 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
テキスト処理テクノロジの改良に NVIDIA GPU を活用
BERT がヨーロッパで実用され、NVIDIA 製品およびパートナーたちの支援のもと、複数の業界と言語で自然言語処理の仕事に取り組んでいます。
Bidirectional Encoder Representations from Transformers (Transformer による双方向エンコード表現) として知られる AI モデルは、テキスト向け機械学習の最先端のアプローチとして、昨年登場したばかりです。ドイツ語およびスウェーデン語のための最適化を行った開発者たちによれば、まだ新しいにもかかわらず、BERT はすでに、ヨーロッパの航空電子工学、金融、半導体および電気通信の企業で使用されています。
「BERT にはとても多くのユースケースがあります。テキストは企業の持つ最も一般的なデータ型の 1 つであるからです。」と言うのは、ストックホルムの開発会社、Peltarion の研究責任者である、アンデシュ アルプテグ (Anders Arpteg) 氏です。Peltarion は、BERT のような最新の AI 手法を企業が安価で簡単に導入できるようになることを目指しています。
自然言語処理は、コンピューター ビジョンにおける現在の AI の仕事を上回る速度で進歩しています。その理由について、ベルリンにある deepset のチーフ エグゼクティブ、ミロス ルジック (Milos Rusic) 氏は、次のように述べています。「テキストには、画像よりもはるかに多くのアプリケーションがあります。その仮説に基づいて私たちはこの会社を立ち上げました。BERT は革命であり、私たちにとって大きな意味を持つ画期的な出来事です。」
deepset は PricewaterhouseCoopers と共同で、半導体メーカーInfineon のストラテジストが膨大な年次報告書とマーケット データを精査して、重要な洞察を得るためのシステムを BERT を使って構築しています。別のプロジェクトでは、製造企業が NLP (自然言語処理) を使って文書を検索し、製品のメンテナンスを迅速化し、必要な修理を予測しています。
NVIDIA のテクノロジおよびエコシステムを利用できるようにしてスタートアップ企業を育成する、NVIDIA の Inception プログラムのメンバーである Peltarion は、11 月に自社のツールを BERT に対応させました。同社は、大手電気通信企業が製品およびサービスへの要求に対応するためのプロセスの一部を自動化するのを支援するために、すでに NLP を使用しています。さらに同社は、このテクノロジによって大手のマーケット調査企業が調査のデータベースをより簡単に照会できるようにしています。
ローカリゼーション作業
Peltarion は 他の 3 つの組織とともに、BERT をスウェーデン語に最適化する政府が支援する 3 年間のプロジェクトに取り組んでいます。興味深いことに、XLM-R と呼ばれる Facebook の新しいモデルでは、複数の言語を同時にトレーニングする方が、1 つの言語だけで最適化するより効果的である可能性が示唆されています。
「初期の結果では、Facebook が 1 度に 100 の言語でトレーニングを行った XLM-R は、スウェーデン語でトレーニングしたオリジナルのBERTのパフォーマンスを大幅に上回っていました」とアルプテグ氏は述べています。彼のチームは、この分析についての論文を作成しています。
それでも、3 年前に Peltarion に入社するまで Spotify で AI 研究グループを率いていた アルプテグ氏によると、本当にうまく機能するスウェーデン語の BERT モデルを夏までに実現しようとしています。
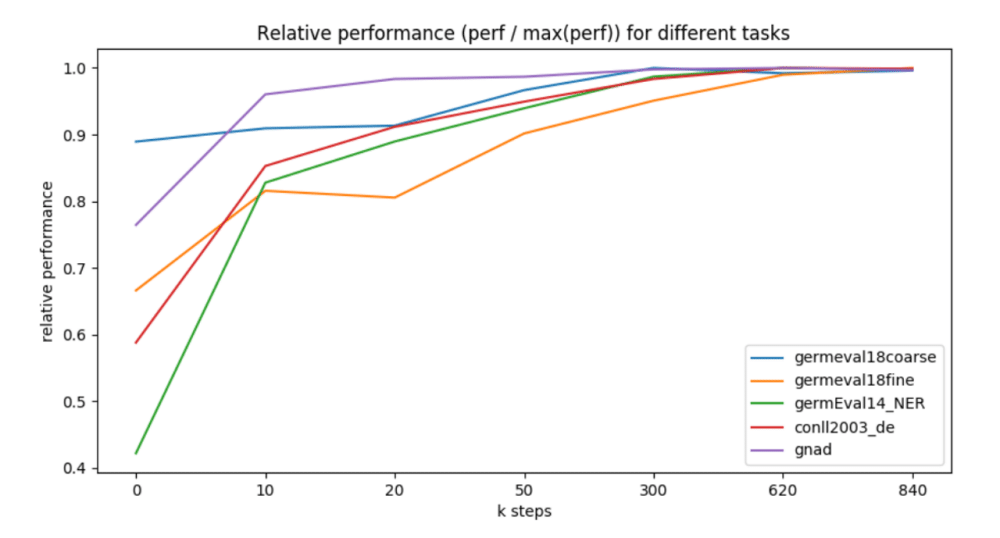 BERT ドイツ語バージョンについての deepset の分析
BERT ドイツ語バージョンについての deepset の分析6 月、deepset はドイツ語に最適化された BERT をオープンソースとして公開しました。そのパフォーマンスはオリジナルのモデルと比べて数パーセント向上しただけですが、ドイツの年次NLP コンペティション の受賞 2 団体が deepset のモデルを使用していました。
仕事に適したツール
アルプテグ氏によれば、BERT はテキストの分類や質問応答、感情分析といった、特定のタスクに最適化するのにも適しています。Peltarion の研究者たちは、医療や法務といった、独自の用語を持つ分野に合わせて BERT を調整することで得られる改善についての分析結果を 2020 年に公開する予定です。
質問応答のタスクは deepset にとって非常に戦略的に重要になったため、その仕事に対処するための同社の転移学習フレームワークである FARM の 1 バージョンとして、Haystack を構築しました。
ハードウェア面では、最新の NVIDIA GPU が、大規模な NLP のトレーニングを行うために使用されているツールとして選ばれています。BERT のトレーニング時間の短縮で NVIDIA が先頃新記録を樹立したことを考えれば、それも驚きではありません。
「オリジナルの BERT には 1 億のパラメータがあり、XML-R には 2 億 7,000 万のパラメータがあります」とアルプテグ氏は言います。アルプテグ氏のチームは先頃、NVIDIA Quadro と TITAN GPU と最大 48 GB のメモリを持つシステムを購入しました。このチームは、NVIDIA DGX-1 サーバーも利用しています。その理由を、「言語モデルのトレーニングを 1 から始めるには、このような超高速システムが必要です」と同氏は説明しています。
メモリは大きいほど良い、とルジック氏は述べています。彼のドイツ語版 BERT モデルは、400MB のサイズです。deepset は、クラウドで NVIDIA V100 Tensor コア 100 GPU を使い、ローカルでは別の NVIDIA GPU を採用しています。







