
ディープラーニングを取り入れた人工知能 (AI) によって、コンピューターによる自然言語での音声認識や音声変換、自律走行といった、かつては実現不可能と思われた課題を解決できるようになりました。数多くの課題を解決するディープラーニングの効果に触発され、指数関数的に複雑化するアルゴリズムが、コンピューティングの高速化に対する飽くなき欲求を生み出しています。NVIDIA は、このようなニーズに対応するため Volta Tensor コア アーキテクチャを設計しました。
NVIDIA とその他多くの企業および研究者が、このニーズを満たすべく、ハードウェアおよびソフトウェアの両面でコンピューティング プラットフォームの開発を進めてきました。たとえば、Google が開発した TPU (テンソル プロセッシング ユニット) アクセラレータは、TPU 上で実行できる限られた数のニューラルネットワークで優れたパフォーマンスを実現しています。
本稿では、AI コミュニティに GPU の劇的なパフォーマンスの向上をもたらす NVIDIA の最新技術をいくつかご紹介します。それらの機能向上により、単一のチップおよび単一のサーバーにおいて ResNet-50 の記録的なパフォーマンスを達成しました。また、fast.ai も、単一のクラウド インスタンスでの記録的なパフォーマンスを最近発表したばかりです。
具体的な成果は以下のとおりです。
- 単一の Tesla V100 GPU で ResNet-50 のトレーニング時に画像 1,075 枚/秒を達成。前世代の Pascal GPU と比べてパフォーマンスが 4 倍。
- 単一の DGX-1 サーバー (Tesla V100 を 8 基搭載) で画像 7,850 枚/秒を達成。同じシステムで 1 年前に達成した 4,200 枚/秒のほぼ 2 倍。
- 単一の AWS P3 クラウド インスタンス (Tesla V100 を 8 基搭載): ResNet-50 のトレーニングを 3 時間未満で完了可能。TPU インスタンスの 3 倍高速。

図 1. Volta Tensor コアが ResNet-50 の記録的速度を達成 (AWS P3.16xlarge インスタンス: Tesla V100 GPU を 8 基搭載)
多様なアルゴリズムにおける NVIDIA GPU の超並列処理性能は、ディープラーニングに最適だといえます。しかし、それだけではありません。当社は、長年培ってきた世界中の AI 研究者との経験と緊密な連携を活かし、ディープラーニングの多くのモデルに対して最適化された新しいアーキテクチャを開発しました。それが NVIDIA Tensor コアです。
NVLink 高速インターコネクトと組み合わせて使用し、さらにすべての最新フレームワークにおいて徹底した最適化を行うことで、最高水準のパフォーマンスを実現しています。また、NVIDIA CUDA のプログラマビリティによって、多種多様な現代のネットワークに対応するパフォーマンスを保証するとともに、新たなフレームワークと将来のディープ ネットワークの発明をもたらすプラットフォームを提供します。
Tesla V100 が単一プロセッサの最速記録を達成
Volta GPU に組み込まれた NVIDIA の Tensor コア GPU アーキテクチャは、NVIDIA ディープラーニング プラットフォームの大幅な進歩を示すものです。この新しいハードウェアによって、ニューラル ネットワークのトレーニングにおける演算処理の大半を占める、行列の乗算と畳み込みの演算を加速できます。
