 Chrome
Chrome Firefox
Firefox Opera
Opera Safari
Safari IE
IE
非常に大規模な AI モデルを現在のコンピューティング プラットフォームでトレーニングするとなると、数か月かかることもあります。しかし、企業にとって、それでは遅すぎます。
AI、ハイ パフォーマンス コンピューティング (HPC)、データ分析は、大規模言語モデルなどの一部のモデルで複雑さが増しており、パラメーター数は数兆にも達しています。
NVIDIA Hopper アーキテクチャは、これらの次世代の AI ワークロードを加速するためにゼロから構築されています。大規模なコンピューティング用の性能と高速メモリを備え、拡大し続けるネットワークとデータセットを処理します。
新しい Hopper アーキテクチャに備わっている Transformer Engine は、AI のパフォーマンスと機能を大幅に高速化し、大規模なモデルを数日または数時間以内にトレーニングできるようになります。
Transformer Engine を使用した AI モデルのトレーニング
Transformer モデルは、BERT や GPT-3 など、今日広く使用されている言語モデルの基幹を成しています。当初は自然言語処理への応用を想定して開発されましたが、その汎用性により、コンピュータ ビジョンや創薬などの分野でますます広く使われるようになっています。
しかし、モデルのサイズは飛躍的に拡大し続け、現在は数兆のパラメーターにまで達しています。それが原因で、大量の計算が必要となり、トレーニングにかかる時間が数か月にもなっています。これでは実用的ではなく、ビジネス ニーズを満たすことができません。
Transformer Engine は、16 ビット浮動小数点の精度と、新しく追加された 8 ビット浮動小数点のデータ形式を高度なソフトウェア アルゴリズムと組み合わせて使用し、AI のパフォーマンスと機能をさらに高速化します。
AI トレーニングでは浮動小数点数を使用します。浮動小数点数とは、3.14 のような小数以下の部分を持つ数字のことです。NVIDIA Ampere アーキテクチャで導入された TensorFloat32 (TF32) 浮動小数点形式は現在、TensorFlow および PyTorch フレームワークでデフォルトの 32 ビット形式として使用されています。
AI による浮動小数点演算はほとんどが、16 ビットの「半精度」 (FP16)、32 ビットの「単精度」 (FP32)、および特殊な演算の場合は 64 ビットの「倍精度」 (FP64) を使用して行われます。Transformer Engine では演算をわずか 8 ビットに減らすことで、大規模なネットワークをさらに高速にトレーニングすることが可能になります。
