
AI の活用が世界的に拡大していくなか、NVIDIA とパートナーは、データ センターとエッジのすべての MLPerf ベンチマークで記録を打ち立てる
アプリケーションにおいて AI を使用する推論は、一般利用が進んでおり、実行速度がこれまで以上に高速化されています。
NVIDIA GPU は、業界唯一のコンソーシアムに基づく、同業者によって審査される最新のベンチマークにおいて、データ センターとエッジ コンピューティング システムのすべての AI 推論テストで勝利を収めました。
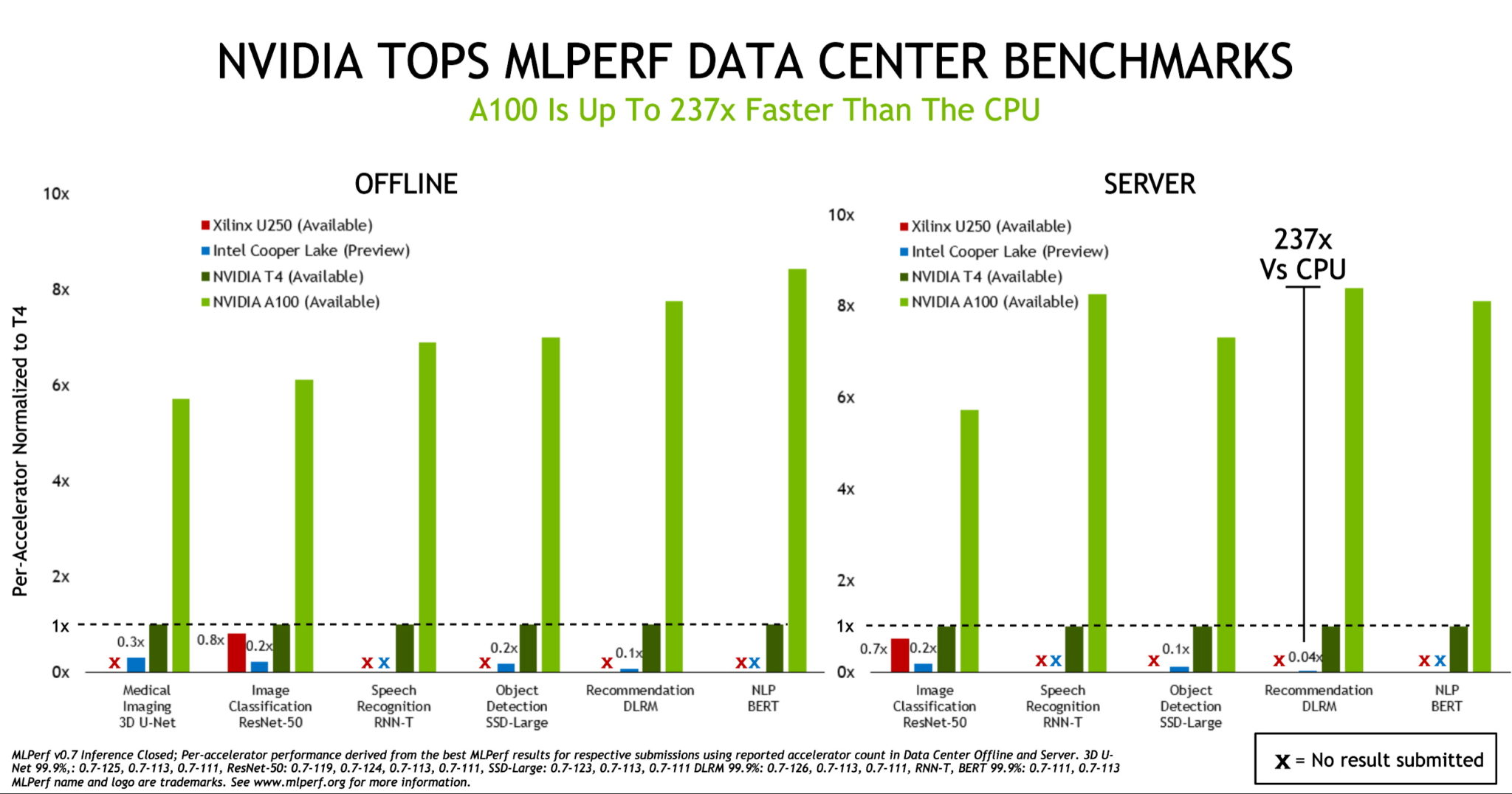 NVIDIA A100 および T4 GPU は、データ センターのすべての推論テストで圧勝しました。
NVIDIA A100 および T4 GPU は、データ センターのすべての推論テストで圧勝しました。NVIDIA A100 Tensor コア GPU は、昨年実施された最初の AI 推論テストで実証したパフォーマンスの優位性をさらに高めました。この AI 推論テストは、2018 年 5 月に設立された、業界のベンチマーク コンソーシアムである MLPerf が主催しています。
MLPerf Inference 0.7 ベンチマークによると、5 月に発表された A100 は、データ センターの推論で CPU よりも最大で 237 倍もパフォーマンスが優れていました。小型のフォーム ファクターながら、エネルギー効率に優れた GPU である NVIDIA T4 は、同じ推論テストで CPU よりも最大で 28 倍上回りました。
今回の結果を総体的に見れば、8 基の A100 GPU で構成された 1 台の NVIDIA DGX A100 システムは、およそ 1,000 台のデュアルソケット CPU サーバーと同じパフォーマンスをいくつかの AI アプリケーションで発揮することになります。
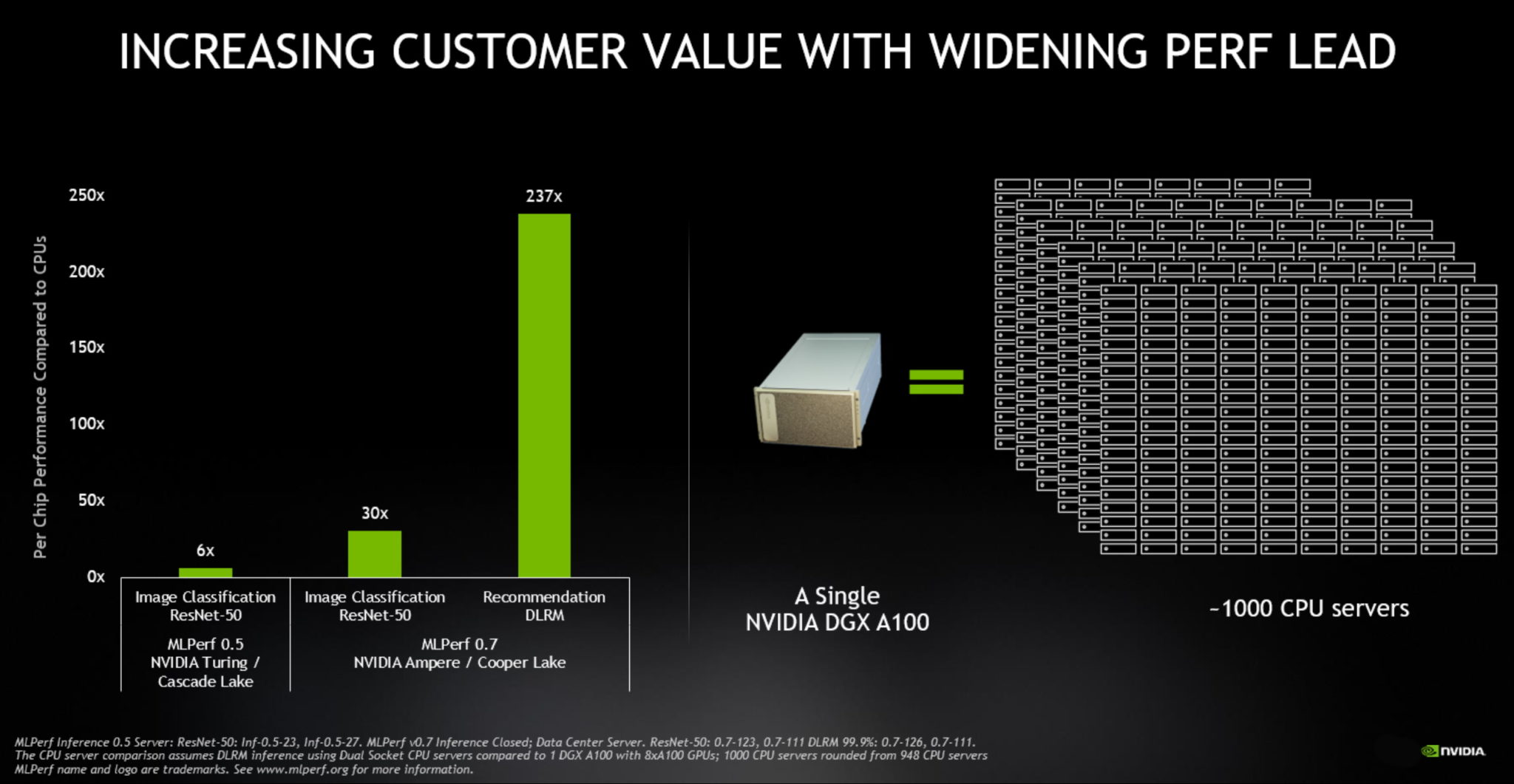 パフォーマンスの優位性は、研究から実稼働への AI 移行のコスト効率を高めます。
