
最新のチップ設計にはAI、エッジ、ハイパフォーマンス コンピューティングにおける NVIDIA のプラットフォーム イノベーションの幅広さと奥深さが反映される
2 日間にわたる 4 つの講演で 、NVIDIA のシニア エンジニアが、最新のデータセンターとネットワークのエッジのシステム向けの アクセラレーテッド コンピューティングにお ける イノベーションについて説明します。
プロセッサおよびシステムのアーキテクトが集まる、年に 1 度の オンライン開催の Hot Chips イベントにおいて、NVIDIA の 初のサーバー CPU、Hopper GPU、NV Switch インターコネクト チップの最新バージョン、および NVIDIA Jetson Orin システム オン モジュール (SoM) のパフォーマンス値とその他の技術的詳細が公開され ます。
プレゼンテーションでは、NVIDIA プラットフォームが新 たなレベルのパフォーマンス、効率、スケール、およびセキュリティをどのように実現するかについての最新の洞察を説明します。
具体的には、GPU、CPU および DPU が ピア プロセッサとして機能する、チップ、システム、およびソフトウェア のフルスタックにわた る 革新的な 設計思想 について 説明し ます。これらが一緒になることで、クラウド サービス プロバイダー、スーパーコンピューティング センター、企業のデータセンター、自律動作システムにおいて AI、データ分析、ハイパフォーマンス コンピューティングのジョブを 実行しているプラットフォームを作り出します。
NVIDIA の初のサーバー用 CPU の内部
データセンターでは、現在のワークロードが要求する エネルギー効率の高いパフォーマンスを提供するために、大量のメモリ プールを共有する CPU、GPU、およびその他のアクセラレータの柔軟なクラスター が必要と されています。
そのニーズを満たすために、 NVIDIA の Distinguished Engineer で 15 年のキャリアをもつ ジョナソン エヴァンス (Jonathon Evans) が、NVIDIA NVLink-C2C について説明します。これは、CPU と GPU を毎秒 900 ギガバイト で接続し、既存の PCIe Gen 5 規格の 5 倍のエネルギー効率 となる 1 ビットあたりわずか 1.3 ピコジュール (pJ) の データ転送を実現します。
NVLink-C2C は 2 つの CPU チップを接続して、144 個の Arm Neoverse コアを備えた NVIDIA Grace CPUを作り出し ます。これは、世界最大のコンピューティング問題を解決するために構築されたプロセッサです。
Grace CPU では、最大の効率を得るために LPDDR5X メモリが使われ ます。これにより、全体の消費電力を 500 W に抑えながら、毎秒 1 テラバイトのメモリ帯域幅を実現します。
1 つのリンクでさまざまな用途に
