
オープン モデルは、オンデバイス AI の新たな波を牽引し、イノベーションをクラウドの枠を超えて日常のデバイスへと広げています。これらのモデルが進化するにつれ、その価値は、有意義な洞察を行動へと転換することができるローカルかつリアルタイムのコンテキストへのアクセスにますます依存するようになっています。
この変化に対応するために設計された最新の Google の Gemma 4 ファミリーは、幅広いデバイス上で効率的なローカル実行を実現するために構築された、小型で高速かつ万能なモデル群を提供します。
Google と NVIDIA は協力し、Gemma 4 を NVIDIA GPU 向けに最適化しました。これにより、データセンターでの展開から、NVIDIA RTX 搭載 PC やワークステーション、NVIDIA DGX Spark パーソナル AI スーパーコンピューター、NVIDIA Jetson Orin Nano エッジ AI モジュールに至るまで、幅広いシステムで効率的なパフォーマンスを実現します。
Gemma 4: NVIDIA GPU 向けに最適化されたコンパクト モデル
Gemma 4 ファミリーのオープン モデルの最新ラインナップ (E2B、E4B、26B、31B の各バリエーション) は、エッジ デバイスから高性能 GPU に至るまで効率的な展開ができるよう設計されています。
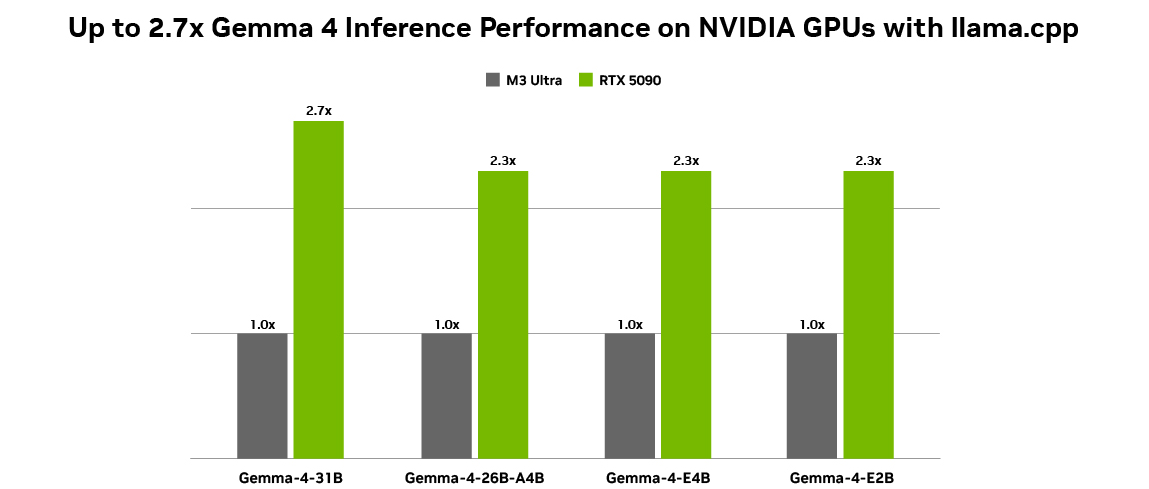
すべての構成は、NVIDIA GeForce RTX 5090 および Mac M3 Ultra デスクトップ上で、Q4_K_M 量子化 (BS = 1、ISL = 4096、OSL = 128) を用いて測定。トークン生成のスループットは、llama-bench ツールを使用し、llama.cpp b7789 で測定。
この新世代のコンパクト モデルは、以下のような幅広いタスクに対応できます。
- リーズニング: 複雑な問題解決タスクにおいて強力なパフォーマンスを発揮。
- コーディング: 開発者のワークフロー向けのコード生成およびデバッグ。
- エージェント: 構造化されたツールの使用 (関数呼び出し) をネイティブにサポート。
- 視覚、ビデオ、音声機能: 物体認識、自動音声認識、文書やビデオのインテリジェンスなど、豊富なマルチモーダル インタラクションを実現。
- インターリーブされたマルチモーダル入力: 単一のプロンプト内で、テキストと画像を任意の順序で組み合わせることが可能。
- 多言語対応: 35 以上の言語を標準でサポートし、140 以上の言語で事前学習済み。
E2B および E4B モデルは、エッジで超高効率かつ低遅延の推論を行えるように構築されています。Jetson Orin Nano モジュールなどの多くのデバイスで、完全にオフラインかつゼロに近い遅延で動作します。
26B および 31B モデルは、高性能なリーズニングと開発者中心のワークフローを想定して設計されており、エージェント型 AI に理想的です。これらのモデルは、最先端の使いやすいリーズニングを実現できるよう最適化されており、NVIDIA RTX GPU および DGX Spark 上で効率的に動作し、開発環境、コーディング アシスタント、エージェント駆動のワークフローを支えることができます。
ローカルのエージェント型 AI が勢いを増す中、OpenClaw のようなアプリケーションによって、RTX PC、ワークステーション、および DGX Spark 上で常時稼働型の AI アシスタントが実現しています。最新の Gemma 4 モデルは OpenClaw と互換性があり、ユーザーは高性能なローカル エージェントを構築し、個人のファイル、アプリケーション、ワークフローからコンテキストを取得してタスクを自動化することが可能になります。RTX GPU や DGX Spark で OpenClaw を無料で実行する方法や、DGX Spark OpenClaw プレイブックの使い方もご参照ください。
