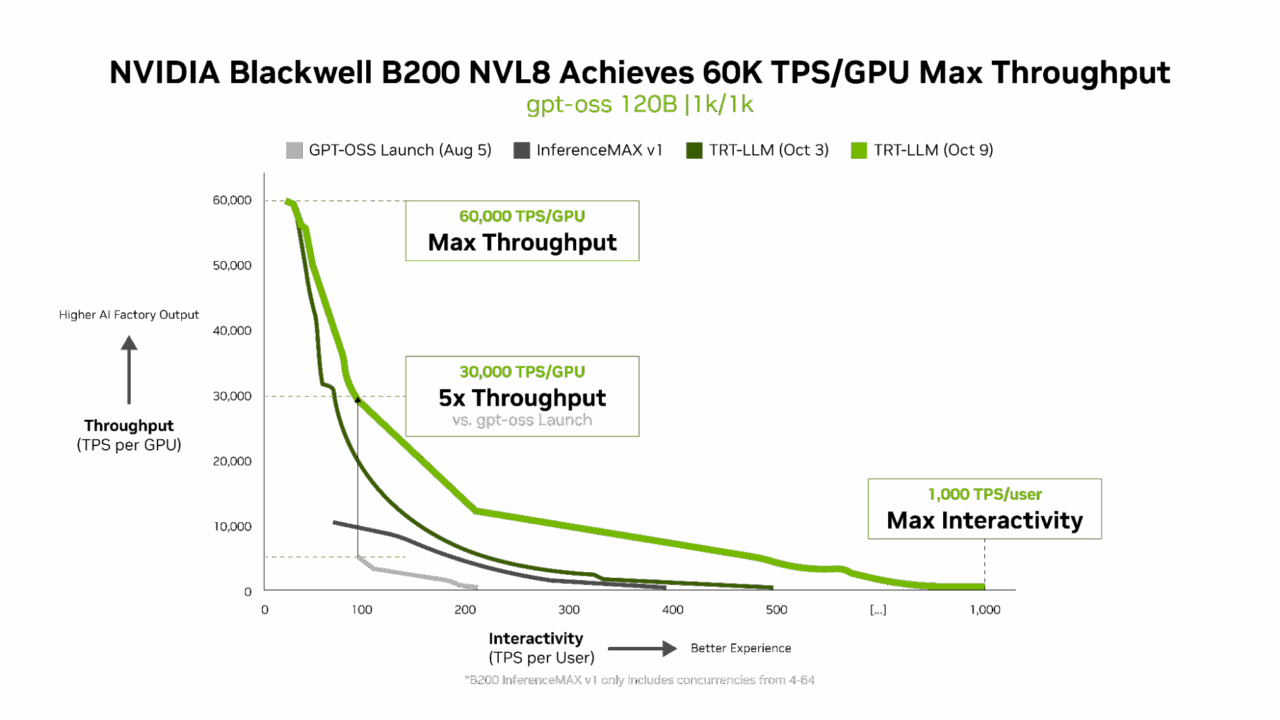
TensorRT LLM v1.0 のリリースは、大規模 AI モデルの高速化と応答性向上を実現する画期的な技術です。
高度な並列化技術により、B200 システムと NVIDIA NVLink Switch の毎秒 1,800 GB の双方向帯域幅を活用し、gpt-oss-120b モデルのパフォーマンスを飛躍的に向上させます。
イノベーションはそれだけではありません。新しくリリースされた gpt-oss-120b-Eagle3-v2 モデルでは、複数のトークンを一度に予測する優れた手法である投機的デコーディングが導入されています。これにより遅延が軽減され、より迅速な結果が得られます。スループットは 1 ユーザーあたり毎秒 100 トークン (TPS/ユーザー) と 3 倍になり、GPU あたりの速度は 6,000 トークンから 30,000 トークンに向上しています。
Llama 3.3 70B のような高密度 AI モデルは、パラメータ数が多く、推論中にすべてのパラメータが同時に使用されるため、膨大な計算リソースを必要とします。NVIDIA Blackwell B200 は、InferenceMAX v1 ベンチマークにおいて新たなパフォーマンス基準を確立しました。
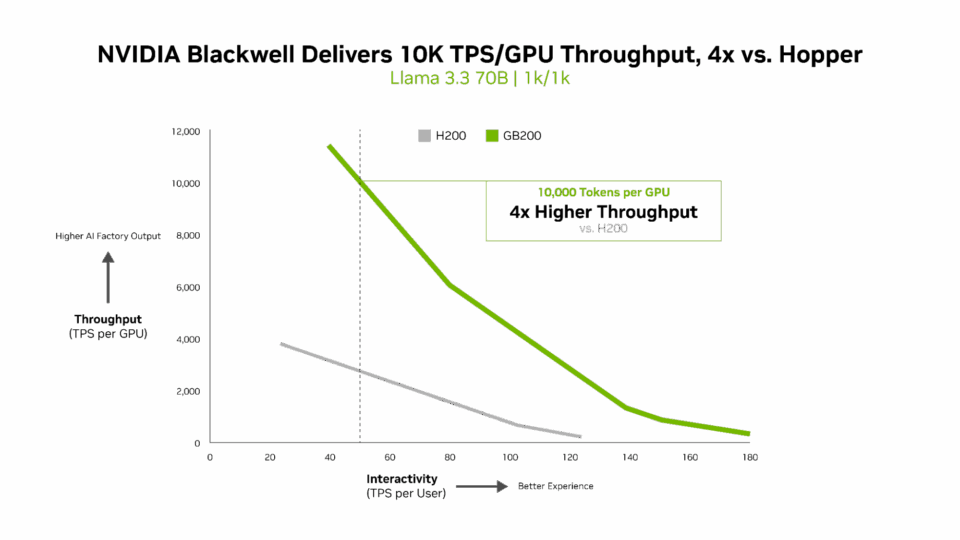
Blackwell は、ユーザーあたり 50 TPS のインタラクティブ性能で、GPU あたり 10,000 TPS 以上のパフォーマンスを実現します。これは、NVIDIA H200 GPU と比較して、GPU あたりのスループットが 4 倍高いことを意味します。
パフォーマンス効率が価値を左右する