また、NVLink-C2C は、NVIDIA Grace Hopper Superchip のメモリ共有ピアとして Grace CPU と Hopper GPU チップをリンクし、AI トレーニングなど パフォーマンスを必要とするジョブを最大限に高速化します。
誰でも NVLink-C2C を使用してカスタム チップレットを構築し、NVIDIA GPU、CPU、DPU、および SoC にコヒーレントに接続して、この新しいクラスの統合製品を拡張することができます。インターコネクトは、Arm および x86 プロセッサでそれぞれ使用される AMBA CHI および CXL プロトコルをサポートする予定です。
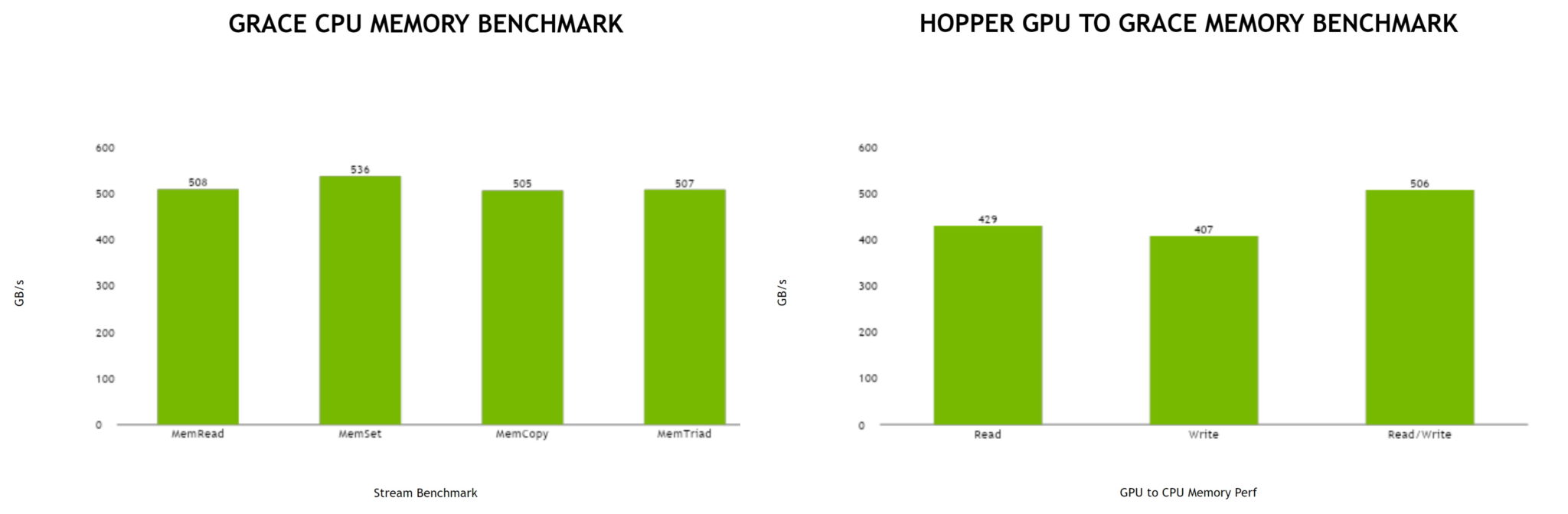 Grace と Grace Hopper の最初のメモリ ベンチマーク。
Grace と Grace Hopper の最初のメモリ ベンチマーク。システム レベルでスケーリングするために、新しい NVIDIA NVSwitch を使って 複数のサーバーを 1 つの AI スーパーコンピューターに接続することができ ます。これには、PCIe Gen 5 の 7 倍以上の帯域幅を持つ 、毎秒 900 ギガバイト で動作 する NVLink インターコネクト が使われます 。
NVSwitch により 、ユーザーは 32 台の NVIDIA DGX H100 システムを AI スーパーコンピューターにリンクして、エクサフロップスのピーク AI パフォーマンスを実現 できます。
NVIDIA のベテラン エンジニアである アレクサンダー イシイ (Alexander Ishii) とライアン ウエルズ (Ryan Wells) が、ユーザーが最大 256 基の GPU を備えたシステムを構築して、1 兆を超えるパラメーターを持つ AI モデルのトレーニングなどの要求の厳しいワークロードに取り組む方法について説明します。
このスイッチには、NVIDIA Scalable Hierarchical Aggregation Reduction Protocol (SHARP) を使用してデータ転送を高速化するエンジンが含まれています。SHARP は、NVIDIA Quantum InfiniBand ネットワークで登場したインネットワーク コンピューティング機能であり、通信量の多い AI アプリケーションのデータ スループットを 2 倍にすることができま す。
 NVSwitch システムは、エクサフロップス (EFLOPS) クラスの AI スーパーコンピューターを実現します。
NVSwitch システムは、エクサフロップス (EFLOPS) クラスの AI スーパーコンピューターを実現します。NVIDIA 勤続 14 年の Senior Distinguished Engineer 、ジャック ショケット (Jack Choquette) が、Hopper こと NVIDIA H100 Tensor コア GPU の詳細を説明 します。
