
Retrieval-Augmented Generation は、外部ソースから取得した情報を用いて、生成 AI モデルの精度と信頼性を向上させるテクノロジです。
生成 AI の最新の進歩を理解するために、法廷を想像してみてください。
裁判官は、一般的な法律の理解に基づいて審理し、判決を下します。時には、医療ミス訴訟や労働争議など、特定の専門知識が必要なケースもあるため、裁判官は裁判所書記官を法務図書館に送り、引用できる判例や具体的な事例を探させます。
優れた裁判官のように、大規模言語モデル (LLM) は人間の様々なクエリに答えることができます。しかし、出典を引用した信頼できる回答を提供するためには、モデルにも調査を行うアシスタントが必要です。
AI の裁判所書記官は、Retrieval-Augmented Generation 、略して RAG と呼ばれるプロセスです。
名前の物語
この名前を生み出した 2020 年の論文の主執筆者である Patrick Lewis 氏 は、現在では生成 AI の未来を示す何百もの論文や何十もの商用サービスにわたって増え続けている手法を説明するための、このお世辞にも良いとは言えない略語について謝罪しました。
Lewis 氏は、「私たちの仕事がこれほど広まるとわかっていたら、間違いなくこの名前にもっと工夫を凝らしたでしょう」と、データベース開発者の地域会議で自身のアイデアを披露していたシンガポールでのインタビューで語りました。
 Patrick Lewis 氏
Patrick Lewis 氏
現在 AI スタートアップの Cohere で RAG チームを率いる Lewis 氏は次のようにも述べています。「私たちは、もっと響きの良い名前にするつもりでしたが、いざ論文を書こうとすると、誰もより優れたアイデアを思いつきませんでした」
Retrieval-Augmented Generationとは何か?
Retrieval-Augmented Generation は、外部ソースから取得した情報を用いて、生成 AI モデルの精度と信頼性を向上させるテクノロジです。
いわば、LLM の機能の不足を補うものです。LLM はその内部ではニューラルネットワークであり、一般的にはパラメーター数で評価されます。LLM のパラメーターは基本的に、人間がどのように単語を使って文章を作るかという一般的なパターンを表しています。
パラメーター化された知識と呼ばれることもあるこの深い理解によって、LLM は一般的なプロンプトに光速で応答するのに役立ちます。しかし、最近のトピックやより具体的なトピックに深く入り込みたいユーザーには役に立ちません。
内外のリソースを組み合わせる
