
最新のワークフローは、PC 上での生成 AI やエージェント型 AI が持つ無限の可能性を示しています。
その例として、製品サポートの質問に対応するようにチャットボットをチューニングすることや、スケジュール管理のためのパーソナル アシスタントを構築することなどが挙げられます。しかし、小規模言語モデルにおいて、特殊なエージェント タスクに対し一貫して精度の高い応答をさせることには、課題が残っています。
そこでファインチューニングが求められます。
Unsloth は、LLM のファインチューニング用として世界で最も広く使用されているオープンソース フレームワークの一つで、モデルをカスタマイズする手軽な方法を提供します。GeForce RTX デスクトップやノート PC から、RTX PRO ワークステーション、世界最小の AI スーパーコンピューターである DGX Spark まで、Unsloth は、NVIDIA GPU での効率的かつ低メモリのトレーニングのために最適化されています。
オープンモデル、データ、ライブラリで構成される、今回発表された NVIDIA Nemotron 3 ファミリーもまた、ファインチューニングに着手する際の優れた起点となります。Nemotron 3 は、エージェント型 AI のファインチューニング向けに、最適かつ最も効率的なオープン モデル ファミリーを導入します。
AI に新しいトリックを教える
ファインチューニングは、AI モデルに集中トレーニングを行うようなものです。特定のトピックやワークフローに結びついた例を与えることで、モデルは新しいパターンを学習し、目の前のタスクに適応することで、精度を向上させます。
どのファインチューニング手法を選択するかは、開発者がオリジナルのモデルをどれだけ調整したいかによって決まります。開発者はその目標に基づいて、次の 3 つの主なファインチューニング手法から選択できます。
パラメータ効率の高いファインチューニング (LoRA や QLoRA など):
- 仕組み: モデルのごく一部のみを更新し、トレーニングを高速かつ低コストで実施します。これは、大幅な変更を加えずに、モデルを強化するスマートかつ効率的な方法です。
- 対象となるユース ケース: これまでフルファインチューニングが適用されていた、ほぼすべてのシナリオで役立ちます。ドメイン知識の追加、コーディング精度の向上、法律業務または科学的なタスク向けのモデル適用、リーズニングの洗練、トーンと振る舞いの調整などが含まれます。
- 要件: 小規模から中規模のデータセット (100 ~ 1,000 のプロンプト サンプルのペア)
フルファインチューニング:
- 仕組み: モデルのパラメータをすべて更新します。特定のフォーマットやスタイルに従うようモデルに教えるのに便利です。
- 対象となるユース ケース: 特定のトピックに関する支援を提供しなければならない AI エージェントやチャットボットの構築などの高度なユース ケース。一定のガードレールの範囲内で行動し、特定のスタイルで回答します。
- 要件: 大規模なデータセット (1,000 組以上のプロンプト サンプルのペア)
強化学習
- 仕組み: フィードバックまたは選好シグナルを使用してモデルの動作を調整します。モデルは環境との相互作用を通じて学習し、そのフィードバックを活用し、時間の経過とともに自らを改善していきます。これはトレーニングと推論を織り込んだ複雑で高度な手法です。また、パラメータ効率の良いファインチューニングやフルファインチューニング手法と組み合わせても使用できます。詳細については、Unsloth の強化学習ガイドをご覧ください。
- 対象となるユース ケース: 法律や医学などの特定のドメインにおけるモデルの精度の向上、またはユーザーに代わってアクションをオーケストレートする自律型エージェントの構築。
- 要件: アクション モデル、報酬モデル、そしてモデルが学習するための環境を含むプロセス
また、各手法で必要となる VRAM も考慮する必要があります。以下の表では、Unsloth で各タイプのファインチューニング手法を実行するための要件の概要を示しています。
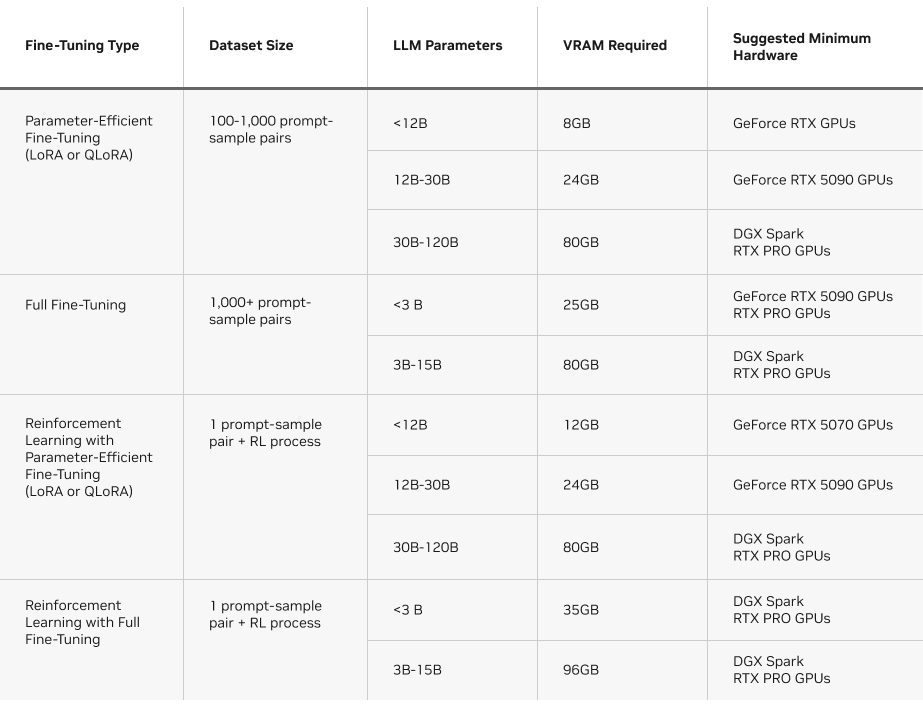
