
現代のハイパフォーマンス コンピューティング (HPC) は、単に高速計算を可能にしているだけではありません。科学的なブレークスルーを生み出す AI システムの基盤となっているのです。
HPC は幾度となく進化を遂げてきましたが、そのどれもがテクノロジの独創的な再利用をきっかけとしています。例えば、初期のスーパーコンピューターは市販のコンポーネントを使用していました。その後、研究者たちはパーソナル コンピューターから強力なクラスターを構築し、ゲーミング グラフィックス カードを科学研究に採用することさえありました。
今日の HPC システムは、その多くが NVIDIA アクセラレーテッド コンピューティングを搭載しており、スピードを重視して設計されています。本日 ISC 2025 で発表された、世界で最もパワフルなスーパーコンピューターの最新の TOP500 リストは、その重要性を改めて明示しています。リストに掲載されたシステムの 77% は NVIDIA 搭載のものです。
同時に、Tensor コアなどの革新的な機能により、行列乗算などの一般的な演算の計算が高速化され、混合精度 (複数の浮動小数点精度フォーマットを組み合わせる手法。詳細は後述) などの手法の使用が増えることで、パフォーマンスとエネルギー効率が向上し、気候科学や医療などの分野で飛躍的な進歩が促進されています。
TOP500 のリーダーに NVIDIA が搭載
NVIDIA はスーパーコンピューティングの分野をリードし続けており、最新の TOP500 リストに含まれる 381 のシステムに搭載されています。これには、トップ 10 に新たにランクインし、初登場 4 位の Jülich Supercomputing Centre の JUPITER スーパーコンピューターも含まれます。
TOP500 のトップ 100 システムのうち、83 システムがアクセラレーテッド コンピューティングを採用しており、CPU のみを使用するシステムはわずか 17 システムでした。
さらに、世界で最もエネルギー効率の高い FP64 スーパーコンピューターの最新 Green500 リストの上位 2 システムは、NVIDIA GH200 Grace Hopper Superchip を搭載しており、上位 10 システムのうち 9 システムは NVIDIA によって高速化されています。
科学のための Tensor コア
AI の性能は、浮動小数点演算の演算量を増やすことだけでは向上しません。Tensor コアの活用など、ハードウェアとソフトウェアの融合がますます重要になっています。
Tensor コアは、AI とディープラーニングの基盤となる計算である行列演算を高速化するために設計された、NVIDIA GPU に搭載された高度なコンポーネントです。複雑な計算をより効率的に処理することで、モデルのトレーニングや推論などのプロセスを高速化します。
Tensor コアは、特に組織がモデルのトレーニングに FP8 などの低精度を採用するにつれて、一般的な行列演算の計算速度を向上させます。精度を維持しながら、精度を一段階下げるごとにスループットがほぼ 2 倍になります。現在、シミュレーション ワークロード内の特定の演算のみが、Tensor コアの恩恵を受けることができます。これらの演算は、多くの場合、全体の実行時間のごく一部を占め、全体的なパフォーマンスに大きな影響を与えることはほとんどありません。
AI 向けに構築された低精度の Tensor コアに割り当てられる GPU の物理領域が増えるにつれ、HPC コミュニティは再びハードウェアを再利用して科学的発見を推進する機会を得ています。
これを実現するため、NVIDIA は、科学シミュレーションに関連するより広範なユースケースで Tensor コアを活用するための新しい手法に投資しています。
理化学研究所計算科学研究センターの内野佑基氏と芝浦工業大学の尾崎克久教授による論文では、Tensor コア内の Matrix Multiply Accelerators (整数行列乗算アクセラレータ) と「尾崎スキーム」と呼ばれるアルゴリズムを用いて、GPU の整数ユニットが FP64 を含む任意精度を実現する方法が示されました。
この手法に着想を得て、NVIDIA は、GPU Tensor コアのより大規模なセットを用いて高精度テンソルおよび行列計算を高速化するライブラリを開発しており、精度、パフォーマンス、エネルギー効率の向上に重点を置いています。
