
コンシューマー向けコンピューティングのパラダイムは、PC やスマートフォン、タブレットのようなパーソナル デバイスという概念を中心に展開してきました。そして今、生成 AI、特に OpenClaw が、エージェント コンピュータという新たなカテゴリを生み出しました。NVIDIA DGX Spark デスクトップ AI スーパーコンピューターや NVIDIA RTX PC などのデバイスは、パーソナル エージェントをプライベートかつ無料で実行するのに最適です。
NVIDIA GTC では、以下のようなエージェント型 AI に関する多数の発表が行われています。
- ローカル エージェント向けの新しいオープン モデル:NVIDIA Nemotron 3 Nano 4B、Nemotron 3 Super 120B、および Qwen 3.5 と Mistral Small 4 の最適化。
- OpenClaw 向けのオープン ソース スタックである NVIDIA NemoClaw。セキュリティを強化し、ローカル モデルをサポートすることで、NVIDIA デバイス上での OpenClaw 体験を最適化。
- Unsloth Studio によりファインチューニングが容易になり、エージェント型ワークフロー向けのオープン モデルの精度がさらに向上。
新しいオープン モデルがローカル エージェントにクラウド並みの品質をもたらす
コンテキスト ウィンドウがますます大きくなっている次世代のローカル モデルは、PC 上でエージェントを実行するためのインテリジェンスを提供します。より豊富なユーザー コンテキストと強力なローカル ツールが組み合わさり、こうした進歩により、AI PC でできることがさらに広がっており、特に 1,200 億を超えるパラメータを持つモデルをサポートする 128GB の統合メモリを搭載した DGX Spark でその力が大きく発揮されます。
最近リリースされた Nemotron 3 Super は、120 億パラメータがアクティブとなる 1,200 億パラメータのオープン モデルで、複雑なエージェント型 AI システムを実行できるように設計されています。Nemotron 3 Super は、DGX Spark や NVIDIA RTX PRO ワークステーション上でエージェントを実行するのに最適です。OpenClaw で大規模言語モデルがどの程度の性能を発揮するかを評価する新しいベンチマークである PinchBench において、Nemotron 3 Super は 85.6% のスコアを獲得し、同クラスで最上位のオープン モデルとなりました。
Mistral Small 4 は、60 億のアクティブ パラメータを持ち、全レイヤーを含めると 80 億のアクティブ パラメータとなる 1,190 億パラメータのオープン モデルであり、Mistral のフラッグシップ モデルの機能を統合しています。ユーザーは、一般的なチャット、コーディング、エージェント型タスクに最適化された、非常に効率的なモデルを利用できるようになりました。
両モデルは DGX Spark および RTX PRO GPU 上でローカルに動作します。
より小型のモデルを探している GeForce RTX ユーザー向けに、Nemotron 3 Nano 4B が NVIDIA Nemotron 3 ファミリーのオープン モデルに加わった最新モデルとして登場しました。Nemotron 3 Nano 4B は、RTX AI PC 上でエージェントやアシスタントをローカルに構築するための、コンパクトで有能な出発点となります。このモデルは、リソースが限られたハードウェア上で動作するゲームやアプリ向けに、アクションを実行する対話型ペルソナを構築するのに最適です。NVIDIA GPU を搭載したあらゆるシステムで利用でき、最先端の指示追従性能と優れたツール利用能力を、最小限の VRAM 使用量で実現します。