ワットあたりのトークン数、100 万トークンあたりのコスト、ユーザーあたりの TPS といった指標は、スループットと同じくらい重要です。実際、電力制限のある AI ファクトリーにおいて、Blackwell は前世代と比較してメガワットあたりのスループットを 10 倍に向上し、トークン収益の増加につながります。
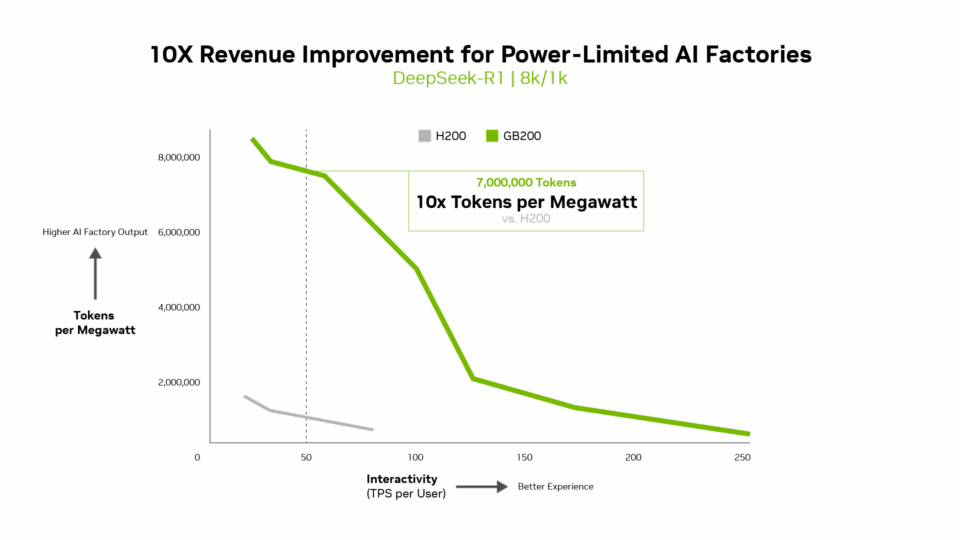
トークンあたりのコストは AI モデルの効率性を評価する上で非常に重要であり、運用コストに直接影響を及ぼします。NVIDIA Blackwell アーキテクチャは、前世代と比較して100 万トークンあたりのコストを 15 分の 1 に削減し、大幅なコスト削減を実現し、AI のより広範な展開とイノベーションを促進します。
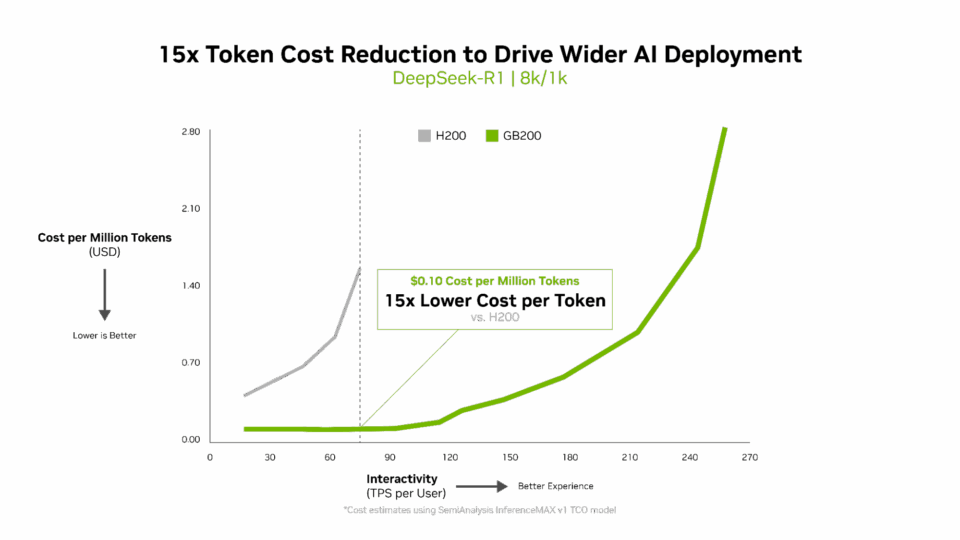
多次元的なパフォーマンス
InferenceMAX は、データセンターのスループットや応答性など、さまざまな要素間の最適なトレードオフを示す曲線であるパレート フロンティアを用いてパフォーマンスをマッピングしています。
しかし、これは単なるグラフ上のパフォーマンスではありません。NVIDIA Blackwell が、コスト、エネルギー効率、スループット、応答性といった、あらゆる運用上の優先事項のバランスをどのように取っているかを反映しています。このバランスにより、実際のワークロード全体で最高の ROI を実現できます。
単一のモードまたはシナリオのみに最適化されたシステムは、個別の状況では最高のパフォーマンスを発揮するかもしれませんが、その経済性は拡張性に欠けています。Blackwell のフルスタック設計は、最も重要な現場、つまり本番環境において効率性と価値を提供します。
これらの曲線がどのように構築されるのか、そしてなぜ総所有コスト (TCO) やサービス品質保証 (SLA) の計画において重要なのかを詳しく知りたい方は、こちらの技術ブログで詳細なチャートと手法をご覧ください。
パフォーマンスを実現する要素
