 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
インテリジェント・マシンに複雑なAIとディープラーニング機能を追加することが、はるかに容易になりました。
そのために必要なものは、現在無料でダウンロードできるNVIDIA JetPack 2.3のみです。Jetson TX1に対する開発者用のツールとライブラリの最新ソフトウェア・スイートは、組み込みシステム上で、世界で最もパフォーマンスの高いディープラーニングのプラットフォームを提供し、スピードと効率を倍増させます。
複雑なディープ・ニューラル・ネットワークを運用する機能は、インテリジェント・マシンが、治安、スマートな都市、製造、災害救助、農業、輸送、インフラストラクチャの検査などの重要な分野で、実世界の問題を解決するために不可欠です。
オールインワン・パッケージ
JetPack 2.3オールインワン・パッケージは、すべてのシステム・ソフトウェア、ツール、最適化されたライブラリとAPIをバンドルし、インストールします。また、開発者が革新的な設計をすばやく実現して実行できるよう、サンプルも付属しています。
このリリースには、次のような主な機能があります。
- TensorRT: 以前はGIEと呼ばれていたTensorRTは、画像の分類、セグメント化、オブジェクトの検出などの用途のために、リアルタイム・パフォーマンスを最大限に高めるディープラーニング推論エンジンです。これを利用すると、開発者はJetsonでサポートされるリアルタイム・ニューラル・ネットワークを展開できます。これは、以前のcuDNNの実装に比べて、ディープラーニングのパフォーマンスを倍増させます。
- cuDNN 5.1: 畳み込み、アクティベーション機能、テンソル変換などの標準ルーチンに対して、高度に調整された実装を提供するディープラーニング用のCUDAアクセラレーション・ライブラリです。LSTMやRNNなどの高度なネットワーク・モデルのサポートも、このリリースに含まれています。
- マルチメディアAPI: 柔軟なアプリケーション開発に最適な低レベルAPIのパッケージ。これには、次のAPIが含まれています。
- カメラAPI: カメラのパラメータとEGLストリーム出力に対するフレームごとの制御。これにより、GStreamerパイプラインやV4L2パイプラインとの効率的な相互運用が実現します。このカメラAPIは、MIPI CSIを通じてカメラ・センサーに接続するための低レベル・アクセスを開発者に提供します。
- V4L2 API: 動画のデコード、エンコード、フォーマット変換、拡大縮小の機能。エンコード用のV4L2は、ビット・レート制御、品質プリセット、低遅延エンコード、一時的トレードオフ、動きベクトル・マップなどの機能に対して低レベル・アクセスを提供します。以前のリリースからのGStreamerの実装もサポートされています。
- CUDA 8: この最新リリースでは、アップデートされたGCC 5.xのホスト・コンパイラがサポートされています。NVCC CUDAコンパイラは、最大2倍に高速化されたコンパイルを行えるよう最適化されました。CUDA 8には、グラフ・アナリティクスのアクセラレーテッド・ライブラリであるnvGRAPHも含まれています。CUDAカーネルの半精度浮動小数点数の計算に対する新しいAPIとcuFFTライブラリも追加されました。
新しいパートナーシップ
また、NVIDIAは、組み込みマシンのビジョン・アプリケーション向けのステレオ深度マッピング、インテリジェント・マシンを実現するカメラ、消費者向け製品など、カメラ・ソリューションの作成を専門とするJetson優先パートナーであるLeopard Imaging Inc.と協力しています。
開発者は、YUVセンサーで今日利用できるISPバイパス・イメージング・モードに加えて、CSIまたはUSBインターフェースを通じてNVIDIAの内部オンチップISPや外部ISPを使用する一方で、Leopard Imaginingと協力して複数のRAWイメージ・センサーを簡単に統合できます。Jetpack 2.3に含まれる新しいカメラAPIは、この統合を容易にするための拡張機能を提供します。
今すぐJetPack 2.3をダウンロードしてください。
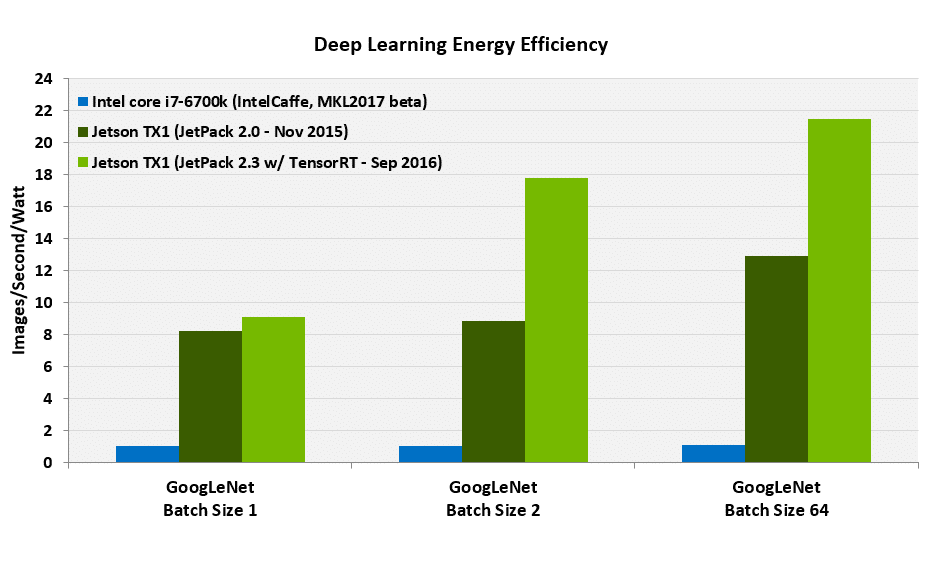
図の脚注:
- 効率は、以下のホワイト・ペーパーに概要を示す方法を使用して測定しました。
- Jetson TX1の効率は、691 MHzのGPU周波数で測定しました。
- Intel Core i7-6700kの効率は、4 GHz CPUクロックで測定しました。
- Jetpack 2.0で実行できる最大値を考慮し、GoogLeNetバッチ・サイズは64に制限されました。Jetpack 2.3とTensorRTでは、より高いパフォーマンスのために、GoogLeNetバッチ・サイズ=128もサポートされています。
- FP16ではFP32に比べて分類精度の低下が生じないため、Jetson TX1に対するFP16の結果は、Intel Core i7-6700kに対するFP32の結果と同等です。
- 一般に入手可能な最新のIntelCaffeとMKL2017 betaのソフトウェア・バージョンを使用しました。
Jetpack 2.0とIntel Core i7では、重み付けと入力画像の両方に対して、ゼロ以外のデータを使用しました。Jetpack 2.3(TensorRT)では、実際の画像と重み付けを使用しました。