Unsloth: NVIDIA GPU でのファインチューニングへの最短ルート
LLM のファインチューニングは、トレーニングの各ステップでモデルの重みを更新するために、数十億回もの行列乗算を伴う、メモリと計算負荷の高いワークロードです。この種の負荷の高い並列ワークロードでは、プロセスを迅速かつ効率的に完了させるには、NVIDIA GPU のパワーが必要です。
Unsloth は、こうしたワークロードでその真価を発揮し、複雑な数学演算を効率的なカスタム GPU カーネルに変換し、AI トレーニングを高速化します。
Unsloth は、NVIDIA GPU 上で Hugging Face Transformers ライブラリのパフォーマンスを 2.5 倍に向上させました。これらの GPU 固有の最適化と、Unsloth の使いやすさが組み合わさることで、AI 愛好家や開発者といった幅広いコミュニティがファインチューニングを利用できるようになります。
このフレームワークは、GeForce RTX ノート PC から RTX PRO ワークステーション、DGX Spark まで、NVIDIA ハードウェアに合わせて構築および最適化されており、VRAM の消費を削減しながら、ピーク パフォーマンスを提供します。
Unsloth は、さまざまな LLM 構成、ハイパーパラメーター、オプションの導入方法や管理方法に関する役立つガイドを、サンプルノートブックやステップバイステップのワークフローとともに提供しています。
Unsloth ガイドのいくつかをご覧ください。
- NVIDIA RTX 50 シリーズ GPU と Unsloth を活用した LLM のファインチューニング
- NVIDIA DGX Spark と Unsloth を活用した LLM のファインチューニング
NVIDIA DGX Spark に Unsloth をインストールする方法をご覧ください。NVIDIA 技術ブログにて、NVIDIA Blackwell プラットフォームでのファインチューニングと強化学習を深く掘り下げて解説しています。
提供開始: オープン モデルの NVIDIA Nemotron 3 ファミリー
Nano、Super、Ultra の 3 つのサイズ展開による Nemotron 3 ファミリーは、新しいハイブリッド潜在 Mixture-of-Experts (MoE) アーキテクチャを基盤に構築されています。エージェント型 AI アプリケーションの構築に最適な、最先端の精度を誇る効率的なオープン モデル ファミリーを導入します。
現在利用可能な Nemotron 3 Nano 30B-A3B は、このラインアップで最も計算効率の高いモデルです。ソフトウェアのデバッグ、コンテンツの要約、AI アシスタントのワークフロー、低い推論コストでの情報検索などのタスクに最適化されています。ハイブリッド MoE 設計で以下の特長が実現します。
- 推論トークンを最大 60% 削減し、推論コストを大幅に削減します。
- 100 万トークンで構成されたコンテキスト ウィンドウにより、長期間の複数ステップのタスクでも、モデルはより多くの情報を保持できます。
Nemotron 3 Super はマルチエージェント アプリケーション向けの高精度リーズニング モデルです。Nemotron 3 Ultra は複雑な AI アプリケーション向けです。両モデルとも 2026 年前半にリリースされる予定です。
NVIDIA は先日、トレーニング データセットと最先端の強化学習ライブラリのオープン コレクションもリリースしました。Unsloth を活用して、Nemotron 3 Nano のファインチューニングが可能です。
Nemotron 3 Nano は、Hugging Face よりダウンロードできます。または、Llama.cpp や LM Studio を使って、試すこともできます。
DGX Spark: コンパクトな AI パワーハウス
DGX Spark は、コンパクトなデスクトップ スーパーコンピューターで、ローカルでのファインチューニングを可能にし、驚異的な AI パフォーマンスを提供します。開発者は、一般的な PC よりも大容量のメモリにアクセスできます。
