
編集者注:本記事は「Think SMART」シリーズの最新号です。このシリーズでは、NVIDIA のフルスタック推論プラットフォームの最新機能を活かし、主要な AI サービス プロバイダー、開発者、企業が推論パフォーマンスと投資収益率をどのように高められるかに焦点を当てています。
NVIDIA Blackwell は、独立系の最新ベンチマークである SemiAnalysis InferenceMAX v1 において、テスト対象のすべてのモデルとユースケースで、最高のパフォーマンスと効率性、そして最も低い総所有コストを実現しました。
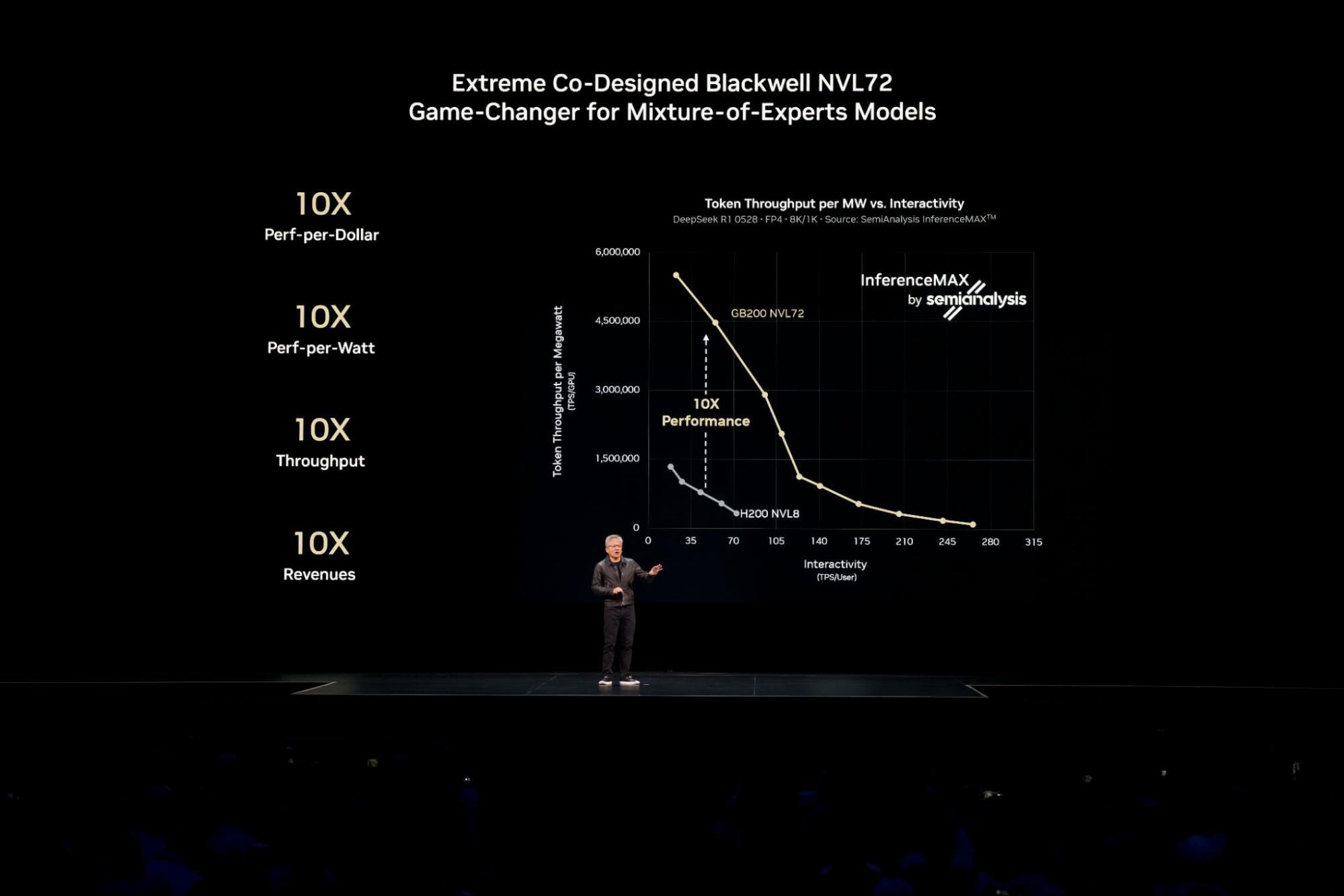
大規模な Mixture of Experts (MoE) モデルなど、現在の最も複雑な AI モデルでこの業界最先端のパフォーマンスを実現するには、推論を複数のサーバー (ノード) に分散 (または分離) し、数百万人規模の同時ユーザーにサービスを提供しつつ、より高速な応答を実現する必要があります。
NVIDIA Dynamo ソフトウェア プラットフォームは、こうした強力なマルチノード機能を本番環境で活用できるようにし、企業が既存のクラウド環境全体で、ベンチマークで実証されたのと同じレベルのパフォーマンスと効率性を実現できるようにします。本記事では、マルチノード推論への移行がどのようにパフォーマンス向上をもたらすのか、そしてクラウド プラットフォームがこのテクノロジをどのように活用しているのかを解説します。
分離型推論を活用したパフォーマンス最適化
単一の GPU やサーバーに収まる AI モデルの場合、開発者は高いスループットを実現するために、多数の同一モデルのレプリカを複数ノードで並列実行することがよくあります。Signal65 の主席アナリストである Russ Fellows 氏は、最新の論文で、このアプローチにより 72 基の NVIDIA Blackwell Ultra GPU を用いて、毎秒 110 万トークンという業界初の総スループット記録が達成されたと報告しています。
多数の同時ユーザーにリアルタイムでサービスを提供するために AI モデルをスケールする場合や、長い入力シーケンスを伴う負荷の高いワークロードを処理する場合、分離型サービングと呼ばれる手法を用いることで、パフォーマンスと効率性をさらに向上させることができます。
AI モデルのサービングには、入力プロンプトを処理するプリフィルと、出力を生成するデコードの 2 つのフェーズがあります。従来、これらのフェーズは同じ GPU 上で実行されていたため、非効率やリソースのボトルネックを招く可能性がありました。
分離型サービングは、これらのタスクを個別に最適化された GPU にインテリジェントに割り振ることで、この問題を解決します。このアプローチにより、ワークロードの各部分がその特性に最も適した最適化手法を用いて実行され、全体のパフォーマンスが最大化されます。DeepSeek-R1 をはじめとする、現在の大規模な AI リーズニング モデルや MoE モデルでは、分離型サービングが不可欠です。
NVIDIA Dynamo は、分離型サービングなどの機能を GPU クラスタ全体に本番規模で容易に展開できます。
こうした機能は、既に実環境で価値を生み出しています。
例えば、Baseten は NVIDIA Dynamo を活用することで、ロングコンテキストのコード生成における推論サービングを 2 倍に高速化し、スループットを 1.6 倍に向上させました。しかも、ハードウェア コストの追加は一切ありません。このようなソフトウェア主導のパフォーマンス向上により、AI プロバイダーはインテリジェンスを生み出すコストを大幅に削減できます。
クラウドにおける分離型推論のスケール
Kubernetes は、コンテナ化されたアプリケーション管理の業界標準として大規模な AI トレーニングを支えてきました。こうした特性から、エンタープライズでの AI 展開において、分離型サービングを数十または数百のノードにスケールする基盤としても適しています。