Hopper には、新しいインターコネクト を使用して、前例のない高さにスケーリングすることに加えて、アクセラレータのパフォーマンス、効率、およびセキュリティを向上させる多くの高度な機能が搭載されています。
Hopper の新しい Transformer Engine とアップグレードした Tensor コアは、世界最大のニューラル ネットワーク モデルによる AI 推論において 前世代と比較して 30 倍の 高速化を実現します。また、世界初の HBM3 メモリ システムを採用し 、3 TB のメモリ帯域幅を実現します。これは、NVIDIA の史上最大となる 世代間の飛躍です。
その他の新機能:
- Hopper では、マルチ テナント、マルチ ユーザー構成の仮想化サポートが追加。
- 新しい DPX 命令は、選択マッピング、DNA およびタンパク質分析アプリケーションの繰り返しループを高速化。
- Hopper では、コンフィデンシャル コンピューティングによる強化されたセキュリティパックのサポートが追加。
初期の NINTENDO64 コンソールのリード チップ デザイナーを務めたショケット が、Hopper の進歩の根底にある並列 コンピューティング技術についても説明します。
NVIDIA に在職 17 年 で、Orin のチーフ アーキテクトであるマイケル ディッティ (Michael Ditty) は、エッジ AI、ロボティクス、高度な自律動作 マシンのエンジンである NVIDIA Jetson AGX Orinの新しいパフォーマンス仕様を説明します。
これは 12 個の Arm Cortex-A78 コアと NVIDIA Ampere アーキテクチャ GPU を統合し、AI 推論ジョブで最大 毎秒 275 兆回の演算 を実行します。これは、前世代よりも 2.3 倍のエネルギー効率で、パフォーマンスも最大 8 倍となります。
最新の量産モジュールは、最大 32 GB のメモリを搭載し、ポケット サイズ で 5W の Jetson Nano 開発者キットにまで縮小できる互換性のあるファミリの一部です。
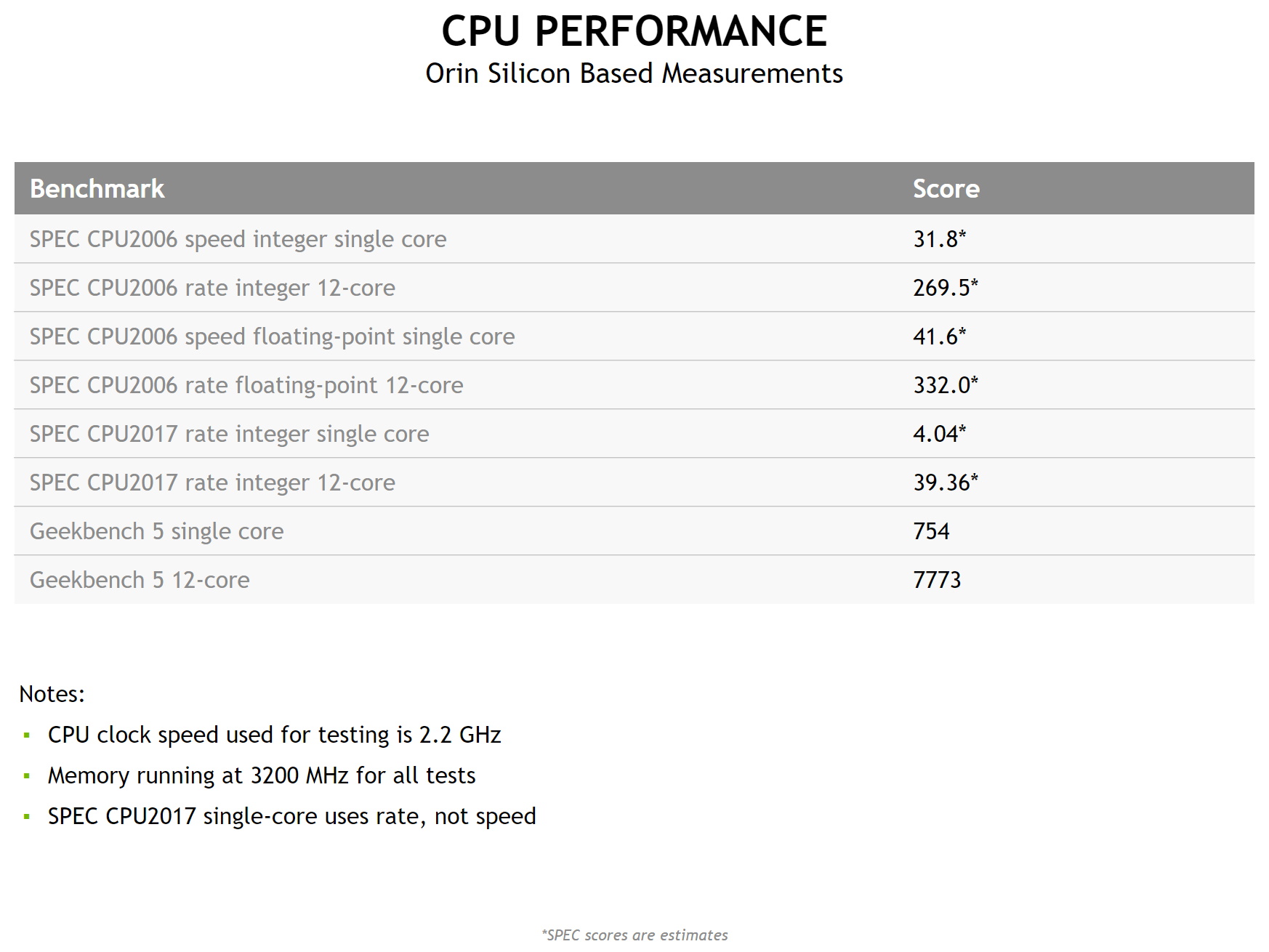 NVIDIA Orin のパフォーマンス ベンチマーク
NVIDIA Orin のパフォーマンス ベンチマークすべての新しいチップは、700 以上のアプリケーションを高速化し、250 万人の開発者が使用する NVIDIA ソフトウェア スタックをサポートしています。
CUDA プログラミング モデルに基づいており、自動車 (DRIVE) やヘルスケア (Clara) などの垂直市場向けの数十の NVIDIA SDK と、レコメンデーション システム (Merlin) や対話型 AI (Riva) などのテクノロジが含まれています。
NVIDIA AI プラットフォームは、すべての主要なクラウド サービスおよびシステム メーカーから提供されています。