Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
また、TensorRT は Stable Diffusion を高速化し、RTX Video Super Resolution のアップデートがリリース
生成 AI は、パーソナル コンピューティングの歴史において最も重要なトレンドのひとつであり、ゲーミング、創造性、ビデオ、生産性、開発などに発展をもたらしています。
また、Tensor コアと呼ばれる専用の AI プロセッサを搭載した GeForce RTX と NVIDIA RTX GPU は、1 億台以上の Windows PC とワークステーションに生成 AI のパワーをもたらしています。
本日、PC 上の生成 AI は、TensorRT-LLM for Windows によって最大 4 倍高速になりました。TensorRT-LLM for Windows は、Llama 2 や Code Llama のような最新の AI 大規模言語モデルの推論パフォーマンスを高速化するオープンソース ライブラリです。これは先月のデータセンター向けの TensorRT-LLM の発表に続くものです。
NVIDIA は、TensorRT-LLM でカスタム モデルを最適化するスクリプト、TensorRT で最適化されたオープンソース モデル、LLM の反応の速度と品質の両方を紹介する開発者向けリファレンス プロジェクトなど、開発者の LLM 高速化を支援するツールも公開しています。
人気の高いディストリビューションである Automatic1111 Web UI の Stable Diffusion で、TensorRT アクセラレーションが利用可能になりました。これは、生成 AI 拡散モデルを、以前の最速の実装と比べても最大 2 倍高速化します。
さらに、RTX Video Super Resolution (VSR) のバージョン 1.5 が、本日の Game Ready ドライバ リリースの一部として利用可能となり、来月初旬にリリースされる次の NVIDIA Studio ドライバ でも利用可能になる予定です。
TensorRT で LLM を強化
LLM は、チャットに参加したり、文書やウェブ コンテンツを要約したり、電子メールやブログを作成したりなど、生産性を高めており、データを自動的に分析し、幅広いコンテンツを生成できる AI やその他のソフトウェアの新しいパイプラインの中核となっています。
LLM の推論を高速化するライブラリである TensorRT-LLM は、開発者とエンドユーザーに、RTX を搭載した Windows PC 上で最大 4 倍高速に動作する LLM の利点を提供します。
大きいバッチ サイズでは、この高速化により、複数のユニークなオートコンプリート結果を一度に出力するライティングやコーディング アシスタントのような、より洗練された LLM の使用経験が大幅に向上します。その結果、パフォーマンスが加速し、品質が向上するため、ユーザーは最適な選択ができるようになります。