パフォーマンスの優位性は、研究から実稼働への AI 移行のコスト効率を高めます。さらに、今回のベンチマークでは 23 の機関が提出しており、前回の 12 社から参加機関が増えています。NVIDIA の AI プラットフォームを使用しているパートナーが提出全体の 85% 以上を推進しています。
A100 GPU、Jetson AGX Xavier によるエッジのパフォーマンス向上
A100 が AI 推論パフォーマンスの新たな頂点を極めたのに対し、主流のエンタープライズ サーバー、エッジ サーバー、費用対効果の高いクラウド インスタンス向けの信頼性に優れた推論プラットフォームの地位を T4 が維持していることをベンチマークは示しています。さらに、NVIDIA Jetson AGX Xavier は、新しいすべてのユース ケースをサポートし、電力の制約がある SoC ベースのエッジ デバイスにおけるリーダーとしての地位を築いています。
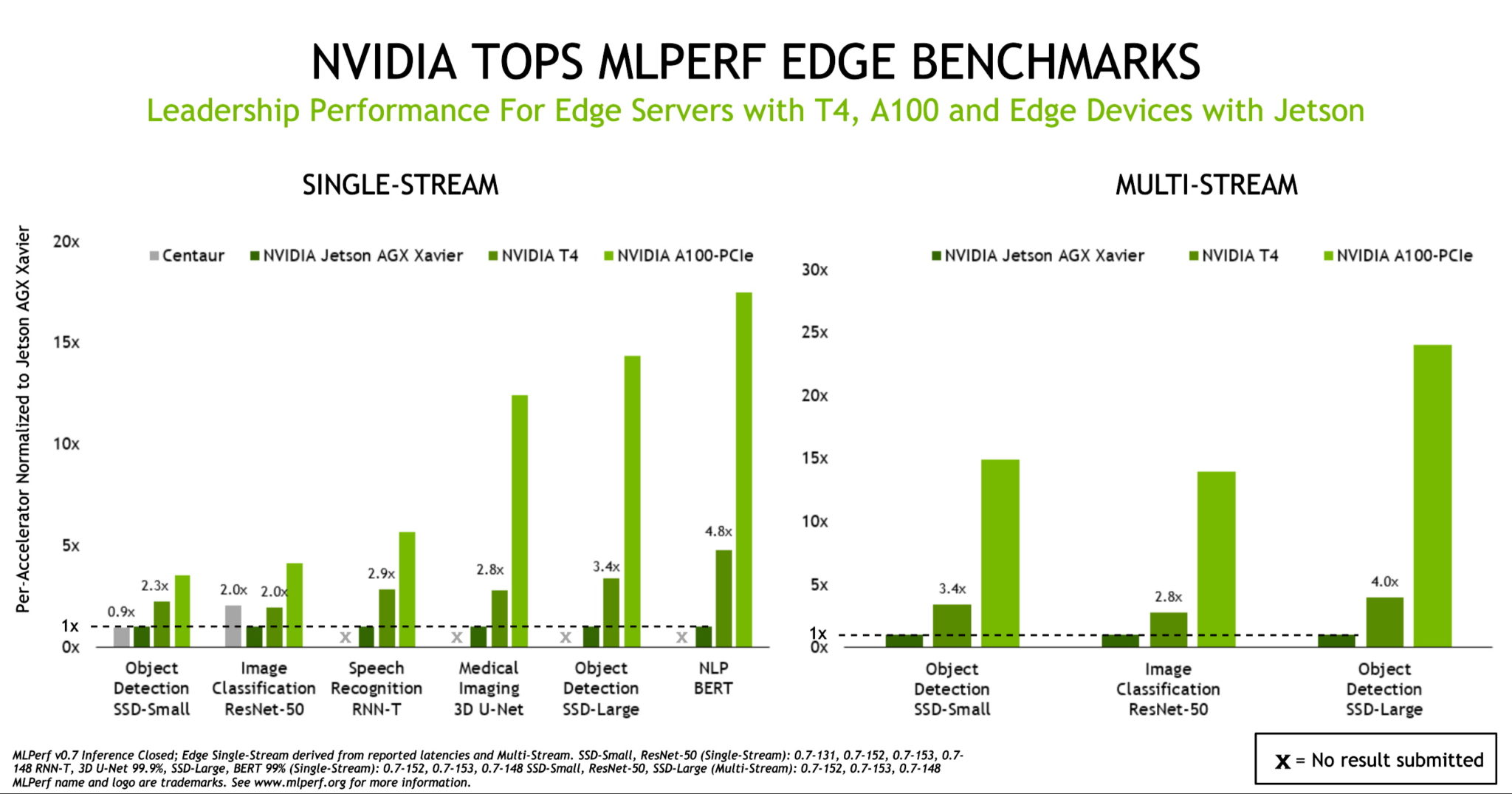 エッジで優れたパフォーマンスを発揮するGPUとして、 A100 と T4 GPU のほか、 Jetson AGX Xavier が加わりました。
エッジで優れたパフォーマンスを発揮するGPUとして、 A100 と T4 GPU のほか、 Jetson AGX Xavier が加わりました。このベンチマークの結果は、NVIDIAのAI エコシステムの精力的な拡大も示しています。提出された 1,029 件の結果で NVIDIA ソリューションが使用されており、データ センターとエッジのカテゴリーにおける提出全体の 85% を占めています。これらの提出結果により、パートナーが提供するシステム全体の安定したパフォーマンスが実証されました。NVIDIA のパートナーには、Altos、Atos、Cisco、Dell EMC、Dividiti、富士通、Gigabyte、Inspur、Lenovo、Nettrix、QCT などが含まれます。
日常生活に高度な AI をもたらすユースケースの拡大
産業界と学界からの幅広い支持を得て、MLPerf ベンチマークは、業界のユース ケースを代表するまでに発展を遂げています。MLPerf の支援組織には、Arm、Baidu、Facebook、Google、Harvard、Intel、Lenovo、Microsoft、Stanford、トロント大学、NVIDIA などが名を連ねています。