さらに、NVIDIA は Alibaba の Qwen 3.5 モデルの最適化を発表しました。これらのモデルは、27B、9B、4B の各サイズで卓越した精度を示しており、NVIDIA GPU 上でローカル エージェントを実行するのに適しています。新しいモデルは、ビジョン、マルチトークン予測、および 262,000 トークンという大規模なコンテキスト ウィンドウをネイティブにサポートしています。270 億パラメータの高密度モデルは、RTX 5090 GPU と組み合わせると特に優れた性能を発揮します。
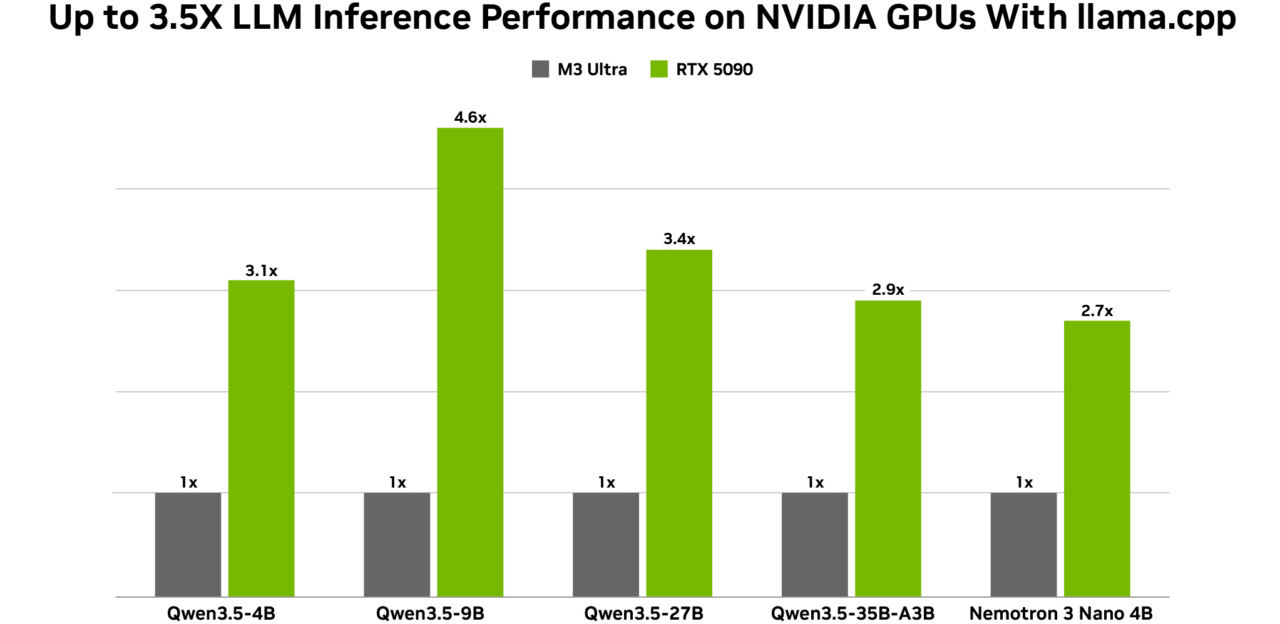
ユーザーは、RTX GPU や DGX Spark による高速な推論に対応した Ollama、LM Studio、llama.cpp を通じて、これらのモデルを今すぐ試すことができます。NVIDIA オープン モデルの最新情報については、こちらをご覧ください。
最新の RTX 最適化モデルで、クリエイティブ AI がさらに高速化
今月上旬にリリースされた Lightricks の最先端オーディオビデオ モデルである LTX 2.3 が、NVFP4 および FP8 の蒸留モデルに対応し、パフォーマンスが 2.1 倍に向上しました。Lightricks の LTX 2.3 モデルの詳細はこちらをご覧ください。
さらに、Black Forest Labs の FLUX.2 Klein 9B もアップデートされ、画像編集処理速度が最大 2 倍に向上しました。NVIDIA は Black Forest Labs と連携し、RTX GPU 上で最速のパフォーマンスと最適なメモリ消費を実現するよう最適化された FP8 バージョンをリリースしました。
NVIDIA NemoClaw — OpenClaw 向けの NVIDIA 最適化
AI 開発者や愛好家は、DGX Spark スーパーコンピューターを購入したり、専用の RTX PC を構築したりして、個人のファイル、アプリ、ワークフローからコンテキストを引き出し、日常的なタスクを自動化できる、OpenClaw のような自律型 AI エージェントを実行しています。しかし、OpenClaw などのエージェント型システムが普及するにつれ、トークン コストやセキュリティ、プライバシーに関する懸念も高まっています。
こうした懸念に対処するため、NVIDIA は OpenClaw 向けのオープン ソース スタックであり NVIDIA デバイス上で OpenClaw の最適化を実現する NemoClaw を発表しました。NemoClaw で最初に利用できる機能は、NVIDIA Nemotron のオープン モデルと NVIDIA OpenShell ランタイムです。Nemotron ローカル モデルを使用すると、ユーザーは推論をローカルで実行できるため、プライバシーが向上し、トークン コストも発生しません。OpenShell は、より安全にクローを実行するために設計されたランタイムです。
NemoClaw の詳細はこちらをご覧ください。ジェンスン フアン (Jensen Huang) による GTC 基調講演をご視聴ください。
Unsloth Studio でファインチューニングが簡単に
オープン モデルが飛躍的に進化する中、精度をさらに向上させる方法の 1 つがファインチューニングです。ファインチューニングとは、ユーザーが自身のデータやユース ケースに合わせてモデルをカスタマイズできる手法です。通常、この手法には高度な技術知識やコーディング知識のほか、膨大な設定作業が必要となります。モデルのファインチューニングとアライメントのための主要なオープン ソース ライブラリである Unsloth は本日、AI 愛好家や開発者向けにファインチューニング プロセスを簡素化する、使いやすい Web ベースのユーザー インターフェイスである Unsloth Studio をリリースしました。