Gemma 4 ファミリーの最新ラインナップの詳細については、Google DeepMind の発表ブログをご覧ください。
導入方法: RTX GPU および DGX Spark での Gemma 4
NVIDIA は Ollama および llama.cpp と協力し、各 Gemma 4 モデルについて最適なローカル展開体験を提供しています。
Gemma 4 をローカルで利用するには、Ollama をダウンロードして Gemma 4 モデルを実行するか、llama.cpp をインストールして Gemma 4 GGUF Hugging Face チェックポイントと組み合わせます。さらに、Unsloth は公開初日から Unsloth Studio を介した効率的なローカルでのファインチューニングと展開のために、最適化および量子化されたモデルをサポートしています。Unsloth Studio で、Gemma 4 の実行とファインチューニングを今すぐ開始できます。
Gemma 4 ファミリーのようなオープン モデルを NVIDIA GPU 上で実行すると、最適なパフォーマンスを得られます。NVIDIA Tensor コアが AI 推論ワークロードを加速し、ローカル実行において高いスループットと低遅延を実現するためです。さらに CUDA ソフトウェア スタックが、主要なフレームワークやツールとの幅広い互換性を確保し、新しいモデルも公開初日から効率的に実行できます。
以上の組み合わせにより、Gemma 4 のようなオープン モデルは、エッジの Jetson Orin Nano から RTX PC、ワークステーション、DGX Spark まで、大規模な最適化を必要とせずに幅広いシステムへ拡張することができます。
NVIDIA GPU 上で Gemma 4 を導入する方法の詳細や、NVIDIA のオープン モデルに関する取り組みについては、NVIDIA 技術ブログをご覧ください。
#ICYMI: RTX AI PC の最新情報
✨RTX AI Garage ブログでは、NVIDIA GTC で発表されたエージェント型 AI に関する数々のニュース、例えばローカル エージェント向けの新しいオープン モデルなどについてお読みいただけます。これらのモデルには、NVIDIA Nemotron 3 Nano 4B や Nemotron 3 Super 120B のほか、Qwen 3.5 や Mistral Small 4 の最適化機能が含まれます。
NVIDIA は最近、NVIDIA NemoClaw を発表しました。このオープン ソース スタックは、セキュリティを強化してローカル モデルをサポートすることで、NVIDIA デバイス上での OpenClaw 体験を最適化します。
🚀Accomplish.ai が発表した Accomplish FREE は、モデルが組み込まれたオープン ソースのデスクトップ AI エージェントの無料版です。NVIDIA GPU を活用してオープン ウェイト モデルをローカルで実行する一方、ハイブリッド ルーターが、ローカルの RTX ハードウェアとクラウドの間でワークロードの動的なバランス調整を行います。これにより、アプリケーション プログラミング インターフェイス (API) キーを必要とせず、高速かつプライベートで、設定不要の実行が可能になります。
Facebook、Instagram、TikTok、X で NVIDIA AI PC をフォローし、RTX AI PC ニュースレターを購読して最新情報を入手してください。