NVIDIA Tensor コア GPU アーキテクチャは、単一機能の ASIC をしのぐパフォーマンスを実現するだけでなく、さまざまなワークロードに合わせてプログラム可能です。たとえば、ディープラーニングのパフォーマンスについては、Google TPU チップが 1 基あたり 45 テラフロップスになるのに対し、Tesla V100 Tensor コア GPU は 1 基あたり 125 テラフロップスを実現します。つまり、「Cloud TPU」内の TPU チップ 4 基で実現されるパフォーマンスが 180 テラフロップスになるのに対し、V100 チップは 4 基で 500 テラフロップスになるということです。
また、NVIDIA の CUDA プラットフォームによって、あらゆるディープラーニング フレームワークで Tensor コア GPU のフルパワーを利用できるようになり、CNN、RNN、GAN、RL をはじめ、毎年数千の亜種が新たに誕生して急速に多様化するニューラル ネットワークを加速できるようになります。
では、Tensor コア アーキテクチャについてもう少し掘り下げ、そのユニークな機能について見てみましょう。図 2 は、低精度の FP16 で保存されたテンソルを処理し、高精度の FP32 で演算を行う Tensor コア を示しています。これにより、必要な精度を保ちながらも、スループットを最大化できます。

図 2. Volta Tensor コア による行列の乗算と累算
最近のソフトウェアの向上により、ResNet-50 のトレーニングにおいて、スタンドアロン テストでは単一の V100 で 1 秒間になんと 1,360 枚の画像を処理できるようになりました。当社では現在、このトレーニング ソフトウェアを後述の一般的なフレームワークに統合する取り組みを進めています。
最高のパフォーマンスを得るには、Tensor コア によって演算されるテンソルが、メモリ内でチャネルインターリーブ データ レイアウト (「数、高さ、幅、チャネル」の、いわゆる NHWC (Number-Height-Width-Channel) の形) になる必要があります。一方、トレーニング フレームワークで予期されるメモリ内のレイアウトは、チャネルメジャー データ レイアウト (「数、チャネル、幅、高さ」の、いわゆる NCHW (Number-Channel-Width-Height) の形) です。そのため、cuDNN ライブラリでは、図 3 に示すように、NCHW と NHWC の間でテンソルの転置演算が実行されます。前述のとおり、畳み込み自体は非常に高速化されたため、ランタイムにおいてこれらの転置が占める割合が目立つようになりました。
そこで当社は、代わりに RN-50 モデル グラフの各テンソルを直接 NHWC 形式で表すことで、これらの転置をなくします。これは、MXNet フレームワークでサポートされている機能です。さらに、その他すべての畳み込み以外の層については、MXNet と cuDNN に最適化された NHWC の実装を加えることで、トレーニング時のテンソルの転置が不要になるようにしました。

図 3. NHWC 形式の最適化によってテンソルの転置をなくした
並列処理による理論上の高速化を予測する「アムダールの法則」の結果として、またもや最適化のチャンスが生まれました。Tensor コア によって行列の乗算層と畳み込み層が大幅に高速化されるため、ランタイムにおいてトレーニング ワークロードの他の層が占める割合が目立つようになったのです。そこで、それらの新たなパフォーマンス上のボトルネックを特定し、最適化しました。
