
世界最大級のスーパーコンピューターやデータセンターを加速するネットワーク技術が今年トップクラスの合併を生み、AI の進化に拍車をかける
高速ネットワークを実現する優れたアイデアでありながらも人目につかなかったリモート ダイレクト メモリ アクセス (RDMA) が、世界最速のスーパーコンピューターのジェット燃料へと上り詰めるまでには、2 つの偶然の出会いがありました。
それらの幸運の始まりは、RDMA ベースのネットワークである InfiniBand に社運をかけていたイスラエル拠点のスタートアップに訪れた運命的な縁でした。後に、そのスタートアップである Mellanox Technologiesは、RDMA をメインストリーム コンピューティング、現在の AI ブーム、そして IT 業界でこのほど行われた数十億ドル規模の合併へと導く一翼を担うようになります。
事の起こりは 2001 年 8 月。
オハイオ州立大学の教授である D.K. パンダ (D. K. Panda) 氏が、創業間もない Mellanox のマーケティング担当バイス プレジデントであるケビン デイアリング (Kevin Deierling) 氏と出会います。パンダ氏は、MPI (Message Passing Interface) 用ソフトウェアに関する、自身の研究室で行っている研究が、いかにハイパフォーマンス コンピューティング向けに低コストなシステムをクラスター構築するトレンドを加速しているかについて説明しました。
しかし問題は、研究室で使用していた Myrinet や Quadrics といった小さな企業の高速ネットワークが独自仕様で、コストがかかることでした。
それはわずかな元手のスタートアップにとって簡単な取引でした。同社の初期の InfiniBand カード数枚と、ピザ、そしてジョルト コーラの価格で、大学院生らはMellanox のチップ上で MPI を実行させることができました。InfiniBand に注目していた米国の各国立研究所も支援に乗り出しました。そしてパンダ氏のチームは、「Supercomputing 2002」カンファレンスでオープン ソースの「MVAPICH」を初披露しました。
「チームは Myrinet や Quadrics よりも性能を向上させたので、雪だるま式な効果がありました」と、最近 50 万ダウンロードというマイルストーンを突破したこのソフトウェアの生みの親であるパンダ氏は言います。
「Big Mac」に RDMA を振りかける
そのデモは、バージニア工科大学でコンピューター サイエンスの助教授を務める意欲的な人物の創造力をかき立てました。スリニディ バラダラジャン (Srinidhi Varadarajan) 氏は、自身が構築した低コストの 80 ノードのクラスターを使用する複数の研究グループをキャンパス内で立ち上げていましたが、それは準備段階にすぎませんでした。
最先端技術の熱烈な支持者であるバラダラジャン氏は、IBM の堅牢な HPC コンピューターの遺産に裏打ちされた、世界をリードする浮動小数点性能を誇る最新の 2-GHz CPU である IBM の PowerPC 970 に狙いを定めます。まさに Apple がこの CPU を 2 基搭載した Power Mac G5 デスクトップを発表しようとしていたところでした。
大学や政府補助金から資金を得たバラダラジャン氏は、とある金曜日に地元の Apple 販売店に 1,100 台のシステムを注文します。「日曜の朝には、スティーブ ジョブズから月曜に直接会いたいという電話をもらいました」と、バラダラジャン氏。
当初から Mac を InfiniBand で接続したいと考えていたバラダラジャン氏は、「HPC アプリは遅延の影響を受けやすいので、高帯域幅、低遅延を実現する必要がありました。InfiniBand はその問題を解決する最先端の手段となると考えました」と説明します。
InfiniBand スーパーコンピューターの周りに陣取る Mellanox
Mellanox はその新たな最大の顧客にファーストクラスのサポートを提供し、CTO のマイケル ケーガン (Michael Kagan) 氏がシステムの設計を支援することになりました。
ケーガン氏のチームに所属するアーキテクトであったドロール ゴールデンバーグ (Dror Goldenberg) 氏は、イスラエルのハイファにほど近い Mellanox 本社の自席でランチをとっていたときに、そのプロジェクトの話を耳にして、直接プロジェクトに参加したいと考えました。
その夜にはシリコン バレーに飛び、それから 3 週間、One Infinite Loop (カリフォルニア州クパチーノにある Apple の本社) にある極秘のラボに泊まり込みます。そこでゴールデンバーグ氏は、同社初の Mac 用ドライバの開発を手伝いました。
 ゴールデンバーグ氏と、構築中の「Big Mac」内部の InfiniBand 配線
ゴールデンバーグ氏と、構築中の「Big Mac」内部の InfiniBand 配線