最新のベンチマークでは 4 つのテストを新たに導入し、拡大する AI の状況を浮き彫りにしています。現在、このベンチマーク スイートでは、コンピューター ビジョンでの AI ユース ケースのパフォーマンスに加えて、自然言語処理、医用画像、レコメンデーション システム、音声認識のパフォーマンスも採点しています。
今や、検索エンジンを使うだけで、自然言語処理が日常生活に及ぼす影響を感じることができます。
Microsoft の検索および AI 担当のバイス プレジデントであるランガン マジュムダー (Rangan Majumder) 氏は次のように述べています。「最近の AI が自然言語理解で成し遂げたブレイクスルーは、Bing をはじめとする、より多くの AI サービスでより自然なやりとりを可能にし、正確で有益な結果、回答、助言を瞬時にもたらしています。」
「業界標準の MLPerf ベンチマークは、幅広く使用される AI ネットワークの適切なパフォーマンス データを提供し、十分な情報に基づく AI プラットフォームの購入決定に役立っています」と同氏は言います。
パンデミック下の救命に役立つ AI
AI が医用画像に及ぼす影響はさらに劇的です。たとえば、スタートアップ企業の Caption Health は、心エコー図をとる作業を容易にするために AI を使用しています。この心エコー図は、COVID-19 パンデミックの初期に米国の病院で救命に寄与する役割を果たしました。
医療 AI のオピニオン リーダーが、最新の MLPerf ベンチマークで使用されている 3D U-Net などのモデルを重要な成功要因と見なすのはこのためです。
「私たちは NVIDIA と緊密に連携して 3D U-Net のようなイノベーションを医療市場にもたらしました」と語るのは、ドイツがん研究センター (DKFZ) で医用画像コンピューティングの責任者を務めるクラウス マイヤーヘイン (Klaus Maier-Hein) 氏です。
