
粘着テープ。プレキシガラス。ビニール紐。耳栓。バンドエイド。
宇宙船であれスポーツカーであれ、何かを初めて作り上げようとすれば、ここから始まります。NVIDIA DGX-1ディープラーニング・システムを作り上げたエンジニアリング・チームの経費明細書を見れば、こうしたものが目に留まるでしょう。
その結晶は、傷ひとつない12万9000ドルの宝石箱。ティファニーのショーケースに収められてもおかしくないほどコンパクトです。それでいて、最高170テラフロップスの演算能力を発揮します。これは250台のx86サーバに匹敵し、その能力はある報道機関が「正気ではない」と表現したほどです。
4月に開催された当社のGPUテクノロジ・カンファレンスで発表されたDGX-1は、人間を超える能力で結果をはじき出すディープラーニング・ソフトウェアを搭載しています。迅速に利用可能にし、即時にシステムを更新できるよう、すべてがクラウドベースのサービスに接続されています。組み立ては不要です。
AIブームを盛り上げるDGX-1

NVIDIA DGX-1
DGX-1は、研究室の外で、ディープラーニングを迅速かつ、より簡単に利用したい場合には最適です。研究者達が過去5年以上にわたって構築してきたシステムは、かつてはコンピュータには処理できないと考えられていたタスクに関して、人間の能力に並び始め、やがて人間を超えました。
今や何億もの人々にとって、音声認識やリアルタイムの音声翻訳、映像の発見という場面で、ディープラーニングを活用したサービスは、なくてはならないものです。活用の機会はまだまだあります。しかし、さまざまなパーツからディープラーニング・システムを構築するには、時間も人手もかかります。そこで、DGX-1の登場です。DGX-1は、あらゆる業界と当社のパートナー・エコシステムの利益となる、新たな可能性を開くでしょう。
努力と粘着テープとソフトウェア
DGX-1の裏話は、レースの物語です。このレースは、努力と粘着テープとソフトウェアに支えられ、エンジニアのチームがつながり合い、それぞれの急進的で新しいディープラーニング・システムの部分を、次のチームが必要とする瞬間に完成させることを目指して繰り広げられました。
「これは単なるハードウェアではなく、単なるソフトウェアでもありません」と、このプロジェクトに携わった主要なエンジニアの1人、マイク(Mike)は語っています。「3つのUIボタンをクリックするだけで、新しい機能をすべて利用できます」
光の速さ
レースは1年前、2015年3月に始まりました。NVIDIAのCEOであるジェンスン・フアン(Jen-Hsun Huang)は、開催中のGPUテクノロジ・カンファレンスの場で、参加者に対し、近く発表されるGPUアーキテクチャであるPascalは、重要なディープラーニングのタスクにおいて、1年で10倍の性能を発揮するようになると約束したのです。問題は、研究者や会社がこの新しいGPUを基盤としてマシンを構築し、稼働させるには、数週間、場合によっては数か月かかると見込まれることでした。
2か月ほど後、会社の幹部を集めた会議の場でフアンは、Pascalを基盤とするサーバを2016年4月のGTCに間に合わせて構築するよう、NVIDIAのエンジニアリング・チームに発破をかけました。このことで、研究者と会社のスイッチが入り、このGPUのうち8つの力をディープラーニングに振り向けることになりました。
これには、まだ存在もしていないチップを基盤として構築される単なるハードウェアよりも、さらに時間がかかります。25個に分かれたDGX-1のソフトウェアの「スタック」、つまり、オープンソースのUbuntuオペレーティング・システムからNVIDIAのDIGITSディープラーニング・トレーニング・システム、プリミティブのGPUアクセラレーテッド・ライブラリであるCUDA Deep Neural Network(cuDNN)ライブラリ、多くのNVIDIAドライバまでが、調和して稼働する必要がありました。
ジェンスンは、これらの要素をすべて「光の速さ」で組み合わせること、本質的にどこまでが可能なのか、その限界を考え、極限に向かって押し進めることを求めました。
およそ12のエンジニアリング・チームがそれぞれ、即座に動きました。「我々のように、チームで動くノウハウを持っている会社は他にありません」と、プロダクト・アーキテクトでありエンジニアリングのリーダーのジョン(John)は、プロジェクトを総括しました。「リーダーは一握りだけで、そのリーダー達が、プロジェクトの実現に必要となる皆を引っ張っているのです」
実現への道のりは、このようなものでした。
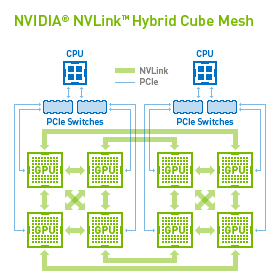