Blackwell のリーダーシップは、究極のハードウェアとソフトウェアの協調設計から生まれています。これは、スピード、効率、そして拡張性を追求して構築されたフルスタック アーキテクチャです。
- Blackwell アーキテクチャの特徴:
- 精度を損なうことなく効率性を高める NVFP4 低精度フォーマット
- 72 基の Blackwell GPU を接続して 1 つの巨大な GPU として機能させる第 5 世代 NVIDIA NVLink
- 高度なテンソル、エキスパート、データ並列アテンション アルゴリズムにより高い同時実行性を実現する
NVLink Switch
- 毎年のハードウェア刷新と継続的なソフトウェアの最適化 ― NVIDIA は、Blackwell のローンチ以来、ソフトウェアのみでパフォーマンスを 2 倍以上に向上
- ピーク パフォーマンス向けに最適化された、NVIDIA TensorRT-LLM、NVIDIA Dynamo、SGLang、vLLM といったオープンソース推論フレームワーク
- 数億基の GPU の導入、700 万人の CUDA 開発者、そして 1,000 以上のオープンソース プロジェクトへの貢献を誇る、巨大なエコシステム
全体像
AI は実験的な段階から AI ファクトリーへと移行しています。AI ファクトリーとは、データをトークンやリアルタイムの意思決定に変換することでインテリジェンスを生み出すインフラです。
オープンで頻繁に更新されるベンチマークは、チームが情報に基づいたプラットフォームの選択を行い、変化するワークロード全体でトークンあたりのコスト、レイテンシに関するサービス品質保証、そして利用率を調整するのに役立ちます。
NVIDIA の Think SMART フレームワークは、企業がこの変化を乗り越えるのを支援し、NVIDIA のフルスタック推論プラットフォームが、パフォーマンスを利益に変え、現実世界の ROI を実現する方法に焦点を当てています。