Unsloth Studio は 500 以上の AI モデルをサポートしています。シンプルなユーザー インターフェイスで、トレーニングとファインチューニングのプロセスが簡単になります。ユーザーはデータセットをドロップインし、グラフベースのキャンバスをタップして追加の高品質な合成データを生成し、ファインチューニング ジョブを開始するだけです。量子化低ランク適応、低ランク適応、およびフル ファインチューニングに対応しています。モデルのファインチューニングが進むにつれて、ユーザーはジョブの進捗状況を監視し、可視化できます。最後に、モデルを任意のフレームワークにエクスポートし、同じ Web アプリ内でそのままチャットすることも可能です。
Unsloth Studio の新しいインターフェイスは Unsloth ライブラリを基盤としており、このライブラリはカスタムの専用 GPU カーネルを使用することで、最大 2 倍高速なトレーニングと最大 70% の VRAM 削減を実現します。これにより、新しいユーザーでも NVIDIA RTX GPU と DGX Spark を最初から最大限に活用できます。
Nemotron 3 Nano 4B や Qwen 3.5 などの新しいモデルにも対応した Unsloth Studio を今すぐお試しください。その他、NVIDIA GeForce RTX GPU を使用したモデルのファインチューニングに関する詳細は、RTX AI Garage の他の記事をご覧ください。
#GTC 2026 の要チェック情報
✨ComfyUI での RTX Video を特集した RTX AI 動画生成ガイド: 今年初めの CES で発表された新しい RTX AI ビデオ生成ガイドでは、クリエイターや愛好家向けに、テキストから画像のガイド付きワークフローを使用して AI 生成ビデオのキーフレームを作成し、その後、ローカル GPU で動作する RTX Video テクノロジで 4K にアップスケールする方法を解説しています。ガイドを使って始めてみましょう。作品は #AIonRTX を付けて SNS で共有してください。
💿NVIDIA AI for Media は、高性能で使いやすいソフトウェア開発キット群で、強化された音声 (Linux または Windows 対応)、ビデオ、拡張現実機能といった NVIDIA Broadcast クラスの AI エフェクトを、ライブ メディア、ビデオ会議、およびポスプロのワークフローにもたらします。最新アップデートでは、より正確なリップシンク、複数話者検出、RTX Video Super Resolution 機能による RTX PRO および GeForce RTX 40/50 シリーズ GPU でのより高速な 4K アップスケーリング、さらに NVIDIA Studio Voice 機能におけるバックグラウンド ノイズ除去の向上や低レイテンシ化が追加されています。
💻NVIDIA DLSS 5 は今秋登場予定で、ピクセルにフォトリアルなライティングとマテリアルを融合させることで、レンダリングと現実のギャップを埋め、ゲームのビジュアル品質を AI によって大きく前進させます。
🤖Maxon が Redshift 2026.4 をリリースし、DLSS を活用した新しいリアルタイム ビジュアライゼーション ワークフローを導入しました。これにより、設計者はプロジェクト内をリアルタイムに近い速度と品質で歩いて確認できるようになります。「NVIDIA の DLSS テクノロジは不可欠な要素であり、リアルタイムに近い速さで高品質なビジュアルを提供することを可能にします」と、Maxon の最高技術責任者兼 AI 責任者である Philip Losch 氏は述べています。
🪟Reincubate Camo は、Camo Streamlight アプリの AI Autotune 機能向けに NVIDIA TensorRT RTX EP 上の Windows ML を追加し、RTX GPU 上のパフォーマンスを大幅に向上させました。
Facebook、Instagram、TikTok、X で NVIDIA AI PC をフォローしましょう。また、RTX AI PC ニュースレターにご登録いただくと、最新情報を入手できます。
LinkedIn と X で NVIDIA Workstation をフォローしてください。
ソフトウェア製品情報については、お知らせをご覧ください。