畳み込み以外の層の多くでは、図 4 のように、DRAM との間のデータ移動によってパフォーマンスが制限されます。そこで、連続した層を結合してオンチップ メモリを利用することで、DRAM のトラフィックを回避します。たとえば、MXNet にグラフ最適化パスを作成して、連続した ADD 層と ReLu 層を見つけ、可能であればそれらの層を結合した実装で置き換えました。このような最適化は、NNVM (ニューラル ネットワーク仮想マシン) を使って MXNet に簡単に実装できます。
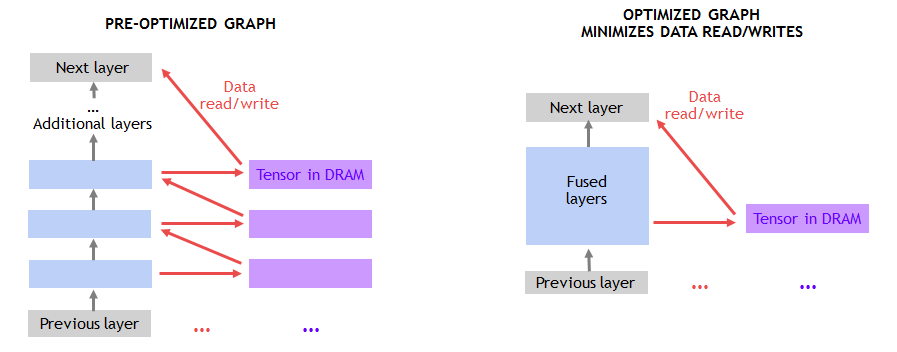
図 4. 層を結合してデータの読み取り/書き込みをなくす
最後に、よく見られる種類の畳み込み専用のカーネルを新たに作成することで、引き続き個々の畳み込みの最適化を行いました。
当社は現在、TensorFlow、PyTorch、MXNet をはじめとする多様なディープラーニング フレームワークに、これらの最適化の多くを提供しています。MXNet への当社の貢献によって、標準の 90 エポックのトレーニング スケジュールを使用しながらも、単精度でのトレーニングと同じ Top-1 に分類される精度 (75% 以上) を実現し、単一の Tesla V100 で 1 秒あたり 1,075 枚の画像を達成しました。スタンドアロン テストでは 1 秒あたり 1,360 枚の画像を処理できることから、さらなる向上を実現する大きな余地があるといえます。これらのパフォーマンスの向上は、NGC の NVIDIA が最適化したディープラーニング フレームワーク コンテナーで利用可能になります。
単一のノードで最速を記録
複数の GPU を単一のノードとして運用することで大幅なスループットの向上を実現できますが、単一のサーバー ノードで複数の GPU を連携させるために拡張するには、GPU 間での高帯域幅/低レイテンシの通信パスが必要になります。当社の NVLink 高速インターコネクト ファブリックなら、1 台のサーバーで 8 基の GPU までパフォーマンスを拡張できます。このような大幅に加速されたサーバーは、1 ペタフロップスものディープラーニング パフォーマンスを実現し、クラウドとオンプレミスの展開で広く利用可能です。
ただし、GPU を 8 基まで拡張するとトレーニングのパフォーマンスが大幅に向上するため、フレームワーク内のホスト CPU によって行われる他の処理がパフォーマンスを制限する要因となってしまいます。つまり、フレームワーク内で GPU にデータを送信するパイプラインのパフォーマンスを大きく引き上げる必要がありました。
このデータ パイプラインでは、エンコードされた JPEG のサンプルをディスクから読み取り、デコードして、画像のサイズ変更や拡張を行います (図 5 参照)。このような拡張処理によってニューラル ネットワークの学習能力が高まるため、トレーニング済みモデルの精度予測も向上します。8 基の GPU でフレームワークのトレーニングの部分を処理すると、これらの重要な処理によってパフォーマンス全体が制約をうけます。

図 5: 画像のデコードと拡張のためのデータ パイプライン
当社はこの問題への対応策として、CPU から GPU へ処理をオフロードするための、フレームワークに依存しないライブラリである DALI (データ拡張ライブラリ) を開発しました。図 6 に示すように、DALI は、JPEG のデコードの一部と、サイズ変更やその他すべての拡張処理を GPU へ移動させます。GPU ではこれらの処理が CPU よりもはるかに高速化されるため、CPU をオフロードできるわけです。DALI によって、CUDA の全体的な並列パフォーマンスの能力が強調されます。CPU のボトルネックを解消することで、単一ノードで 1 秒あたり 7,850 枚の画像処理を維持できるようになりました。