- 2015年5月-エンジニアのチームが、DGX-1内部で8つのGPUをつなぎ合わせる急進的な新しいトポロジの概略を作りました。各GPUのトランジスタ数は150億です。その解決策は、キューブ・メッシュでした。この設計により、ユーザは、8つのGPUをディープラーニング・タスクに当たらせることも、システムを2つのサブシステムに分割し、従来のような高性能の演算に取り組ませることもできます。しかし、これが本当にうまくいくかどうかを知るには、あと7か月待たなければなりませんでした。NVIDIAの高速相互接続テクノロジでメッシュの原動力となるNVLinkを使用する、初めてのGPUであるPascalの最初のサンプルは、2015年第4四半期まで出てこない予定だったのです(「What Is NVLink?」をご覧ください)。
- 2015年9月-ソフトウェア・エンジニアのチームが、NCCL(NVIDIA Collective Communication Library)と呼ばれるシステム・ソフトウェアの構築を開始します。これは、DGX-1のキューブ・メッシュ・トポロジ上で実行されるものです。他のチームは、NCCL上で実行されるソフトウェア・スタックの調整を開始します。この中には、最も利用されるディープラーニングおよび高性能演算ツールであるCaffeやTheano、Torch、TensorFlow、CNTKなどがあります。
- 2015年11月-エンジニアは、チップ工場から来たPascalの最初のサンプルを「育て上げる」という、骨の折れるプロセスを開始します。これは、通常の育成ではありません。Pascalに関しては、NVIDIAのGPU設計者が、ディープラーニングの問題点をユーザが打破できるような機能を盛り込んだ、新しいアーキテクチャを作りました。幅がわずか16nm、指の爪が1分間に伸びる長さの4分の1という特徴を持つ最初のGPUでもあります。(「NVIDIA、NVIDIA Tesla P100アクセラレータにより、ディープ ラーニング、HPCアプリケーションのパフォーマンスを大幅に向上」をご覧ください)。
- 2015年12月-新しいPascal GPUが動作するようになり、エンジニアは、GPUの稼働システムへの組み込みを開始します。問題は、DGX-1の最初の筐体は1月末まで用意できないということです。そこでエンジニアは、金属、粘着テープ、プレキシガラスを使用し、切ったり削ったりを繰り返しながら、間に合わせの用具を作ります。それから2つのGPUを接続し、続いて3つ目、しかし、致命的な問題の可能性があり、4つ目は接続できません。重要なコードの一部に2つのかっこが抜けていたことが判明します。キーを2回叩くと、ネットワークは息を吹き返します。「まるで、そうなる運命だったかのようでした」と、あるエンジニアは語っています。
- 2016年1月-DGX-1の内部が完成すると、NVIDIAの工業デザイン・チームがIrayと呼ばれる新しいデジタル・レンダリング・ツールを使ってDGX-1のベゼルと、機械加工されるアルミ製筐体の正確なモデルの構築を開始します。3月、チームは金属フォームを採用します。これは軽量で非常に強い素材で、飛行機に使用されています。これにより、従来の穿孔金属を使用するよりも、マシンが冷気を素早く吸引できます。
- 2016年3月29日-最終的なサーバのプロトタイプの筐体が、韓国のモデル製作ショップから飛行機で手荷物として戻ってきます。GTCまで1週間を切ったところで、初めてDGX-1のすべての部分が組み合わされます。数日のうちに、まもなく発表される8つのTesla P100 GPUを搭載するシステムは、AlexNetディープラーニング・ベンチマークで10倍の性能向上を達成します。以前は20時間以上かかっていたタスクを2時間で完了したのです。
- 2016年4月3日-GTC開幕の前日、DGX-1はAlexNetにおいて12倍の性能向上を記録します。
- 2016年4月5日-フアンは初のDGX-1サーバを世界にお披露目します。カメラのシャッターが切られ、熱狂的な来場者は呆気にとられて見つめ、記者たちは記事を執筆します。

NVIDIA のCEOであるジェンスン・フアン、当社の2016年GPUテクノロジ・カンファレンスにおいて世界初のディープラーニング・スーパーコンピュータNVIDIA DGX-1を発表
- 2016年5月30日-NVIDIAのエンジニアは、顧客向けDGX-1システムの初のバッチを準備します。あるお客様は待ちきれなかったのですが。GTCでお披露目された最初のユニットは今、当社のシリコンバレー本社の奥にあるサーバーラックでフル稼働中です。NVIDIAのDRIVE PX自律走行プラットフォーム向けにニュージャージーの自律走行チームが収集したデータを処理しているのです。「結局」と、あるNVIDIA社員はマシンを見やりながら思いにふけります。「今、スピードを緩める必要があるのでしょうか?」