
2017 年 12 月 12 日と 13 日の 2 日間に渡って、東京 お台場で開催された「GTC Japan」の初日のプログラムの 1 つが、NVIDIA のディープラーニング システム「DGX」のユーザーが一堂に会し情報交換する「DGX ユーザー グループ ミーティング」。2017 年 10 月に世界中で出荷を開始した「DGX Station」を事前に試した企業が、その性能や使い勝手を明かしました。
NVIDIA DGX-1 は 3U サイズのラックマウント型サーバーですが、DGX Station は、DGX-1に比べて圧倒的にコンパクトで、研究者や開発者など、個人利用に最適なパーソナル AI スーパーコンピューターです。
最新の Volta 世代の GPU、Tesla V100 を 4 基搭載しており、静音を実現する水冷システムで稼働するため、デスク脇に手軽に設置し、簡単に接続してそのコンピューティング パワーを利用できます。
DGX Station でマルチ GPU によるディープラーニングがより手軽に
米 GE の事業会社 Avitas Systems は、ガス パイプラインの保守に DGX-1、DGX Station をすでに活用していますが、日本国内でもリリースに先がけて実績のある日本国内の企業 2 社に試用していただきました。そのうちの 1 社が株式会社 ABEJA です。
同社 Chief Research Officer の緒方 貴紀 氏は、「マルチ GPU を用いた Deep Learning の学習高速化の実験」と題して、同社の DGX Station を用いた検証について解説しました。マルチ GPU によるディープラーニングを手軽に実行できる環境が少なかったのを背景に、DGX Station でマルチ GPU による学習処理が効果的に行えるかどうかを確かめたものです。

株式会社 ABEJA Chief Research Officer 緒方 貴紀 氏
マルチ GPU による並列処理を活かすには、一度に処理するデータ サンプルの数である「バッチ サイズ」を大きくする (多くする) のが効果的とされます。ただし、バッチ サイズを大きくすると、 1 エポックあたりのパラメーター更新量が減ることになるため、パラメーターが十分に学習しきれなくなる可能性があります。そのため、学習率をバッチ サイズに合わせて十分大きくとることが必要ですが、そのバランスはこれまで経験と勘で決めることが通常でした。最近このバランスについて理論解析が進み、下記のような結果が発表されました。

学習率を下げることと、バッチ サイズを大きくすることは同等の効果がある、という最近提出された論文の主張を元に検証
そこで同氏は、バッチ サイズを変えずに学習率を下げていくパターンと、学習率を変えずにバッチ サイズを 512、2048、8192 へと大きくしていくパターンの 2 種類の方法で検証しました。検証に用いた学習テーマは「約 13 万件の人物画像をもとに性別と年齢を推定する」というものです。
検証の結果、1 GPU 時と比較して、4 GPU ではバッチ サイズ 512 で 0.7 倍、2048 で 2.4 倍、8192 で 3.4 倍の処理速度を達成することがわかったと同氏。マルチ GPU でバッチ サイズを大きくして処理しても 1 GPU の時と精度はほとんど変わらず、パラメーター更新回数も約 15 分の 1 に削減できたとのことです。
今回の実験のネットワークでは、1 GPU で処理できる バッチ サイズは 2000 程度が限界になり、バッチ サイズを 8192 にする場合は 4 GPU が必須であることもわかりました。結論として、同氏は「マルチ GPU により、大量のデータセットでも簡易的に高速に学習できる可能性がある」こと、そして「今後の研究次第ではマルチ GPU による学習が主流になっていく可能性がある」ことを示唆しました。
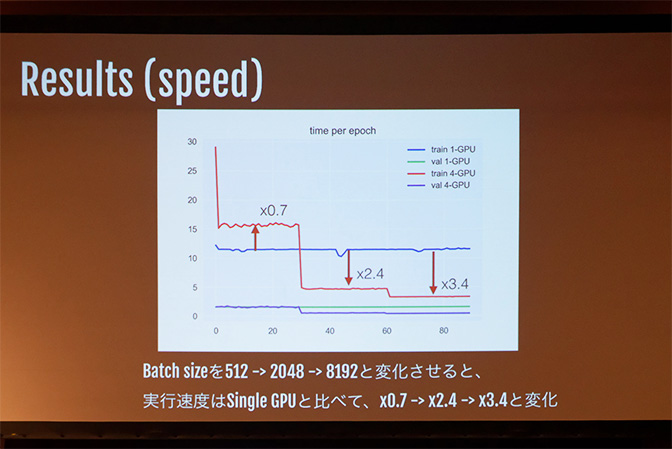
マルチ GPU で処理することで、1 エポック当たりにかかる時間の短縮を実現
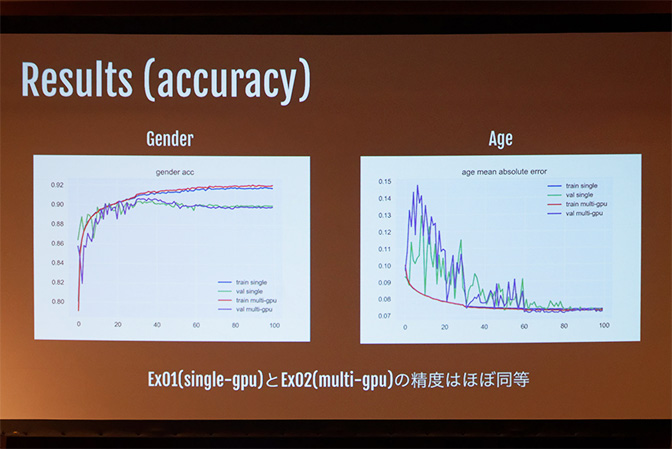
精度についても 1 GPUとほぼ同等で実現
口コミ分析が高速化され、サービス展開のペースも早まる
飲食店口コミサイトである Retty 株式会社も、事前に「DGX Station」を試していただいた企業です。2016 年から Tesla P100 を組み込んだ自作PCで独自に機械学習基盤を構築して運用しており、文章の類似度を計測する「Doc2Vec」を利用して口コミデータからユーザーのベクトル化 (ユーザー タイプの分析) を行っています。
そんな同社から、樽石 将人 氏、鈴木 孝彰 氏、氏原 淳志 氏の 3 名が登壇し、ベンチマーク ソフト「GeekBench」などを用いて「DGX Station」のパフォーマンスを測定した結果を公表しました。