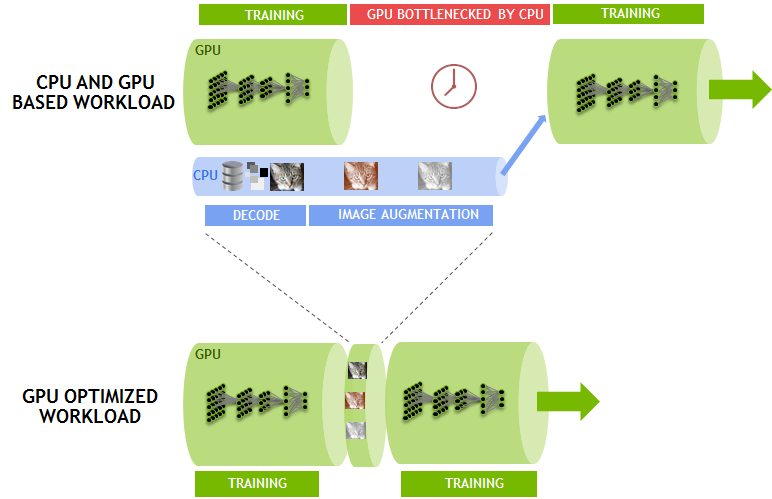
図 6: DALI を利用した GPU によるワークロードの最適化
NVIDIA は、DALI をすべての主要な AI フレームワークに組み込む支援を進めています。このソリューションによって、最近発表された 16 基の Tesla V100 GPU を搭載する NVIDIA DGX-2 などのシステムでは、8 基の GPU を超えてパフォーマンスを拡張することが可能になります。
単一のクラウド インスタンスで最速を記録
単一の GPU および単一のノードの実行では、75% を超える精度を達成するため ResNet-50 のトレーニングに 90 エポックのデファクト スタンダードを使用しましたが、アルゴリズムのイノベーションやハイパーパラメーターのチューニングによってより少ないエポックで精度が得られるようにすれば、トレーニング時間をさらに短縮できます。AI 研究者は、GPU によってプログラマビリティを得ることができます。また、GPU ではすべてのディープラーニング フレームワークがサポートされているため、新しいアルゴリズム アプローチを検討することや、既存のアプローチを活かすこともできます。
最近、fast.ai チームが、PyTorch を使用して 90 エポックよりはるかに少ないエポック数で高い精度を達成したという、すばらしい結果を発表しました。fast.ai のジェレミー ハワード (Jeremy Howard) 氏率いる研究者チームは、重要なアルゴリズム イノベーションとチューニング技術を取り入れ、Tesla V100 GPU を 8 基搭載した単一の AWS P3 インスタンスで、ImageNet に対する ResNet-50 のトレーニングをわずか 3 時間で完了できるようにしました。つまり、ResNet-50 のトレーニングに 9 時間近くかかる TPU ベースのクラウド インスタンスより 3 倍高速化されたことになります。
当社はさらに、本稿で説明するスループットの向上手法を fast.ai などの他のアプローチに適用できるようにして、統合の加速をさらに後押しする予定です。
指数関数的なパフォーマンスの向上を実現
アレックス クリジェフスキー (Alex Krizhevsky) 氏が 2 基の GTX 580 GPU を使って最初の ImageNet コンテストで優勝して以来、われわれはディープラーニングの高速化において驚くべき進歩を遂げました。クリジェフスキー氏は、自身の優れたニューラル ネットワーク「AlexNet」のトレーニングを 6 日で行いましたが、これはその時点で他のすべての画像認識アプローチをしのぐもので、ディープラーニング革命を巻き起こしました。それが今では、発表したばかりの DGX-2 を使えば、AlexNet のトレーニングをわずか 18 分で完了できるまでになりました。図 7 は、わずか 5 年間でパフォーマンスが 500 倍になったことを示しています。
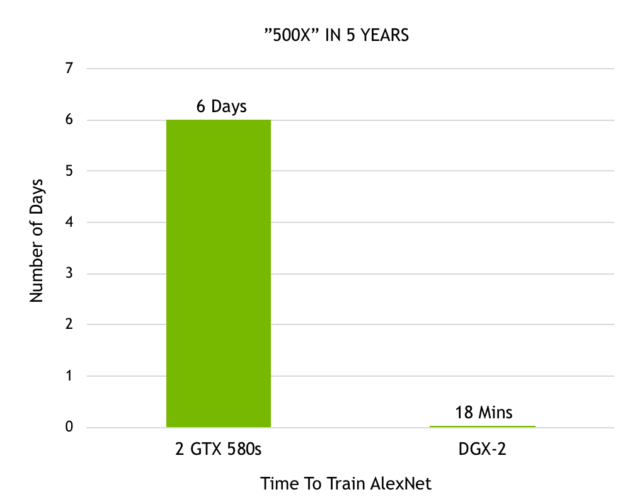
図 7. ImageNet データセットに対する AlexNet のトレーニングにかかる時間