Lewis 氏 たちは、生成 AI サービスを外部リソース、特に最新の技術的詳細に富むリソースにリンクさせるために、Retrieval-Augmented Generation を開発しました。
旧 Facebook AI Research (現 Meta AI)、ユニバーシティ カレッジ ロンドン、ニューヨーク大学の共著によるこの論文は、RAG を「汎用的なファインチューニング レシピ」と呼んでいます。
ユーザーの信頼を築く
Retrieval-Augmented Generation は、研究論文の脚注のように引用できるソースをモデルに与えます。これにより、ユーザーはあらゆる回答をチェックすることができ、それが信頼に繋がります。
さらに、このテクノロジはユーザーのクエリのあいまいさを解消するのに役立ちます。また、幻覚と呼ばれることもある、モデルが間違った推測をする可能性も減らすことができます。
RAG のもう一つの大きな利点は、比較的簡単だということです。Lewis 氏と論文の共著者 3 人によるブログによれば、開発者はわずか 5 行のコードでこのプロセスを実装できるといいます。
そのため、この手法は追加のデータセットでモデルを再トレーニングするよりも高速かつ低コストです。また、新しいソースをその場でホットスワップすることもできます。
Retrieval-Augmented Generation をどう使うか
Retrieval-Augmented Generation を使えば、ユーザーは基本的にデータ リポジトリと会話をすることができ、新しい体験を可能にします。つまり、RAG のアプリケーションは、何倍ものデータセットを利用できる可能性があるということです。
例えば、医療指標で補完された生成 AI モデルは、医師や看護師にとって素晴らしいアシスタントになるでしょうし、金融アナリストは、市場データとリンクしたアシスタントから恩恵を受けるでしょう。
実際、ほとんどすべてのビジネスで、技術マニュアルやポリシー マニュアル、ビデオやログをナレッジ ベースと呼ばれるリソースに変えることができ、LLM を強化できます。これらのソースは、顧客や現場のサポート、従業員のトレーニング、開発者の生産性向上といったユースケースを可能にします。
AWS、IBM、Glean、Google、Microsoft、NVIDIA、Oracle、Pinecone などの企業が RAG を採用している理由は、その幅広い可能性にあります。
Retrieval-Augmented Generation を始めよう