それによると、CUDA Benchmarks のスコアは約 65 万、データ ドライブ (RAID 0 構成の SSD) の READ 性能は 1600MB/s、WRITE 性能は 1300 MB/s を記録。P100 を搭載した同社独自の機械学習基盤での CUDA Benchmarks のスコアは 32 万弱だったため、およそ 2 倍の性能を発揮することがわかったとのこと。
さらに同社は、Retty の 40 万件の店舗評価と、200 万件の口コミを教師データとしたディープラーニング処理を DGX Station で実行し、マルチ GPU でのパフォーマンスを検証しました。正解率が 9 割以上になるまでの時間と処理サンプル数を、GPU の数を変えながら計測。結果としては、マルチ GPU では GPU の数が増えるほど学習が効率化され、高速化することが判明したとしています。
こうした口コミの処理は、従来同社ではデータ量とマシン性能の都合上、1 日以上かけて行っていました。ところが、DGX Station を使用した場合は同じ処理が半日で終わるため、1 日に 2 回実行できるようになるとのこと。この性能を活かすことで、これまでデータから得ていたサービス改善に必要な判断を早めることができ、より一層スピーディーなサービス展開ができるだろう、と語りました。
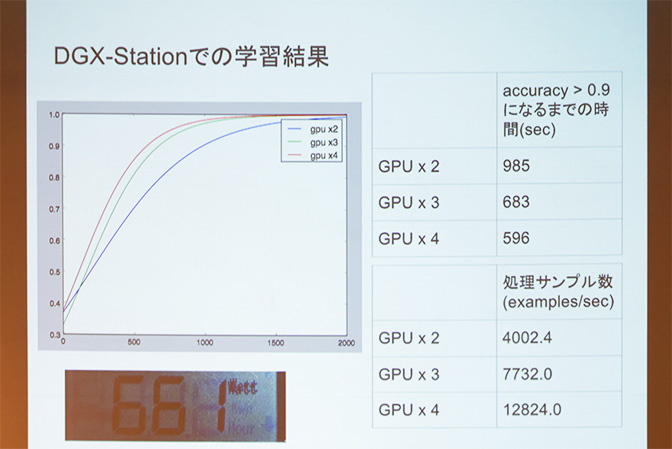
マルチ GPU 処理により、口コミのディープラーニング処理は圧倒的な高速さで完了
普通の PC と同じように扱え、生産性が高まる DGX Station
以上が 2 社による DGX Station の性能検証の内容ですが、両社とも性能の高さとは別に口を揃えて強調していたのが、設置を含むセットアップの簡単さと扱いやすさでした。タワー型フル ATX サイズの DGX Station は、その性能に対して非常にコンパクトで、オフィスのデスク脇に置けるサイズであることと、水冷システムのため静かなこと、一般的な 100 V 電源で使えることがポイント、と言います。
DGX-1 はデータ センターにあり、直接操作する際にはシェルで扱うことになりますが、DGX Station は Linux ベースの GUI OS でわかりやすく操作できるのも利点。手軽にマルチ GPU でディープラーニングが行え、それをデータセンター上ではなく手元で扱えるため、生産性が高く、アイデアを検証するペースも上がるとして、本格的に導入の検討を進めていきたいと話しました。
なお、DGX Station は日本でも販売を開始しており、初回購入であれば、現在特別割引の 25% OFF でご購入いただけます。