また、Facebook AI Research (FAIR) が、言語翻訳モデル「Fairseq」を公開しました。最近発表された NVIDIA DGX-2 と、当社のソフトウェア スタックにおける数々の向上によって、1 年足らずで Fairseq のパフォーマンスを 10 倍に向上させました (図 8 参照)。
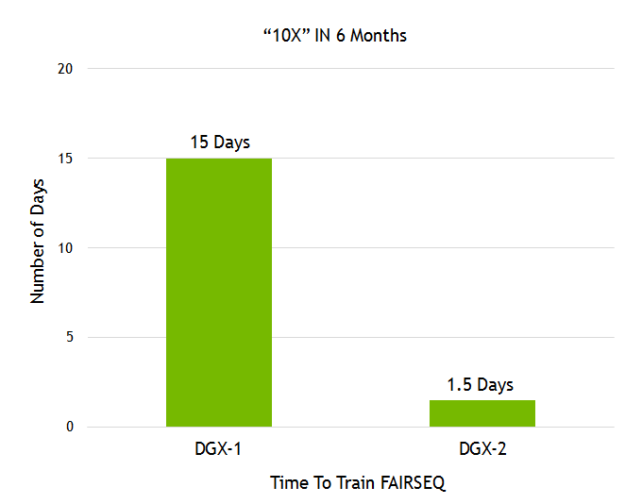
図 8. Facebook の Fairseq のトレーニングにかかる時間
画像認識や言語翻訳は、研究者が AI を駆使して解決する無数のユースケースのほんの一例にすぎません。Github には、GPU アクセラレーテッド フレームワークを利用する 60,000 件を超えるニューラル ネットワーク プロジェクトが投稿されています。NVIDIA GPU のブログラマビリティによって、AI コミュニティが開発しているあらゆる種類のニューラル ネットワークを加速させることができます。AI 研究者は、向上を速いペースで行うことで、AI を利用した大きな課題に対応する、より一層複雑なニューラル ネットワークを構想できるようになるでしょう。
これらの一貫した成果は、GPU アクセラレーテッド コンピューティングに対するスタック全体での最適化アプローチによって得られたものです。最先端のディープラーニング アクセラレータから、複雑なシステム (HBM、COWOS、SXM、NVSwitch、DGX) の構築まで、また、先進の数値ライブラリやディープ ソフトウェア スタック (cuDNN、NCCL、NGC) から、すべてのディープラーニング フレームワークの高速化まで、NVIDIA の AI に対する取り組みは、無類の柔軟性を AI 開発者にもたらします。
当社は今後もスタック全体の最適化を進めるとともに、指数関数的なパフォーマンスの向上に取り組み、ディープラーニング イノベーションの推進に役立つツールを AI コミュニティに提供してまいります。
まとめ
AI はあらゆる業界を変革し続けており、無数のユースケースを実現しています。ますます多様化するモデル アーキテクチャに対応するには、理想のAI コンピューティング プラットフォームが、優れたパフォーマンス、大規模なモデルやモデル サイズの拡大をサポートする拡張性、そして、プログラマビリティを備えていなければなりません。
NVIDIA の Volta Tensor コア GPU は AI 向けの世界最速プロセッサであり、1 つのチップで 125 テラフロップスのディープラーニング パフォーマンスを発揮します。また、まもなく、16 基の Tesla V100 を単一のサーバー ノードに組み込み、2 ペタフロップスのパフォーマンスを提供する世界最速のコンピューティング サーバーを実現する予定です。
パフォーマンスだけでなく、あらゆるクラウドで、あらゆるサーバー メーカーから AI コミュニティ全体まで利用可能な GPU のプログラマビリティと幅広いアクセス性が、次世代の AI を可能にしています。
どのようなフレームワークを選択するかにかかわらず、NVIDIA は、Caffe2、Chainer、Cognitive Toolkit、Kaldi、Keras、Matlab、MXnet、PaddlePaddle、PyTorch、TensorFlow といったすべてのフレームワークを高速化します。また、NVIDIA の GPU は、CNN、RNN、GAN、RL やハイブリッド ネットワーク アーキテクチャのほか、毎年新たに誕生する数千の亜種にも対応します。AI コミュニティはこれまでもすばらしい活用例を生み出してきました。NVIDIA は、今後もぜひ AI の新たな用途を後押ししていきたいと考えています。