他にも、ノード間の直接高速相互接続を提供する NVLink Switch Systemといった Hopper アーキテクチャの新機能と組み合わせることで、H100 アクセラレーテッド サーバー クラスターでは、企業が必要とするスピードでトレーニングすることがほぼ不可能だった巨大ネットワークをトレーニングできるようになります。
Transformer Engine についての詳細
Transformer Engine は、ソフトウェアとカスタムの NVIDIA Hopper Tensor コア テクノロジを使用し、AI モデルの一般的な構成要素である Transformer から構築されたモデルのトレーニングを加速するように設計されています。この Tensor コアは、FP8 と FP16 の混合精度演算を採用しており、Transformer の AI 計算を劇的に高速化します。FP8 での Tensor コア演算は、16 ビット演算と比較してスループットが 2 倍になります。
モデルの課題は、精度をインテリジェントに管理して正確性を維持しながら、より小さくより高速な数値形式によりパフォーマンスを向上させることです。Transformer Engine は、FP8 と FP16 の計算を動的に選択して各レイヤーでこれらの精度間のリキャストとスケーリングを自動的に処理する、NVIDIA が調整したカスタム ヒューリスティックでそれを実現します。
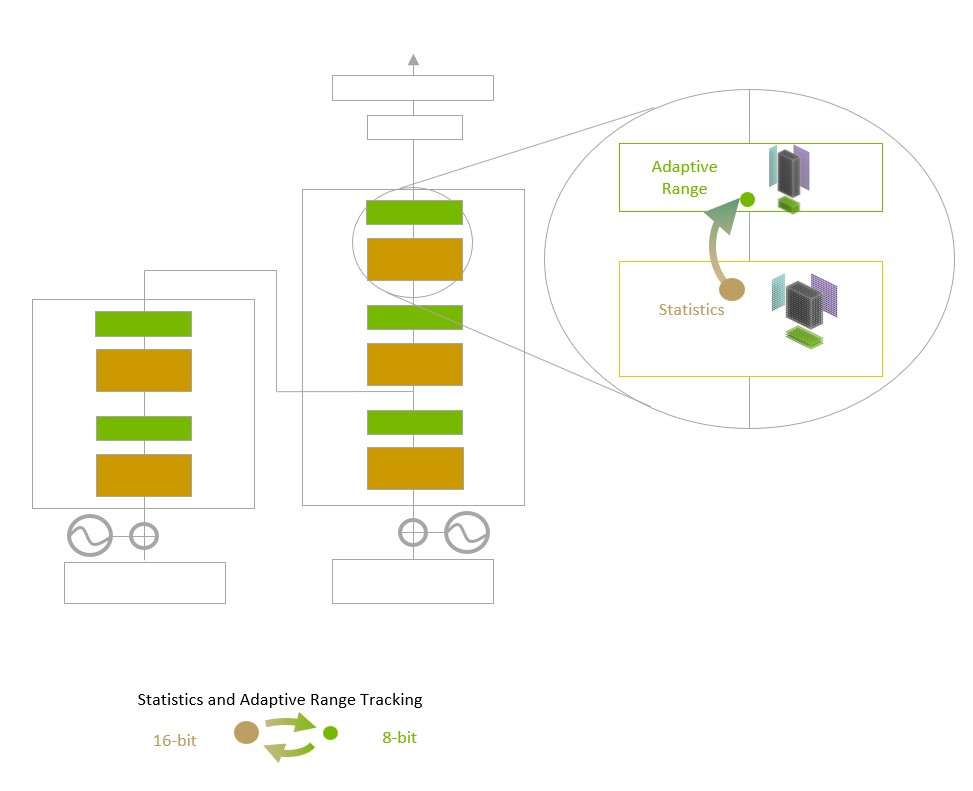 Transformer Engine は、レイヤーごとの統計分析を使用してモデルの各レイヤーにとって最適な精度 (FP16またはFP8) を決定し、モデルの精度を維持しながら最高のパフォーマンスを実現します。
Transformer Engine は、レイヤーごとの統計分析を使用してモデルの各レイヤーにとって最適な精度 (FP16またはFP8) を決定し、モデルの精度を維持しながら最高のパフォーマンスを実現します。また、NVIDIA Hopper アーキテクチャは、TF32、FP64、FP16、および INT8 の精度で1 秒あたりの浮動小数点演算数が前世代と比較して 3 倍になっており、第 4 世代の Tensor コアへと進化しています。Transformer Engine と第 4 世代の NVLink を組み合わせて、Hopper Tensor コアは、HPC や AI のワークロードを桁違いに高速化します。
勢いが加速する Transformer Engine
AI を利用した最先端の研究の多くは、Megatron 530B のような大規模言語モデルを中心としたものです。下のグラフはここ数年のモデル サイズの拡大を示しており、この傾向は今後も続くというのが大方の予想です。多くの研究者は、自然言語理解などへの応用を目指し、すでに数兆を超えるパラメーター モデルに取り組んでおり、AI のコンピューティング能力に対する飽くなき探求心がうかがえます。