すべての主要なクラウド プロバイダーによるマネージド Kubernetes サービスに NVIDIA Dynamo が統合されたことで、ユーザーは GB200 および GB300 NVL72 を含む NVIDIA Blackwell システム全体でマルチノード推論をスケールでき、エンタープライズでの AI 展開に求められるパフォーマンス、柔軟性、信頼性を得ることができます。
- Amazon Web Services は、NVIDIA Dynamo と Amazon EKS の統合により、顧客の生成 AI 推論を加速しています。
- Google Cloud は、自社の AI Hypercomputer 上でエンタープライズ規模の大規模言語モデル (LLM) 推論を最適化するための Dynamo レシピを提供しています。
- Microsoft Azure は、Azure Kubernetes Service 上で NVIDIA Dynamo と ND GB200-v6 GPU を使用したマルチノード LLM 推論を実現しています。
- Oracle Cloud Infrastructure (OCI) は、OCI Superclusters と NVIDIA Dynamo を活用し、マルチノード LLM 推論を実現しています。
大規模なマルチノード推論の実現に向けた動きは、ハイパースケーラーだけにとどまりません。
例えば、Nebius は大規模な推論ワークロードに対応するため、自社クラウドを設計しています。このクラウドは NVIDIA アクセラレーテッド コンピューティング インフラを基盤とし、エコシステム パートナーとして NVIDIA Dynamo と連携しています。
NVIDIA Dynamo 内の NVIDIA Grove による Kubernetes 上での推論の簡素化
分離型 AI 推論では、プリフィル、デコード、ルーティングなど、それぞれ異なるニーズを持つ専門化されたコンポーネント群を調整して連携させる必要があります。Kubernetes にとっての課題は、もはやモデルの並列コピーを増やすことではなく、これらの個別のコンポーネントを 1 つの統合された高性能システムとして巧みに指揮することにあります。
NVIDIA Dynamo で利用可能なアプリケーション プログラミング インターフェイスである NVIDIA Grove を使用すると、ユーザーは単一の高レベルな仕様を提供するだけで、推論システム全体を記述できます。
例えば、この単一の仕様の中で、ユーザーは要件を次のように宣言できます。「プリフィル用に 3 つの GPU ノード、デコード用に 6 つの GPU ノードが必要です。また、単一のモデル レプリカに属するすべてのノードを同じ高速インターコネクト上に配置し、応答時間を最短にする必要があります」
Grove はその仕様に基づき、複雑な調整をすべて自動的に処理します。関連するコンポーネントを適切な比率と依存関係を維持しながらスケールして、適切な順序で起動し、クラスター全体に戦略的に配置することで、高速かつ効率的な通信を実現します。NVIDIA Grove の始め方については、こちらの技術ブログで詳しく紹介しています。
AI 推論の分散化が進む中、Kubernetes と、NVIDIA Grove を備えた NVIDIA Dynamo を組み合わせることで、開発者はインテリジェントなアプリケーションの構築とスケールをより容易に行えるようになります。
NVIDIA の AI 大規模シミュレーションもぜひお試しください。ハードウェアと展開方法の選択がパフォーマンス、効率、ユーザー体験にどう影響するかを確認できます。分離型サービングについてさらに詳しく知りたい方や、Dynamo と NVIDIA GB200 NVL72 システムがどのように連携して推論パフォーマンスを高めるのかを知りたい方は、こちらの技術ブログをご覧ください。
NVIDIA Think SMART ニュースレターにご登録いただいた方には、最新情報を毎月メールでお届けします。