
AI を活用したコーディングアシスタントや Copilot は、コードの提案、説明、デバッグをすることができ、経験豊富な開発者と初心者の開発者の両方向けにソフトウェアの開発方法を根本的に変えています。
経験豊富な開発者は、これらのアシスタントを使用して複雑なコーディングタスクに集中し、反復作業を減らして、新しいアイデアをより迅速に探索することができます。 学生や AI 愛好家などの初心者のコーダーは、さまざまな実装アプローチを説明したり、コードの意図とその理由を解説することで学習をスピードアップさせるコーディングアシスタントから恩恵を受けています。
コーディングアシスタントは、クラウド環境やローカルで実行できます。 クラウドベースのコーディングアシスタントはどこでも実行できますが、一部の制限があり、サブスクリプションが必要です。 ローカル コーディング アシスタントはこれらの問題を取り除きますが、適切に動作するには性能の良いハードウェアが必要です。
NVIDIA GeForce RTX GPU は、ローカル アシスタントを効率的に実行するために必要なハードウェア アクセラレーションを提供します。
コード、生成 AI と融合
従来のソフトウェア開発には、ドキュメントの確認、事例の調査、定例コードの設定、適切な構文でのコードの作成、バグの追跡、機能の文書化など、多くの日常的なタスクが含まれています。 これらは重要なタスクであり、問題解決やソフトウェア設計に割く時間を奪うことがあります。 コーディング アシスタントは、こうした手順を効率化するのに役立ちます。
多くの AI アシスタントは、Microsoft Visual Studio Code や JetBrains の Pycharm といった人気の統合開発環境(IDE)にリンクされており、AI サポートが既存のワークフローに直接組み込まれています。
コーディング アシスタントを実行するには、クラウドとローカルの 2 つの方法があります。
クラウド ベースのコーディング アシスタントでは、応答が返される前にソース コードを外部サーバーに送信する必要があります。 このアプローチはラグが多く、使用制限を課す場合があります。 一部の開発者は、特に機密または専有のプロジェクトで作業する場合、コードをローカルに保持することを好みます。 さらに、多くのクラウドベースのアシスタントは、完全な機能を活用するために有料サブスクリプションを必要とし、学生、愛好家、コストを管理する必要のあるチームにとって障壁になりうる可能性があります。
コーディングアシスタントはローカル環境で実行され、以下の機能を使用して無料でアクセスできます。

ローカルのコーディングアシスタントで始める
コーディングアシスタントをローカルで簡単に実行できるツールとして、以下のようなものがあります。
- Continue.dev — VS Code IDE のオープンソース拡張機能で、Ollama、LM Studio、カスタム エンドポイントを介してローカルの大規模言語モデルに接続します。 このツールは、最小限のセットアップでエディター内のチャット、オートコンプリート、デバッグの支援を提供します。 Ollama バックエンドを使用してローカル RTX アクセラレーションを Continue.dev で始めましょう。
- Tabby — 多くの IDE と互換性のある安全で透明性のあるコーディングアシスタントで、NVIDIA RTX GPU で AI を動作させることができます。 このツールは、コードの補完、質問への回答、インラインチャットなどの機能を提供します。 NVIDIA RTX AI PC で Tabby を使い始めましょう。
- OpenInterpreter — LLM とコマンドラインアクセス、ファイル編集、エージェントタスク実行を組み合わせた実験的ながら急速に進化しているインターフェースです。開発者向けの自動化およびDevOpsスタイルのタスクに最適です。 NVIDIA RTX AI PC で OpenInterpreter を使い始めましょう。