NVIDIA は、ユーザーが始めやすいように、Retrieval-Augmented Generation のリファレンス アーキテクチャを開発しました。このリファレンス アーキテクチャには、チャットボットのサンプルや、ユーザーがこの新しいメソッドによる独自のアプリケーションを作成するために必要な要素が含まれています。
このワークフローでは、生成 AI モデルの開発とカスタマイズのためのフレームワークである NVIDIA NeMo や、生成 AI モデルを実運用で実行するための NVIDIA Triton Inference Server や NVIDIA TensorRT-LLM などのソフトウェアを使用します。
このソフトウェア コンポーネントはすべて、NVIDIA AI Enterprise の一部であり、企業が必要とするセキュリティ、サポート、安定性を備えた、実運用可能な AI の開発と展開を加速するソフトウェアプ ラットフォームです。
RAG ワークフローで最高のパフォーマンスを得るには、データを移動し処理するための大量のメモリとコンピューティングが必要です。288GB の高速な HBM3e メモリと 8 ペタフロップスの演算能力を持つ NVIDIA GH200 Grace Hopper Superchip は理想的であり、CPU を使用する場合に比べて 150 倍の高速化を実現できます。
企業が RAG に慣れれば、既製またはカスタムの様々な LLM を内部または外部のナレッジベースと組み合わせて、従業員や顧客を支援する様々なアシスタントを作成することができます。
RAG はデータセンターを必要としません。NVIDIA ソフトウェアが可能にするあらゆる種類のアプリケーションは、ユーザーがノート PC でもアクセスできるので、LLM を Windows PC で動かすこともできます。
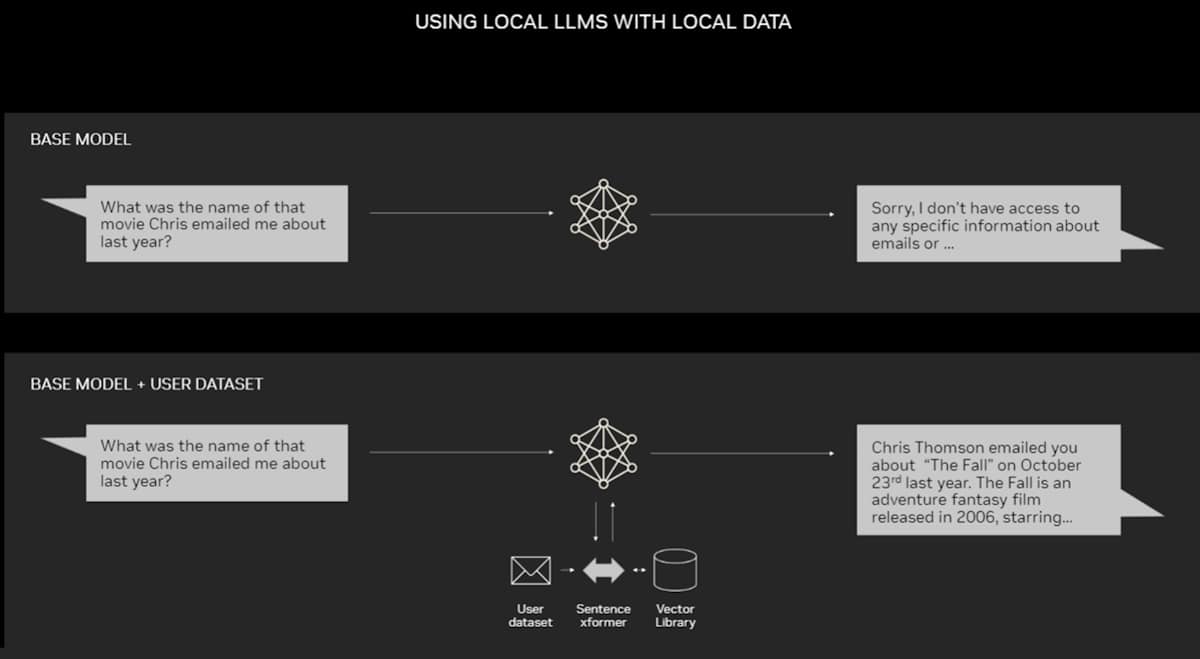 PC 上での RAG のアプリケーション例
PC 上での RAG のアプリケーション例
NVIDIA RTX GPU を搭載した PC は、一部の AI モデルをローカルで実行することができます。PC 上で RAG を使用することで、ユーザーは電子メール、メモ、記事など、プライベートなナレッジソースにリンクし、回答を改善させることができます。そしてユーザーは、データソース、プロンプト、回答がすべてプライベートで安全であると確信できます。
最近のブログでは、TensorRT-LLM for Windows によって RAG を高速化し、より良い結果を迅速に得る例を紹介しています。
Retrieval-Augmented Generation の歴史
