
ヘルスケア分野での診断の洞察。インタラクティブ ゲームでのキャラクターの会話。カスタマー サービス エージェントによる自律的な問題解決。AI を活用したこれらのインタラクションはすべて、同じ「知能の単位」、すなわちトークンの上に成り立っています。
このような AI インタラクションを拡大するには、企業はより多くのトークンを賄えるかどうかを検討する必要があります。その答えは、より良いトークノミクスにあります。トークノミクスの本質は、各トークンのコストを引き下げることです。こうしたコスト低下の傾向は、さまざまな業界で広がっています。直近の MIT の研究では、インフラとアルゴリズムの効率化により、最先端水準の性能を実現するための推論コストが年あたり最大 10 分の 1 まで低下していることが示されています。
インフラ効率がいかにトークノミクスを改善するかを理解するために、高速印刷機を例に考えてみましょう。インク、電力、機械自体への投資を少し上積みするだけで印刷量が 10 倍になるなら、1 ページあたりの印刷コストは低下します。これと同様に、AI インフラへの投資でも、コスト増以上にトークン出力量を大きく伸ばせる可能性があり、結果としてトークンあたりのコストを大きく下げられます。
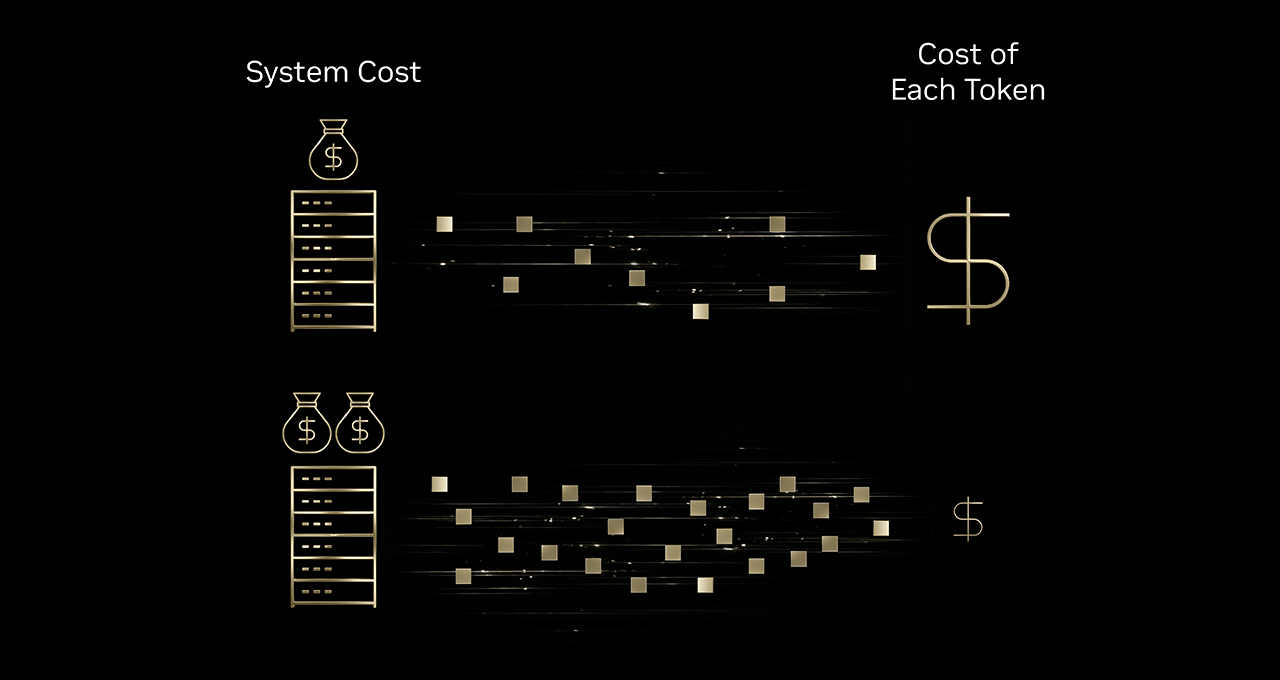
Baseten、DeepInfra、Fireworks AI、Together AI といった主要な推論プロバイダーが NVIDIA Blackwell プラットフォームを採用しているのは、まさにこのためです。Blackwell は NVIDIA Hopper プラットフォームと比較して、トークンあたりのコストを最大 10 分の 1 に抑えるのに役立ちます。
これらのプロバイダーは高度なオープン ソース モデルをホストしており、そうしたモデルは現在、最先端水準のインテリジェンスに到達しています。最先端水準のオープン ソース インテリジェンス、NVIDIA Blackwell の緊密なハードウェアとソフトウェアの協調設計、そして各社が最適化した推論スタックを組み合わせることで、これらのプロバイダーはあらゆる業界の企業に向けてトークン コストの大幅な削減を可能にしています。
ヘルスケア — Baseten と Sully.ai が AI 推論コストを 10 分の 1 に削減
ヘルスケア業界では、医療コーディング、文書作成、保険書類管理といった煩雑で時間のかかる作業により、医師が患者と向き合える時間が削られています。
Sully.ai は、医療コーディングや記録作成といった定型業務を担える「AI 従業員」を開発することで、この課題の解決を支援しています。同社のプラットフォームが拡大する中で、クローズド ソースの独自モデルが 3 つのボトルネックを生んでいました。すなわち、リアルタイムの臨床ワークフローにおける予測不能なレイテンシ、収益の伸びを上回るペースで増加する推論コスト、そしてモデルの品質と更新を十分に制御できないことです。
これらのボトルネックを克服するため、Sully.ai は Baseten のモデル API を活用しています。この API は、gpt-oss-120b などのオープン ソース モデルを NVIDIA Blackwell GPU 上に展開します。Baseten は、低精度の NVFP4 データ形式、NVIDIA TensorRT-LLM ライブラリ、NVIDIA Dynamo 推論フレームワークを用いて、推論の最適化を実現しました。同社は、NVIDIA Hopper プラットフォームと比較して 1 ドルあたりのスループットが最大 2.5 倍向上することを確認し、モデル API の実行基盤として NVIDIA Blackwell を採用しました。