- LM Studio — ローカル LLM 向けのグラフィカルユーザーインターフェースベースのランナーで、チャット、コンテキストウィンドウ管理、システムプロンプトを提供します。 IDE へのデプロイ前にコーディングモデルをインタラクティブにテストするのに最適です。 NVIDIA RTX AI PC で LM Studio を使い始めましょう。
- Ollama — Code Llama、StarCoder2、DeepSeek などのモデルの高速でプライベートな推論を可能にするローカルAIモデル推論エンジンです。dev などのツールとシームレスに統合されています。
これらのツールは、Ollama や llama.cpp などのフレームワークを通じて提供されるモデルをサポートしており、多くは GeForce RTX と NVIDIA RTX PRO GPU 向けに最適化されています。
RTX で AI 支援学習の実際の動作を見る
GeForce RTX 搭載の PC で実行される Continue.dev は、Gemma 12B Code LLM と組み合わせることで、既存コードの説明、探索アルゴリズムの調査、デバッグの問題をすべてデバイス上で行うことができます。 バーチャルな教育アシスタントのように行動し、分かりやすい言葉での指導、文脈に応じた説明、インラインコメント、ユーザーのプロジェクトに合わせたコード改善の提案を提供します。
このワークフローは、ローカルアクセラレーションの利点を強調しています。アシスタントは常に利用可能で、即座に対応し、パーソナライズされたサポートを提供します。このすべては、デバイス上のコードを非公開に保ちながら、没入感のある学習体験を提供することで実現されています。
このレベルの応答性は、GPU アクセラレーションに依存しています。 Gemma 12B のようなモデルは、特に長いプロンプトを処理したり、複数のファイル間で作業する場合、計算負荷が高くなります。 ローカル環境で GPU なしで実行すると、簡単なタスクであっても遅く感じることがあります。RTX GPU により、Tensor コアはデバイス上で直接推論処理を高速化します。そのため、アシスタントは高速かつ応答性が高く、アクティブな開発ワークフローに追いつくことができます。
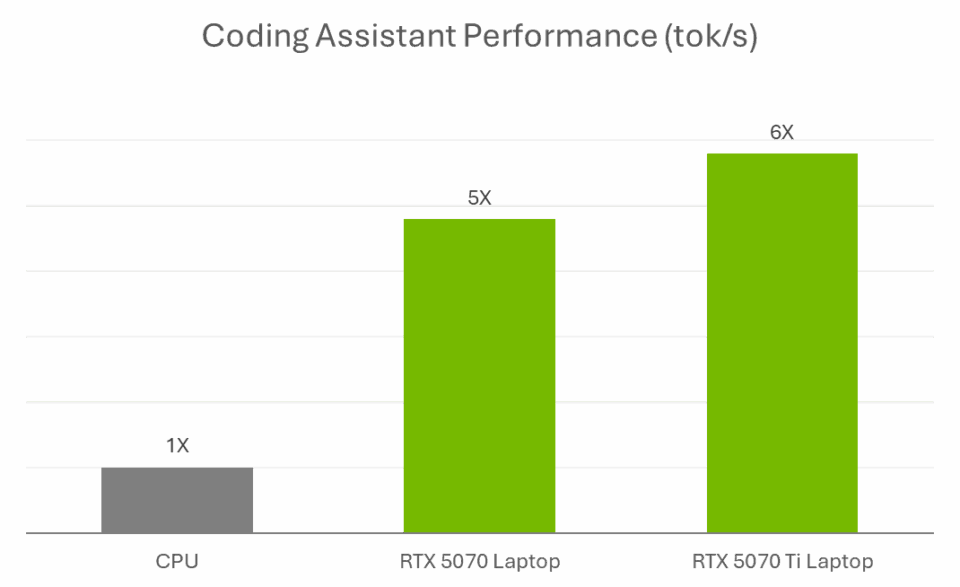
学術的な著作、コーディングブートキャンプ、または個人的なプロジェクトに使用する場合でも、RTX AI PC により、AI を搭載したツールを使用することで、開発者はより高速に構築、学習、反復を行うことができます。
始めたばかりの方、特にスキルを磨いたり、生成 AI を試している学生向けに、NVIDIA GeForce RTX 50 シリーズ ノート PCは、学習、創作、ゲーム向けの主要アプリをすべて一つのシステム上で高速化する専門の AI テクノロジを搭載しています。 新学期に最適な RTX ノート PC をご覧ください。
NVIDIA の Discord サーバーに参加し、コミュニティの開発者や AI 愛好者とつながり、RTX AIの可能性について話し合ってください。
RTX AI Garage ブログ シリーズは、NVIDIA NIM マイクロサービスと AI Blueprint について詳しく知りたい方向けにコミュニティ主導の AI イノベーションとコンテンツを特集しています。また、AI PC とワークステーションにおける AI エージェント、クリエイティブなワークフロー、デジタル ヒューマン、生産性アプリなどの構築についても紹介しています。
Facebook、Instagram、TikTok、X で NVIDIA AI PC に接続し、RTX AI PC ニュースレターを購読することで最新情報を入手してください。
LinkedIn と X で NVIDIA Workstation をフォローしてください。
ソフトウェア製品情報に関するお知らせをご覧ください。