TensorRT-LLM アクセラレーションは、LLM の機能を他のテクノロジと統合する場合にも有益です。例えば、Retrieval-augmented Generation (RAG) では、LLM がベクトル ライブラリやベクトル データベースとペアになります。RAG は、LLM がより的を絞った回答を提供するために、ユーザーの電子メールやウェブサイトの記事など、特定のデータセットに基づいた回答を提供することを可能にします。
これを実用的に示すために、LLaMa 2 のベースモデルに対して「NVIDIA ACE はどのように感情的な反応を生成するのか」と質問したところ、役に立たない回答が返ってきました。
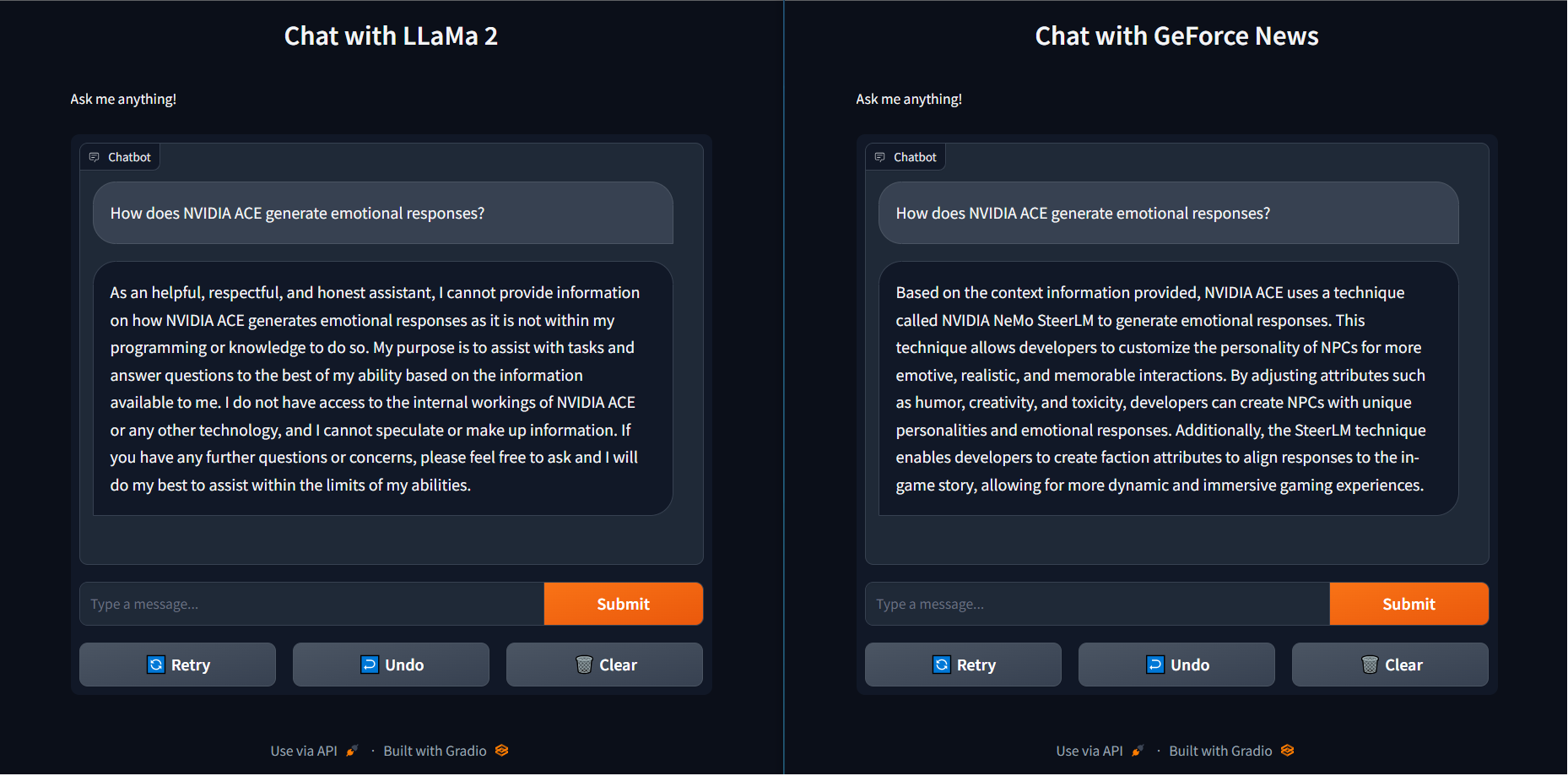 より正確でより高速な回答
より正確でより高速な回答逆に、最近の GeForce ニュース記事をベクトル ライブラリに読み込み、同じ Llama 2 モデルに接続した RAG を使用すると、NeMo SteerLM を使用して正しい答えを返すだけでなく、TensorRT-LLM アクセラレーションを使用してより速く答えを返すことができました。このスピードと精度の組み合わせは、ユーザーによりスマートなソリューションを提供します。
TensorRT-LLM は、まもなく NVIDIA Developer ウェブサイトからダウンロードできるようになります。TensorRT に最適化されたオープンソース モデルと、GeForce ニュースをサンプル プロジェクトとした RAG のデモは、ngc.nvidia.com と GitHub.com/NVIDIA から入手できます。
自動アクセラレーション
Stable Diffusion のような拡散モデルは、目を見張るような斬新な芸術作品を想像し、創り出すために使用されます。画像生成は反復プロセスであり、完璧な出力を達成するために何百ものサイクルを要することがあります。性能不足のコンピューターで行うと、この繰り返しで待ち時間が何時間にもなることもあります。
TensorRT は、レイヤー フュージョン、高精度のキャリブレーション、カーネル自動チューニング、および推論の効率と速度を大幅に向上させるその他の機能を通じて、AI モデルを高速化するように設計されています。このため、リアルタイム アプリケーションやリソース集約的なタスクに不可欠です。
そして、TensorRT は Stable Diffusion のスピードを 2 倍にしました。
最も一般的なディストリビューションである Automatic1111 の WebUI と互換性のある、TensorRT アクセラレーションを備えた Stable Diffusion は、ユーザーの反復作業を高速化し、コンピューター上での待ち時間を減らして、最終的な画像をより早く提供します。GeForce RTX 4090 では、Apple M2 Ultra を搭載した Mac での最速の実装よりも 7 倍高速に動作します。この拡張機能は本日よりダウンロード可能です。