その結果、Sully.ai の推論コストは 90% 低下し、従来のクローズド ソース実装と比較して 10 分の 1 になりました。同時に、医療記録の生成などの重要なワークフローにおける応答時間が 65% 向上しました。同社は現在、データ入力などの手作業に費やされていた 3,000 万分以上の時間を医師に還元しています。
ゲーミング — DeepInfra と Latitude がトークンあたりのコストを 4 分の 1 に削減
Latitude は、同社のアドベンチャー ストーリー ゲーム『AI Dungeon』と、近日登場予定の AI 搭載ロール プレイング ゲーム プラットフォーム『Voyage』を通じて、AI ネイティブ ゲームの未来を築いています。そこでは、プレイヤーはあらゆる行動を自由に選択し、自分だけの物語を紡ぎながら、世界を作ったり、そこで遊んだりできます。
同社のプラットフォームは、プレイヤーの行動に応答するために大規模言語モデルを使用しています。とはいえ、プレイヤーの行動のたびに推論リクエストが発生するため、スケーリングの課題も伴います。コストはエンゲージメントに応じて増大し、体験をシームレスに維持するには、応答時間も十分に速く保つ必要があります。

Latitude は、NVIDIA Blackwell GPU と TensorRT-LLM を搭載した DeepInfra の推論プラットフォーム上で、大規模なオープン ソース モデルを実行しています。大規模な Mixture of Experts (MoE) モデルでは、DeepInfra は 100 万トークンあたりのコストを、NVIDIA Hopper プラットフォームの 20 セントから、Blackwell では 10 セントに引き下げました。さらに、Blackwell ネイティブの低精度 NVFP4 形式に移行したことで、コストはわずか 5 セントまで下がりました。顧客が期待する精度を維持しながら、トークンあたりのコストはトータルで 4 分の 1 に改善しています。
このような大規模 MoE モデルを DeepInfra の Blackwell 搭載プラットフォーム上で実行することで、Latitude は高速で信頼性の高い応答をコスト効率良く提供できています。DeepInfra 推論プラットフォームは、トラフィックの急増にも確実に対応しながらこの性能を実現しており、その結果 Latitude がプレイヤー体験を損なうことなく、より高性能なモデルを展開することを可能にしています。
エージェント型チャット — Fireworks AI と Sentient Foundation が AI コストを最大 50% 削減
Sentient Labs は、AI 開発者を結集し、すべてオープン ソースの強力なリーズニング AI システムを構築することに注力しています。その目標は、セキュアな自律性、エージェント型アーキテクチャ、継続的な学習に関する研究を通じて、より難しいリーズニングの課題を解決できる方向へ AI を加速させることです。
同社初のアプリである Sentient Chat は、複雑なマルチエージェントのワークフローをオーケストレーションし、コミュニティの 10 以上の専門 AI エージェントを統合しています。そのため、Sentient Chat には膨大なコンピューティング リソースが必要です。単一のユーザー クエリが自律的なインタラクションの連鎖を引き起こし、その結果、コストのかかるインフラのオーバーヘッドにつながるためです。
