
NVIDIA は OpenAI と協力し、NVIDIA の新しいオープンソース gpt-oss モデルを NVIDIA GPU 向けに最適化し、クラウドから PC へのスマートで高速な推論を実現しました。これらの新しい推論モデルにより、ウェブ検索や詳細な調査などのエージェント型 AI アプリケーションが可能になります。
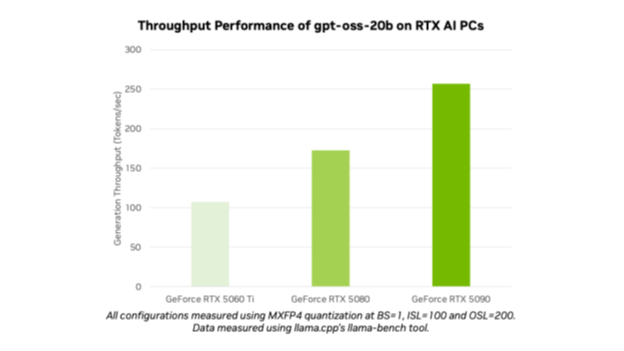
gpt-oss-20b と gpt-oss-120b の追加により、OpenAI は最先端のモデルを数百万人のユーザーに公開しました。AI 愛好家や開発者は、Ollama、llama.cpp、Microsoft AI Foundry Local などの AI 開発向けの人気ツールやフレームワークを利用して、NVIDIA RTX AI PC やワークステーションで最適化されたモデルを使用できます。NVIDIA GeForce RTX 5090 GPU では、AI 処理速度として最大 256 トークン/秒の性能を期待できます。
「OpenAI は NVIDIA AI を基盤に何が構築できるかを世界に示しました。そして現在、オープンソース ソフトウェアの発展を推進しています」と、NVIDIA の創業者/ CEO である ジェンスンフアン(Jensen Huang)は述べています。「gpt-oss モデルにより、世界中の開発者が最先端のオープンソース基盤を活用して構築を進め、AI における米国の技術的リーダーシップを強化できます。これらはすべて、世界最大の AI 計算インフラ上で実現されます。」
これらのモデルのリリースは、トレーニングから推論、クラウドから AI PC に至るまでの NVIDIA の AI リーダーシップを際立たせています。
全員に公開
gpt-oss-20b と gpt-oss-120b はどちらも「Chain-of-Thought (思考の連鎖)」機能を備えた柔軟なオープンウェイトの推論モデルであり、人気の「Mixture-of-Experts (専門家の混合)」アーキテクチャを用いて推論の負荷レベルを調整できます。これらのモデルは指示に従い、ツールの使用などの機能をサポートするように設計されており、NVIDIA H100 GPU でトレーニングされています。 AI 開発者は、NVIDIA テクニカル ブログの指示に従って詳細情報を確認し、作業を開始できます。
これらのモデルは、最大 131,072 のコンテキスト長をサポートし、ローカル推論で利用可能な最長クラスの長さです。つまり、モデルは文脈の問題を通じて推論が可能であり、ウェブ検索、コーディング支援、文書理解、詳細な調査などのタスクに最適です。
OpenAI のオープンモデルは、NVIDIA RTX でサポートされる初の MXFP4 モデルです。MXFP4 は、高速かつ効率的な性能を提供し、他の精度タイプと比較して必要なリソースを削減しながら、高品質なモデルを実現します。
NVIDIA RTX で Ollama を使って OpenAI モデルを実行してください。
RTX AI PC や 24GB 以上の VRAM を搭載した GPU で、これらのモデルをテストする最も簡単な方法は、新しい Ollama アプリを使用することです。 Ollama は統合が容易なことで AI 愛好家や開発者に人気があります。新しいユーザー インターフェイス (UI) は OpenAI の開放型モデルを標準でサポートしています。Ollama は RTX 向けに完全に最適化されており、PC やワークステーションでパーソナル AI のパワーを体験したいユーザーに最適です。
Ollama をインストールすると、モデルとのチャットが素早く簡単になります。 ドロップダウン メニューからモデルを選択し、メッセージを送信するだけです。 Ollama は RTX 用に最適化されているため、対応する GPU で最高のパフォーマンスを実現するために追加の設定やコマンドは必要ありません。

Ollama の新しいアプリには、チャット内での PDF やテキストファイルの簡単なサポート、該当モデルでプロンプトに画像を含めることができる多機能サポート、大規模な文書やチャットの簡単なコンテキスト長調節など、その他の新機能も含まれています。
開発者は、コマンドライン インターフェイスやアプリのソフトウェア開発キット (SDK) を介して Ollama を使用し、アプリケーションやワークフローを強化することもできます。
RTX で新しい OpenAI モデルを利用するための他の方法
愛好家や開発者は RTX AI PC の GPU (例えば 16GB 以上の VRAM 搭載機) で、さまざまなアプリケーションやフレームワークを使用して RTX 搭載の GPU で gpt-oss モデルを試すことができます。
NVIDIA は、llama.cpp および GGML テンソル ライブラリに関して、オープンソース コミュニティと協力し、RTX GPU のパフォーマンスを最適化します。最近の取り組みとしては、CUDA Graphs を実装してオーバーヘッドを削減することや、CPU オーバーヘッドを軽減するアルゴリズムの追加が含まれています。開始するには、llama.cpp の GitHub リポジトリをご覧ください。
Windows 開発者は、現在公開プレビュー中の Microsoft AI Foundry Local を通じて、OpenAI の新しいモデルにアクセスすることもできます。Foundry Local は、コマンドライン、SDK、または API を介してワークフローに統合される、オンデバイスの AI 推論ソリューションです。Foundry Local は、CUDA を通じて最適化された ONNX Runtime を使用しています。RTX 対応の NVIDIA TensorRT サポートも提供します。始めるのは簡単です。Foundry Local をインストールし、ターミナルで「Foundry model run gpt-oss-20b」を起動します。
これらのオープンソース モデルのリリースにより、AI による加速が施された Windows アプリケーションに推論機能を追加しようとする愛好家や開発者による、AI イノベーションの新たな波の幕開けとなりました。
RTX AI Garage ブログ シリーズでは、NVIDIA NIM マイクロサービスと AI Blueprint について詳しく知りたい方や、AI PC とワークステーションで AI エージェント、クリエイティブなワークフロー、生産性アプリなどを構築する方向けに、コミュニティ主導の AI イノベーションとコンテンツを紹介しています。
Facebook、Instagram、TikTok、X で NVIDIA AI PC をフォローし、RTX AI PC ニュースレターを購読して、最新情報を入手しましょう。 NVIDIA の Discord サーバーに参加してコミュニティの開発者や AI 愛好者とつながり、RTX AI の可能性について話し合いましょう。
LinkedIn と X で NVIDIA Workstation をフォローしてください。
ソフトウェア製品情報に関するお知らせをご覧ください。