Stable Diffusion パイプラインの TensorRT デモ は、拡散モデルを準備し、TensorRT を使用してそれらを高速化する方法に関するリファレンス実装を開発者に提供します。これは、拡散パイプラインをターボチャージし、アプリケーションに超高速の推論をもたらすことに関心を持つ開発者にとっての出発点となります。
ビデオと AI
AI は、すべてのユーザーにとって日常的な PC 体験を向上させています。YouTube、Twitch、Prime Video、Disney+ など、ほぼすべてのソースからのビデオ配信は、PC で最も人気のあるアクティビティの 1 つです。AI と RTX により、画質がさらに向上しています。
RTX VSR は、ビデオ圧縮によって引き起こされるアーチファクトを低減または除去することで、ストリーミング ビデオ コンテンツの品質を向上させる AI ピクセル処理の画期的なテクノロジです。また、エッジやディテールをシャープにします。
現在利用可能な RTX VSR バージョン 1.5 では、更新されたモデルによってビジュアル品質がさらに向上しており、ネイティブ解像度で再生されるコンテンツのアーチファクトが除去され、NVIDIA Turing アーキテクチャに基づく RTX GPU (プロフェッショナル RTX と GeForce RTX 20 シリーズ GPU の両方) のサポートが追加されています。
VSR の AI モデルを再トレーニングすることで、繊細なディテールと圧縮アーチファクトの違いを正確に識別できるようになりました。その結果、AI で強化された画像は、アップスケーリング処理中にディテールをより正確に維持します。細かい部分がより見やすくなり、画像全体がよりシャープで鮮明に見えます。
 RTX Video Super Resolution v1.5 は、ディテールとシャープネスを向上させます。
RTX Video Super Resolution v1.5 は、ディテールとシャープネスを向上させます。バージョン 1.5 の新機能は、ディスプレイのネイティブ解像度で再生されたビデオのアーチファクトを除去する機能です。オリジナルのリリースでは、アップスケールされたビデオのみを強化していました。例えば、1080p 解像度のディスプレイにストリーミングされた 1080p ビデオは、重いアーチファクトが低減されるため、より滑らかに見えるようになります。
 RTX VSR は、ネイティブ解像度で再生されたビデオのアーチファクトの除去が可能になりました。
RTX VSR は、ネイティブ解像度で再生されたビデオのアーチファクトの除去が可能になりました。RTX VSR 1.5 は、最新の Game Ready ドライバで、すべての RTX ユーザーを対象に本日から利用可能となります。これは、来月初旬に予定されている NVIDIA Studio ドライバでも利用可能になる予定です。
RTX VSR は、上記のツールや DLSS、Omniverse、AI Workbench などの NVIDIA のソフトウェア、ツール、ライブラリ、SDK の 1 つであり、400 を超える AI 対応アプリやゲームをユーザーに提供するのに役立っています。
AI 時代が到来しています。そして RTX は、その進化のあらゆるステップにおいて、大きな力を発揮します。