この規模と複雑さに対応するため、Sentient は NVIDIA Blackwell 上で動作する Fireworks AI の推論プラットフォームを使用しています。Blackwell に最適化された Fireworks の推論スタックにより、Sentient は従来の Hopper ベースの展開と比較して、コスト効率を 25%~50% 改善しました。
GPU あたりのスループットが向上したことで、同社は同じコストのまま、同時接続ユーザーを大幅に増やせるようになりました。このプラットフォームのスケーラビリティは、口コミや拡散で急速に広がったローンチを支え、24 時間で 180 万人のウェイトリスト登録者を迎え、1 週間で 560 万件のクエリを処理しながら、一貫して低レイテンシを維持しました。
カスタマー サービス — Together AI と Decagon がコストを 6 分の 1 に削減
音声 AI を使ったカスタマー サービスの通話は、わずかな遅延でもユーザーがエージェントにかぶせて話したり、電話を切ったり、信頼を失ったりしやすいため、不満に終わることが少なくありません。
Decagon は法人向けカスタマー サポート用の AI エージェントを構築しており、その中でも AI 音声対応は最も負荷の高いチャネルです。Decagon が必要としていたのは、予測不能なトラフィック負荷下でも 1 秒未満で応答でき、24 時間 365 日の音声展開を支えられるトークノミクスを備えたインフラでした。

Together AI は、Decagon のマルチモデル音声スタックの実稼働推論を NVIDIA Blackwell GPU 上で実行しています。両社は連携して、次の重要な最適化を行いました。小規模モデルをトレーニングしてより高速に応答を生成させつつ、大規模モデルがバックグラウンドで精度を検証する投機的デコード、応答を高速化するために会話の繰り返し要素をキャッシュすること、そして性能を損なうことなくトラフィック急増に対応できる自動スケーリングの構築です。
Decagon は、1 回のクエリで数千トークンを処理する場合でも、応答時間が 400 ミリ秒未満であることを確認しました。クエリあたりのコスト (1 回の音声インタラクションを完了するための総コスト) は、クローズド ソースの独自モデルを使用した場合と比較して 6 分の 1 になりました。これは、Decagon のマルチモデル アプローチ (オープン ソースのモデルと、NVIDIA GPU 上で社内トレーニングしたモデルの併用)、NVIDIA Blackwell の緊密な協調設計、そして Together AI の最適化された推論スタックを組み合わせた結果です。
緊密な協調設計によるトークノミクスの最適化
ヘルスケア、ゲーミング、カスタマー サービス分野に見られる劇的なコスト削減は、NVIDIA Blackwell の効率性によって実現されています。NVIDIA GB200 NVL72 システムはこの効果をさらに拡大し、NVIDIA Hopper と比較して、リーズニング MoE モデルのトークンあたりコストを 10 分の 1 にするという画期的な削減を実現しています。
スタック全層 (コンピューティング、ネットワーク、ソフトウェア) にまたがる NVIDIA の緊密な協調設計、NVIDIA のパートナー エコシステムにより、大規模運用におけるトークンあたりコストの大幅な削減が可能になっています。
この勢いは NVIDIA Rubin プラットフォームでも続いています。6 つの新たなチップを単一の AI スーパーコンピューターに統合し、Blackwell と比較して性能を 10 倍に高めると同時に、トークン コストを 10 分の 1 にします。
NVIDIA のフルスタックの推論プラットフォームの詳細をご覧いただき、AI 推論におけるトークノミクスをどのように向上させているかをご確認ください。