「コンピューター ビジョンとイメージングは AI 研究の中心をなし、科学的な発見を推進し、医療の中核的な要素となっています。業界標準の MLPerf ベンチマークは適切なパフォーマンス データを提供し、IT の組織や開発者が特定のプロジェクトとアプリケーションを促進するのに役立ちます」と同氏は言います。
最新の MLPerf テストに組み込まれている、レコメンデーション システムのような AI ユース ケースも、すでに大きな商業的影響をもたらしています。昨年 11 月の「独身の日」に、Alibaba はレコメンデーション システムを使用してオンライン販売で 380 億ドルの取引を行いました。これは、昨年における最大の買い物の日となりました。
転換点を越えた NVIDIA AI 推論の導入
今年、AI 推論は重要な節目を越えました。
NVIDIA GPU は、パブリック クラウドで計 100 エクサフロップス以上の AI 推論パフォーマンスを過去 12 カ月間で達成し、クラウド CPU による推論を初めて上回りました。NVIDIA GPU でのクラウド AI 推論の総合コンピューティング能力は、2 年ごとに約 10 倍のペースで増加しています。
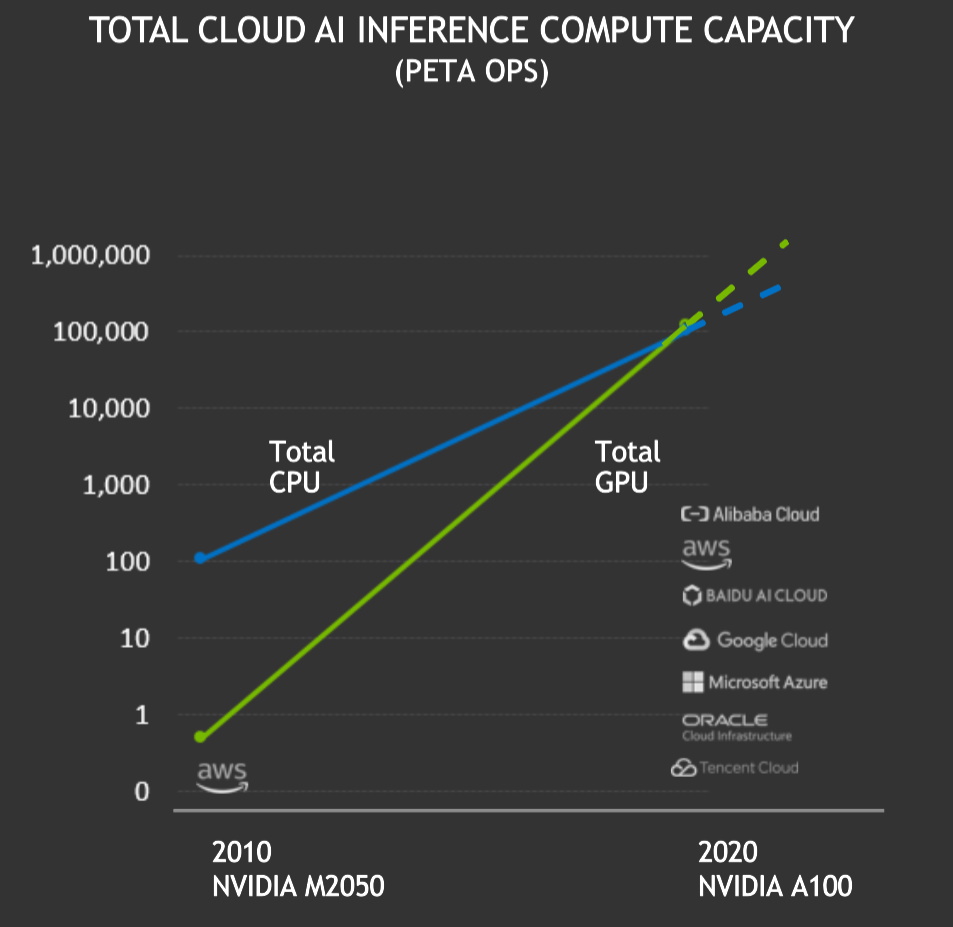 現在では、主要なクラウド サービスの GPU は CPU よりも高い推論パフォーマンスを発揮しています。
現在では、主要なクラウド サービスの GPU は CPU よりも高い推論パフォーマンスを発揮しています。NVIDIA GPU のコンピューティングはパフォーマンス、活用のしやすさ、可用性に優れているため、自動車、クラウド、ロボティクス、ヘルスケア、小売業、金融サービス、製造業などのさまざまな業界にわたり、ますます多くの企業が、今では AI 推論に NVIDIA GPU を使用しています。こうした企業の例として、American Express、BMW、Capital One、Dominos、Ford、GE Healthcare、Kroger、Microsoft、Samsung、トヨタ自動車などが挙げられます。
 多岐にわたる主要業界の企業が NVIDIA の AI プラットフォームを推論に使用しています。