「そこが Mac G5 のプロトタイプにアクセスできた唯一の場所でした」と、秘密主義で有名な企業に身を置いたゴールデンバーグ氏は述べています。
Apple ではバージニア工科大学の研究者チームと、イスラエルに戻ってからは Mellanox のエンジニア チームと昼夜なしに働いたゴールデンバーグ氏は、まったく新しいプロセッサ アーキテクチャ上で会社のネットワークを実行させることに成功します。
次のステージでは、歴史的に有名な規模の問題に直面しました。ゴールデンバーグ氏らは、バージニア工科大学のサーバー ルームに何週間も滞在し、コンピューターを前代未聞の高さにまで積み上げました。そのころはまだ、「Amazon」と聞けば大半の人が熱帯雨林を連想するような時代です。
「きわめて大規模な場合のみにクラッシュが発生しましたが、小規模では問題を再現できませんでした」とゴールデンバーグ氏は言い、「本社に電話して異常なビット エラーについて聞いてみましたが、意味がわからないと言われました」と続けます。
コンピューター サイエンスにおける前例のない問題に活気づいたチームは、1 日 22 時間研究に没頭する日々を過ごすことも少なくありませんでした。世界最大級のスーパーコンピューターが名を連ねる「TOP500」ランキングの記録を破る競争の中で、2.3 マイルに及ぶ InfiniBand ケーブルの間に寝袋を置いて仮眠をとることもありました。
1,100 台もの市販のコンピューターを 1 つにつなぎ合わせたことで、「誰も見たことがないレベルにまでシステムにストレスをかけることになりました」とゴールデンバーグ氏。
「今なら、そのような大規模なジョブを実行すれば、熱が上がり、ファンが悲鳴を上げ、ケーブルのトラフィック パターンが変化して、ビット反転が生じる可能性がある異なる周波数が発生することがわかっています」と、今や顧客に世界最大のクラウド サービス プロバイダーを持つソフトウェア アーキテクチャを担当する熟練のバイス プレジデントとなったゴールデンバーグ氏は話します。
RDMA が 10 テラフロップスを超える処理能力を実現
「バラダラジャン氏は教授でありながらオブジェクト コードを書くクレイジーな人でした」と、ケーガン氏は振り返ります。
ベンチマークは 9.3 テラフロップスあたりで停滞し、「System X」という名前の由来となった目標にわずかに届きませんでした。「結果はほぼ毎日変化していました。残された時間は最後の週末の 2 日間でしたが、日曜日の夜の実行で突然 10.3 テラフロップスをたたき出したのです」と、バラダラジャン氏は語ります。
この 520 万ドルのシステムは、2003 年 11 月に TOP500 の 3 位にランクインしました。当時最速のシステムは日本の「地球シミュレータ」で、そのコストはおよそ 3 億 5,000 万ドルでした。
 バージニア工科大学に設置されて間もない System X を操作するスリニディ バラダラジャン氏
バージニア工科大学に設置されて間もない System X を操作するスリニディ バラダラジャン氏
「それが私たちの HPC でのデビューでした」と話すケーガン氏は、次のように付け足します。「今では TOP500 のシステムの半数以上が当社の RDMA 対応のチップを採用しており、HPC は当社のビジネスのかなりの部分を占めています」
RDMA の誕生は 1993 年 11 月
これはこのスタートアップにとっても大きなチャンスで、RDMAのアイデアは Hewlett-Packard のエンジニア チームによって 1993 年 11 月の特許で初めて成文化されました。
多くの先進技術がそうであるように、RDMA の背景にあるアイデアもまたシンプルかつ基本的なものでした。ネットワーク化されたシステムが、プロセッサやオペレーティング システムを邪魔することなく互いのメイン メモリにアクセスできるようにすれば、遅延を抑え、スループットを向上させ、人々の生活を楽にすることができるというものです。
この方法は、コンピューターの速度を低下させていたシステム間を往復する無秩序のトラフィックを解消する手立てとなることが期待されました。
RoCE: RDMA がメインストリームへ
スーパーコンピューターで最初の成功を収めた後、RDMA を成熟したメインストリームのイーサネット ネットワークへと組み入れることは必然的な次のステップでしたが、それには大変な労力と時間がかかりました。InfiniBand Trade Association は、2010 年に RDMA over Converged Ethernet (RoCE、「ロッキー」と発音) の初めてのバージョンを、2014 年にルーティングに対応する現在のより完成されたバージョンを定義しました。
Mellanox はその仕様の策定に協力し、RoCE を ConnectX という InfiniBand の高データ レートにも対応するチップ ファミリーに採用しました。