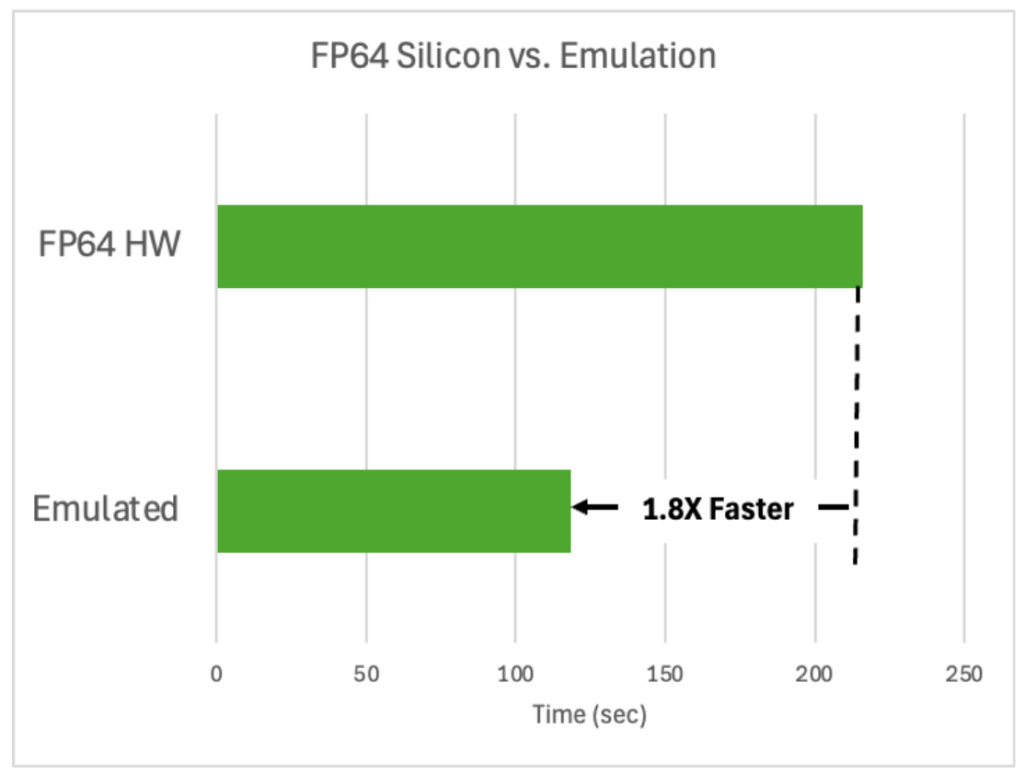
これらのライブラリの使用によって、すでに驚くべき効果が実証されています。約 1,000 個の原子を紫外線にさらすシリコン シミュレーションでは、FP64 ハードウェアを使用した場合と比較して 1.8 倍の速度で実行され、同等の結果を出し、時間とエネルギーの両方を節約できました。
これらの新しいライブラリを活用することにより、BerkeleyGW などの一般的な HPC シミュレーションは、低精度の Tensor コアの恩恵をうけることが可能となり、性能とエネルギー効率が飛躍的に向上します。
AI スーパーコンピューティングが科学を推進
TOP500 リストは、今日のスーパーコンピューターの高精度な速度を強調していますが、混合精度と AI を組み合わせた科学的発見を支えている驚異的な影響力については語っていません。
昨年、ノーベル化学賞と物理学賞は AI を活用した研究者に授与されました。Demis Hassabis 氏とJohn Jumper 氏は、Google DeepMind のタンパク質構造予測モデル AlphaFold の開発で受賞しました。また、トロント大学名誉教授の Geoff Hinton 氏とプリンストン大学名誉教授の John Hopfield 氏は、ニューラルネットワーク アーキテクチャの進化の功績で表彰されました。
ハイパフォーマンス コンピューティング (HPC) 分野において権威あるゴードン ベル賞は、KAUST の David Keyes 氏のチームにも授与されました。同チームは、過去 80 年間の大気、地表、海洋波の変動を地表から高度 80km までの 137 の高度レベルで 1 時間ごとに推定する膨大な ERA5 気候データセットをエミュレートする混合精度手法を開発しました。
混合精度とは、複数の浮動小数点精度フォーマットを組み合わせる手法です。低精度のデータ型を使用することで、パフォーマンスと効率性が向上し、アプリケーションがリソースを削減しながらパフォーマンスを向上させることができます。
科学者が新しい AI モデルを構築し、科学ワークフローを加速させる中で、科学分野における混合精度の使用はますます一般的になりつつあります。
英国では、NVIDIA Grace Hopper を搭載したブリストル大学の Isambard-AI システムが、Nightingale などのモデルのトレーニングに混合精度を使用しました。
Nightingale は、画像診断、心臓病学、電子健康記録を統合した、ヘルスケアおよび生物医学研究のためのマルチモーダル基盤モデルです。他のヘルスケア向け大規模言語モデルとは異なり、Nightingale はテキストベースのリーズニングだけでなく、画像パターンや標準的な診断手法を活用し、膨大な患者データを用いて医学的知見を提供します。Nightingale の目標は、医師のオフィス アシスタントや遠隔医療トリアージ システムなど、他のヘルスケア アプリケーションの基盤となることです。
Isambard-AI は、混合精度を用いることで Nightingale のようなマルチモーダル LLM のトレーニングに必要な大規模かつ高い精度を、トレーニングや推論に過剰なハードウェアを必要とせずに実現しました。
HPC の次のイテレーションに向けて
アクセラレーテッド コンピューティング、高度なテンソル テクノロジ、そして混合精度手法の組み合わせは、計算科学を変革し、AI を活用したさらなる革新の可能性を示しています。
JUPITER のようなシステムが TOP500 に加わり、Isambard-AI のような AI を科学研究に活用する新たな研究や、高精度タスクにおける Tensor コアの性能を加速させる尾崎エミュレーション手法などのイノベーションが生まれるにつれ、新たな時代が到来しつつあります。
スーパーコンピューターは、いくつかの指標で高速化を続けますが、速度だけでは十分ではありません。重要な科学的課題に対する新たな洞察を得るには、科学的な厳密さを損なうことなく発見を加速し、科学コミュニティや HPC コミュニティ、そして世界のニーズを満たす、スマートで柔軟なアプローチが不可欠です。
ISC に参加
ISC 2025 では、最新の AI とハイパフォーマンス コンピューティング (HPC) の革新について初公開します。
E30 の NVIDIA ブースでは、最新の技術革新が発見と持続可能性をいかに加速させているかに関する展示を行っています。