多岐にわたる主要業界の企業が NVIDIA の AI プラットフォームを推論に使用しています。AI 推論が難しい理由
AI のユース ケースは明らかに拡大していますが、AI 推論にはさまざまな理由で困難が伴います。
新たなユース ケースに向けて敵対的生成ネットワークのような新しいタイプのニューラルネットワークが絶えず生まれており、そのモデルは指数関数的に増加しています。現在、AI に最適な言語モデルは何十億ものパラメーターを包含し、その分野の研究はまだ緒に就いたばかりです。
これらのモデルは、クラウド、企業のデータ センター、ネットワークのエッジで実行する必要があります。そのためには、これらのモデルを実行するシステムが十分にプログラマブルであることや、さまざまな側面にわたって適切に実行できることが求められます。
NVIDIA の創業者/ CEO であるジェンスン フアン (Jensen Huang) は、こうした複雑さを PLASTER という一語に要約しています。最新の AI 推論では、プログラマビリティ (Programmability)、レイテンシ (Latency)、精度 (Accuracy)、モデルの規模 (Size of model)、スループット (Throughput)、エネルギー効率 (Energy efficiency)、学習速度 (Rate of learning) に優れていることが要求されます。
すべての側面にわたって卓越性を強化するために、私たちはエンドツーエンドの AI プラットフォームの進化に絶えず取り組み、要求の厳しい推論ジョブに対処しています。
AI に求められるパフォーマンスと使いやすさ
第 3 世代の Tensor コアと Multi-Instance GPU アーキテクチャの柔軟性を備えた A100 のようなアクセラレータは始まりにすぎません。優位な結果をもたらすには、十分なソフトウェア スタックを必要とします。
NVIDIA の AI ソフトウェアは、AI 推論をすぐに実行できる、事前トレーニング済みのさまざまなモデルで開始できます。NVIDIA の Transfer Learning Toolkit を使用すると、ユーザーはそれぞれのユース ケースやデータセットに合わせてこれらのモデルを最適化できます。