NVIDIA Grace Blackwell アーキテクチャを基盤に構築された DGX Spark は、最大 1 ペタフロップスの FP4 AI パフォーマンスを実現し、128GB の統合 CPU-GPU メモリを搭載しています。これにより、開発者はより大規模なモデル、より長いコンテキスト ウィンドウ、より負荷の高いトレーニング ワークロードをローカルで実行するための十分な余裕を確保できます。
ファインチューニングにおいて、DGX Spark が以下を可能にします。
- より大規模なモデル: 300 億以上のパラメータを持つモデルは、コンシューマー向け GPU の VRAM 容量を上回る場合がよくありますが、DGX Spark の統合メモリなら、このモデルも余裕をもって収まります。
- より高度な手法: フルファインチューニングや強化学習ベースのワークフローでは、さらに多くのメモリと、高いスループットが要求されます。DGX Spark では、大幅に高速に実行できます。
- クラウドの待ち時間なしのローカル制御: 開発者は、クラウド インスタンスを待ったり、複数の環境を管理したりする代わりに、計算負荷の高いタスクをローカルで実行できます。
DGX Spark の強みは LLM だけにとどまりません。例えば、高解像度の拡散モデルは、一般的なデスクトップ PC の容量を超えるメモリを必要とすることがよくあります。FP4 のサポートと大容量の統合メモリを活用した DGX Spark は、わずか数秒で 1,000 枚の画像を生成し、クリエイティブなパイプラインやマルチモーダルなパイプラインで高いスループットを維持します。
以下の表は、DGX Spark で Llama ファミリーのモデルをファインチューニングする際のパフォーマンスを示しています。

ワークフローのファインチューニングが進化する中、オープン モデルの新しい Nemotron 3 ファミリーが RTX システムと DGX Spark に最適化されたスケーラブルな推論とロング コンテキストのパフォーマンスを提供します。
DGX Spark がいかに負荷の高い AI タスクを可能にするか、詳細をご覧ください。
#ICYMI — NVIDIA RTX AI PC の最新情報
🚀 NVIDIA RTX GPU 向けに最適化された FLUX.2 画像生成モデルがリリース
Black Forest Labs の新しいモデルが登場。FP8 量子化により VRAM を削減し、パフォーマンスを 40% 向上しています。
✨ Nexa.ai、エージェント型検索向け Hyperlink により、RTX PC でのローカル AI を拡張
新たなオンデバイス検索エージェントにより、検索拡張生成 (RAG) のインデックス作成は 3 倍に、LLM 推論は 2 倍に高速化しました。これにより、1 GB の高密度フォルダーのインデックス作成時間は、約 15 分からわずか 4 ~ 5 分に短縮されました。さらに、DeepSeek OCR が NexaSDK を介して GGUF 形式 でローカル実行が可能になりました。これにより、RTX GPU 上でチャート、数式、多言語 PDF のプラグアンドプレイ解析が可能になりました。
🤝 Mistral AI が NVIDIA GPU に最適化された新たなモデル ファミリーを発表
新たな Mistral 3 モデルはクラウドからエッジまで最適化されており、Ollama や Llama.cpp を通じて高速なローカルでの試行が可能です。
🎨Blender 5.0 が登場、HDR カラーとパフォーマンスを大幅に向上
このリリースでは、ACES 2.0 の高色域/HDR カラーと、髪の毛や毛皮のレンダリングを最大 5 倍高速化する NVIDIA DLSS が追加されました。さらに、巨大なジオメトリの処理能力の向上やグリース ペンシルのモーション ブラーにも対応しています。
Facebook、Instagram、TikTok、X で NVIDIA AI PC をフォローし、RTX AI PC ニュースレターを購読して、最新情報を入手しましょう。 LinkedIn と X で NVIDIA Workstation をフォローしてください。
ソフトウェア製品情報に関するお知らせをご覧ください。