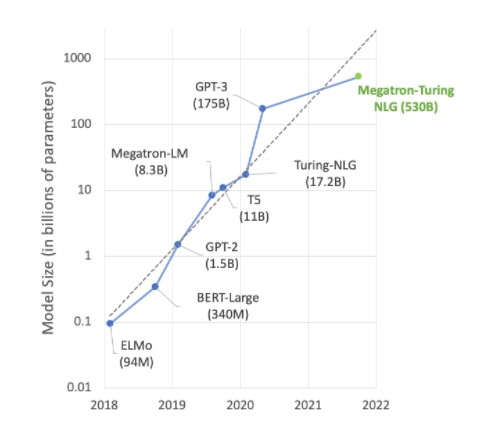 自然言語理解モデルは急激な成長を続けています。出典: Microsoft
自然言語理解モデルは急激な成長を続けています。出典: Microsoftこのように成長を続けるモデルの要件を満たすには、優れた計算能力と大容量の高速メモリが必要です。NVIDIA H100 Tensor コア GPU はその両方を備えており、Transformer Engine によって AI トレーニングを次のレベルに引き上げることができます。
これらのイノベーションが組み合わさることで、スループットが向上し、トレーニングの時間が 7 日からわずか 20 時間に、つまり 9 分の 1 に短縮されます。
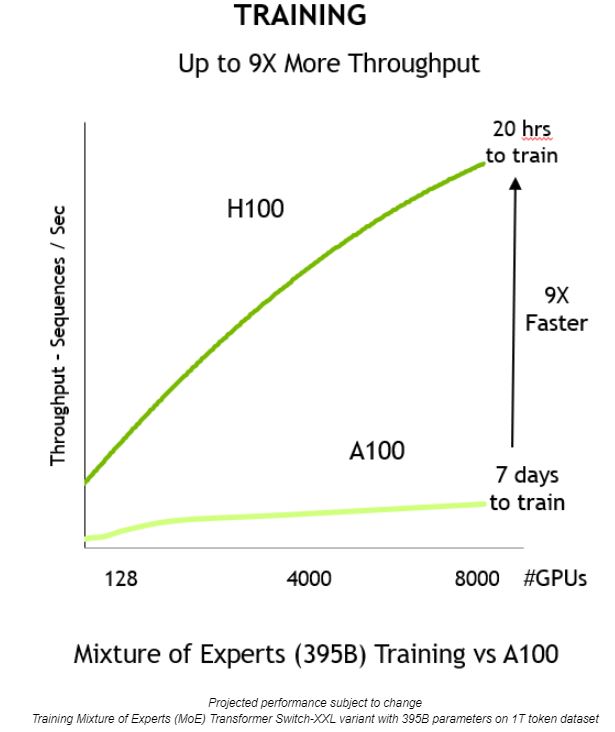 NVIDIA H100 Tensor コア GPU は、前世代と比較して最大 9 倍のトレーニング スループットを実現し、大規模なモデルを適度な時間でトレーニングすることができます。
NVIDIA H100 Tensor コア GPU は、前世代と比較して最大 9 倍のトレーニング スループットを実現し、大規模なモデルを適度な時間でトレーニングすることができます。また、Transformer Engine はデータ形式を変換せずに推論に使用することもできます。これまで、最高の推論パフォーマンスを実現するには、主に INT8 の精度が使用されていました。ただし、その場合は、最適化プロセスの一環として、トレーニングされたネットワークを INT8 に変換する必要があります。これは、NVIDIA TensorRT 推論オプティマイザーによって簡単に実行できます。
FP8 でトレーニングされたモデルを使用することで、開発者はこの変換手順を完全にスキップして、同じ精度を使用して推論演算を実行できます。また、INT8 形式のネットワークと同様に、Transformer Engine を使用した展開の場合、はるかに小さなメモリ フットプリントで実行できます。
Megatron 530B では、応答遅延が 1 秒のときに NVIDIA H100 の推論における GPU あたりのスループットが NVIDIA A100 と比較して最大で 30 倍に向上し、AI の展開に最適なプラットフォームであることがわかります。
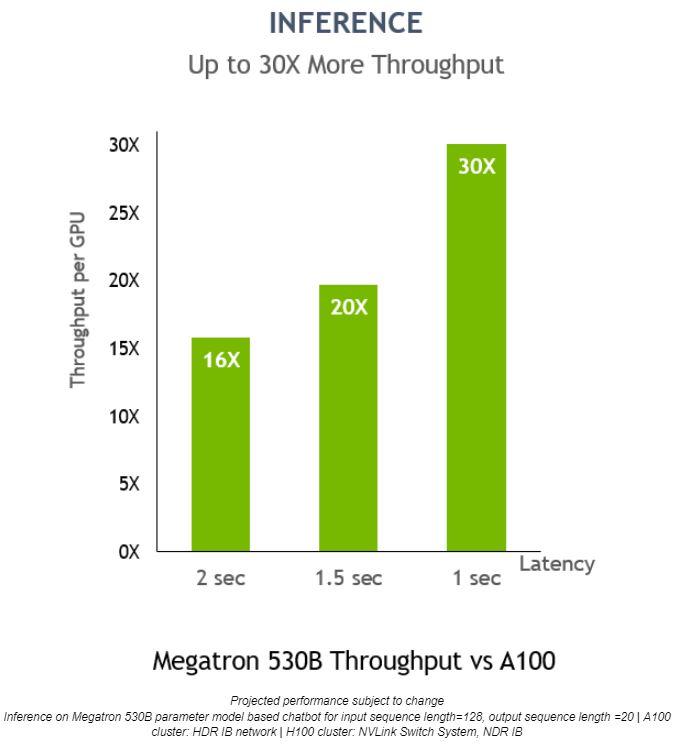 Transformer Engine は推論におけるスループットも最大で 30 倍向上させ、低遅延のアプリケーションを実現します。
Transformer Engine は推論におけるスループットも最大で 30 倍向上させ、低遅延のアプリケーションを実現します。NVIDIA H100 GPU および Hopper アーキテクチャの詳細については、こちらの NVIDIA Technical Blog の記事、または Hopper アーキテクチャについてのホワイトペーパーをご覧ください。