NVIDIA TensorRT は、トレーニング済みのモデルを推論向けに最適化します。2,000 の最適化を備えたこのソフトウェアは、16,000 の組織によって 130 万回ダウンロードされています。
NVIDIA Triton Inference Server は、複数の GPU とフレームワークをサポートするこれらの AI モデルを実行する、調整済みの環境を提供します。アプリケーションはクエリと制約 (所要応答時間や数千人のユーザーへの拡張のスループットなど) を送信するだけです。そのあとは Triton が引き受けます。
これらの要素は CUDA-X AI 上で実行されます。これは、成熟した一連のソフトウェア ライブラリであり、NVIDIA の広く使用されているアクセラレーテッド コンピューティング プラットフォームに基づきます。
アプリケーション フレームワークで速やかに開始
最後に、NVIDIA のアプリケーション フレームワークは、業界やユース ケースが多岐にわたるエンタープライズ AI の導入を後押しします。
NVIDIA のフレームワークには、レコメンダー システム用のNVIDIA Merlin 、対話型AI向けのNVIDIA Jarvis 、ビデオ会議向けのNVIDIA Maxine 、ヘルスケア用のNVIDIA Clara などがあり、ほかにも多くのフレームワークが現在提供されています。
これらのフレームワークは、最新の MLPerf ベンチマークの最適化と併せて NGC で入手できます。NGC は GPU で加速化されるソフトウェアのハブとして機能し、これらのソフトウェアは NVIDIA 認定のすべての OEM システムやクラウド サービスで動作します。
このように、私たちの懸命な働きはコミュニティ全体に利益をもたらしています。
※NVIDIA Jarvis の名称は 2021 年 7 月に NVIDIA Riva に変更されました。
※Transfer Learning Toolkit の名称は 2021 年 8 月に TAO Toolkit に変更されました。