このテクノロジのルーツは、少なくとも 1970 年代初頭にさかのぼります。その頃、情報検索の研究者たちは、自然言語処理 (NLP) を使ってテキストにアクセスする質問応答システムと呼ばれるアプリで試作し、それは最初、野球のような狭いトピックのものでした。
この種のテキスト マイニングの背後にある概念は、長年にわたってかなり不変です。しかし、それを駆動する機械学習エンジンは大きく成長し、その有用性と人気を高めています。
1990 年代半ば、Ask Jeeves サービス (現在の Ask.com) は、身なりの良い付き人のマスコットで質問応答を普及させました。IBM の Watson は 2011 年、クイズ番組『Jeopardy !』で 2 人の人間のチャンピオンを見事に破り、一躍テレビ界の有名人になりました。
今日、LLM は質問応答システムをまったく新しいレベルに引き上げています。
ロンドンの研究室からの洞察
Lewis 氏がユニバーシティ カレッジ ロンドンで NLP の博士号を取得し、Meta 社の新しいロンドンの AI ラボで働いていたとき、2020 年の独創的な論文が公開されました。チームは、LLM のパラメータに多くの知識を詰め込む方法を模索し、その進捗状況を測定するために開発したベンチマークを使用していました。
以前の方法をベースに、Google の研究者らが発表した論文に触発されたこのグループは、「中央に検索インデックスがあり、学習して任意のテキスト出力を生成できるトレーニングされたシステムという、説得力のあるビジョンを持っていました」と Lewis 氏は振り返ります。
 IBM の質問回答システム「Watson」は、テレビのクイズ番組『Jeopardy!』で大勝し、一躍有名人となりました
IBM の質問回答システム「Watson」は、テレビのクイズ番組『Jeopardy!』で大勝し、一躍有名人となりました
Lewis 氏が、Meta の別のチームが開発した有望な検索システムを、現在進行中の研究に取り入れたところ、最初の結果は予想外に素晴らしいものでした。
「上司に見せたら、『おお、これは大成功だ。このようなことは滅多に起こらない』と言いました。こういったワークフローは最初に正しく設定するのが難しいからです」
Lewis 氏 はまた、チーム メンバーの Ethan Perez 氏と Douwe Kiela 氏 (それぞれニューヨーク大学と Facebook AI Research 出身) の大きな貢献も認めています。
NVIDIA GPU のクラスタ上で実行されたこの研究は、完成後、生成 AI モデルをより権威のある信頼できるものにする方法を示しました。それ以来、この研究は何百もの論文に引用され、現在も活発な研究分野として、その概念を増幅、拡張しています。
Retrieval-Augmented Generation の仕組み