The Linley Group のネットワーク アナリストであるボブ ウィーラー (Bob Wheeler) 氏は、「その結果、同社は 25/50G と 100G のイーサネットで先駆けとなりました。ハイパースケール データセンターを運営する企業が 10G を超えようとするとき、Mellanox が唯一の選択肢だったのです」と述べ、OEM が企業顧客にサービスを提供するために、こぞってその勢いに便乗したと指摘します。
IBM と Microsoft は、それぞれのパブリック クラウドでの RoCE のサポートを積極的に行っています。また、「最近では、Alibaba から、同社が毎年行う独身の日の大セールで RoCE ネットワークが素晴らしい働きをしたとの報告をいただきました」と、ケーガン氏は述べています。
スマート NIC: 従来 RDMA の機能を引き継ぐ
今や RDMA は至る所で使われ、目に見えないものになりつつあります。
現在のネットワークは、ますます高度なソフトウェアと仮想化によって定義されるようになり、基盤のハードウェアの詳細が隠されることでオペレーションがある程度簡素化されています。その内部では、RDMA が増加の一途をたどる機能の 1 つにすぎない存在になりつつあり、多くはスマート ネットワークインターフェイス カード (スマートNIC) に組み込まれたプロセッサ コア上で実行されています。
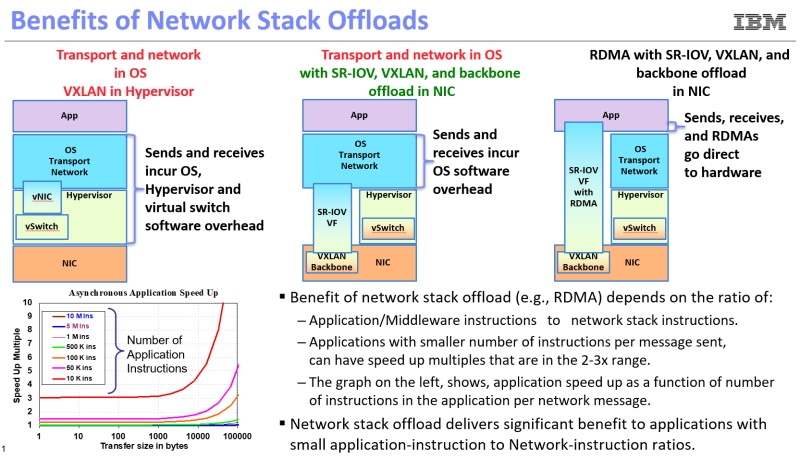 IBM が現在のスマート NIC で使われている RDMA と他のネットワーク オフロードの利点を詳しく解説
IBM が現在のスマート NIC で使われている RDMA と他のネットワーク オフロードの利点を詳しく解説
現在のスマート NIC はアダプティブ ルーティングを実現し、輻輳管理を行うほか、次第にセキュリティの監視にも対応するようになっています。スマート NIC は「本質的に、コンピューターを別のコンピューターの前に置く」ことで、RDMA がサーバーの CPU の時間を解放する働きを引き継いでいると、ケーガン氏は説明します。
RDMA と RoCE に基づく未来のスマート ネットワークの次の役割は、AI アプリケーションの台頭を加速させることです。
Mellanox の SHARP プロトコルは、すでに数十台から数千台のサーバーに分散された HPC アプリケーションのデータを統合しており、将来的にはディープラーニング モデルの更新された重みのようなパラメーター サーバーからのデータを集約することで、AI トレーニングを高速化することが期待されています。オハイオ州立大学のパンダ氏のラボでは、AI やビッグデータ分析のための RDMA ライブラリによって、このような研究の支援を続けています。
ゴールデンバーグ氏は、「現在の RDMA は、ネットワーク、ストレージ、AI に関する一連の機能において以前より桁違いに優れていて、より充実しています。指数関数的に増え続けるデータに対処するためにスケールアウトしています」と言います。
ダブルデート: AI と RDMA が NVIDIA と Mellanox をつなぐ
AI と RDMA の組み合わせは Mellanox と NVIDIA を結び付け、2019 年 3 月に発表された 69 億ドル規模の合併へと発展します。2020 年 4 月 27 日にこの契約は締結されました。
NVIDIA は Kepler アーキテクチャのGPU と CUDA 5.0 ソフトウェア向けの GPUDirect にRDMA を初めて実装しました。昨年には、GPUDirect Storage でその機能を拡張しています。
スーパーコンピューターは、Mellanox の RDMA に対応した InfiniBand ネットワークを採用すると同時に NVIDIA GPU をアクセラレーターとして採用し始めました。今日では、両社は 2018 年 6 月に世界最速のシステムに選ばれた「Summit」をはじめとする数多くのスーパーコンピューターに原動力を提供しています。
データ集約型で高いパフォーマンスを必要とする HPC と AI の類似点があったことから、ニューラルネットワークのトレーニングに NVIDIA の DGX システムでInfiniBand と RoCE を使用することについて協力することになりました。
Mellanox が NVIDIA の傘下となったことで、ケーガン氏は彼のキャリアが一周しつつあると感じています。
「私のアーキテクトとしての初の大きな設計プロジェクトはベクトル プロセッサで、当時は世界最速のマイクロプロセッサでした」と、ケーガン氏は語ります。「そして今、私は最先端のベクトル プロセッサを設計し、プロセッサ技術とネットワーク技術の融合を助け、コンピューティングを次のレベルへと押し上げようとしている企業にいるのです。本当に素晴らしいことだと思います」
IBM のネットワーク担当フェローであり、InfiniBand 規格の定義に貢献したレナト レシオ (Renato Recio) 氏は次のように述べています。「Mellanox は、20 年近くにわたり RDMA ハードウェアの提供をリードしてきました。その間ずっとマイケルとドロールと一緒に働くことができたことを光栄に思っています。次に何が来るか楽しみにしています」