NVIDIA のテクニカル ブリーフに記載されている RAG プロセスの概要は以下の通りです。
ユーザーが LLM に質問すると、AI モデルはクエリを別のモデルに送り、機械が読めるように数値フォーマットに変換します。クエリの数値バージョンは、エンベッディングやベクトルと呼ばれることもあります。
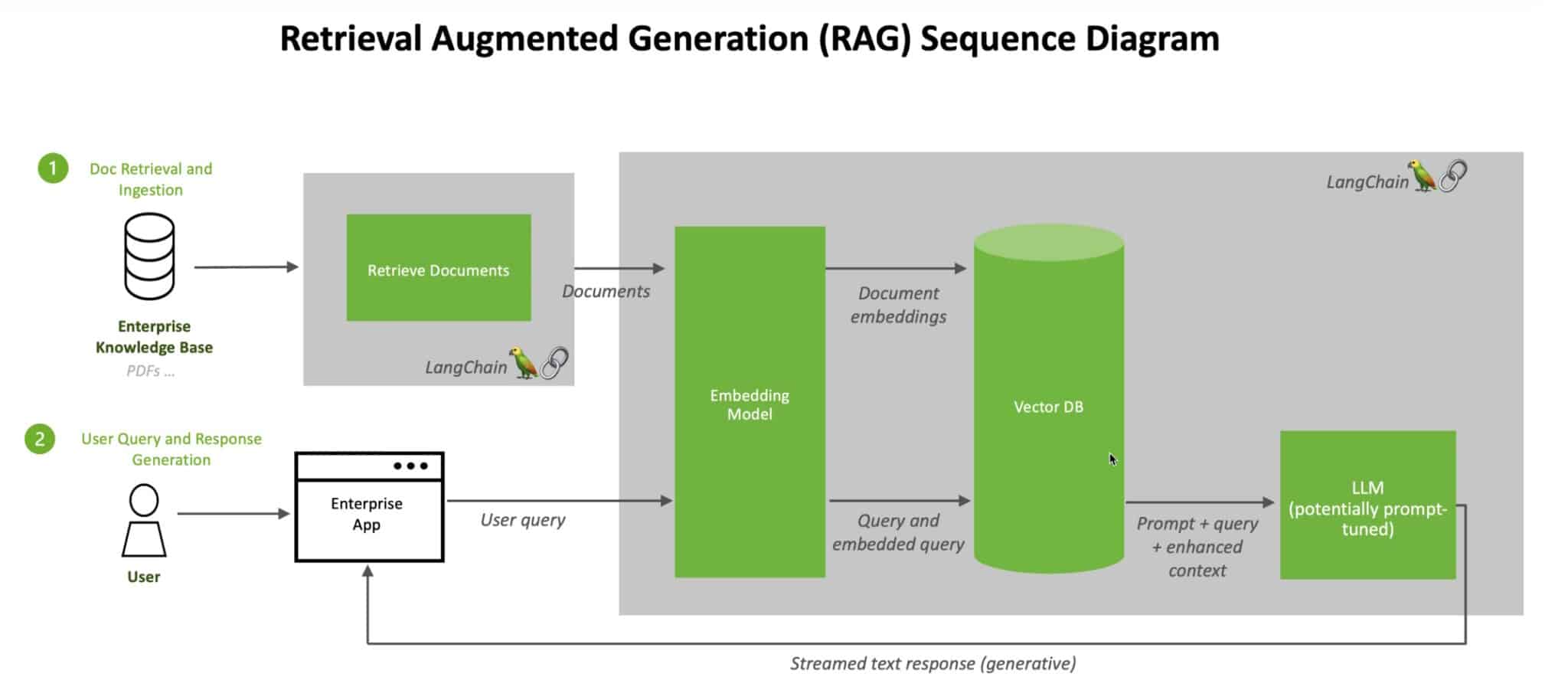 LLM とエンベッディング モデルとベクトル データベースを組み合わせた Retrieval-augmented Generation
LLM とエンベッディング モデルとベクトル データベースを組み合わせた Retrieval-augmented Generation
エンベッディング モデルは、これらの数値を、利用可能なナレッジ ベースの機械可読のインデックス内のベクトルと比較します。一致する、あるいは複数の一致が見つかると、関連するデータを検索し、人間が読める単語に変換して LLM に戻します。
最後に、LLM は、検索された単語とクエリに対する独自の応答を組み合わせて、最終的な回答を作成し、エンベッディング モデルが見つけたソースがあれば引用してユーザーに提示します。
ソースを最新に保つ
バックグラウンドでは、エンベッディング モデルは、新しい知識ベースや更新された知識ベースが利用可能になると、機械可読のインデックス (ベクトル データベースと呼ばれることもある) を継続的に作成、更新します。
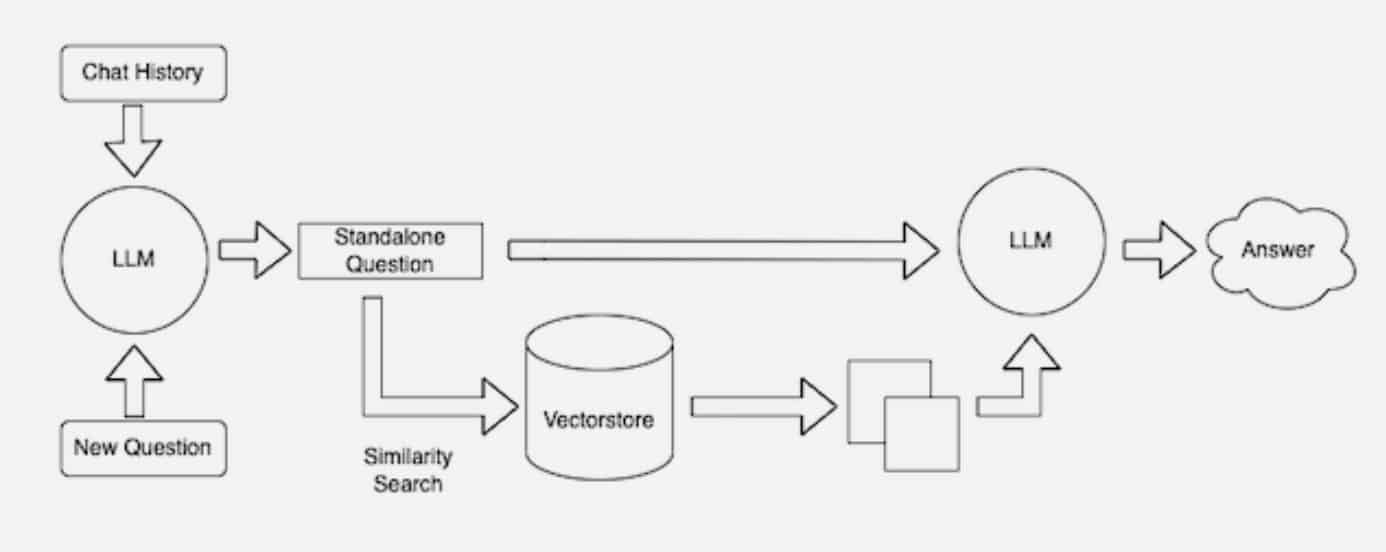 LangChain のダイアグラムは、検索プロセスを使った LLM の別の姿を示しています
LangChain のダイアグラムは、検索プロセスを使った LLM の別の姿を示しています
多くの開発者は、オープンソース ライブラリである LangChain が、LLM、エンベッディング モデル、ナレッジ ベースを連結する際に特に有用であると感じています。NVIDIA は LangChain を Retrieval-Augmented Generation のリファレンス アーキテクチャに使用しています。
LangChain コミュニティは、RAG プロセスについて独自の説明を提供しています。
今後、生成 AI の未来は、あらゆる種類の LLM とナレッジ ベースを創造的に連鎖させ、ユーザーが検証できる権威ある結果を提供する新しい種類のアシスタントを生み出すことにあります。
この NVIDIA LaunchPad ラボで、AI チャットボットによる Retrieval-Augmented Generation を実際に使ってみましょう。