
8 時間から 80 秒間に。NVIDIA、AI トレーニング時間の新記録を達成
速くなければ、1 番にはなれません。
世界の大手企業では、研究者とデータサイエンティストのチームが、より複雑な AI モデルを作っており、それらにはトレーニングが必要で、そのトレーニングには速さが求められます。
AI のリーダーとなるには、AI インフラストラクチャのリーダーになる必要があるというのには、理由があるからです。MLPerf が本日公表した AI トレーニングの結果が重要であるというのも同じ理由からです。
MLPerf のすべての6つのカテゴリーで、NVIDIA はワールドクラスの性能と用途の広さを証明しました。NVIDIA の AI プラットフォームは、大規模な実装での全体的な性能について 3 つ、アクセラレーター当たりの 5 つを含む、8 つの新記録を樹立しました。
| 記録タイプ | ベンチマーク | 記録 |
|---|---|---|
| 最大スケール (分単位でのトレーニング時間) |
物体検知 (重み大) – Mask R-CNN | 18.47 分 |
| 翻訳 (再帰) – GNMT | 1.8 分 | |
| 強化学習 – MiniGo | 13.57 分 | |
| アクセラレーター当たり (時間単位でのトレーニング時間) |
物体検知 (重み大) – Mask R-CNN | 25.39 時間 |
| 物体検知 (重み小) – SSD | 3.04 時間 | |
| 翻訳 (再帰) – GNMT | 2.63 時間 | |
| 翻訳 (非再帰) – Transformer | 2.61 時間 | |
| 強化学習 – MiniGo | 3.65 時間 |
アクセラレーター当たりの比較は、単一の NVIDIA DGX-2H (16 V100 GPUs) 上の MLPerf 0.6 の性能を、他で提出されたMiniGo を除く同じ規模の NVIDIA DGX-1 (8 V100 GPUs) との比較を使用し、結果を抽出している | MLPerf ID (最大スケール): Mask R-CNN: 0.6-23、GNMT: 0.6-26、MiniGo: 0.6-11 | MLPerf ID (アクセラレーター当たり): Mask R-CNN、SSD、GNMT、Transformer: 以上全て 0.6-20 を使用、MiniGo: 0.6-10
上記の数字は、MLPerf の AI ベンチマーク スイートの作成に協力した Google、Intel、Baidu、NVIDIA および数十のその他トップクラスのテクノロジ企業および大学の支援で得られたもので、信頼できるイノベーションであることを示しています。
簡単に言えば、NVIDIA の AI プラットフォームが、かつて一日分の労働時間の全てが必要だった、モデルのトレーニング時間を 2 分未満に短縮したのです。
企業は、このような生産性の大幅向上が重要であることを知っています。現在、スーパーコンピュータは AI に欠かせない装置となっており、AI のリーダーとなるためには強力な AI コンピューティング インフラストラクチャが必要です。
NVIDIA の最新の MLPerf 結果は、これらの要素を全て組み合わせたようなものであり、NVIDIA V100 Tensor コア GPU をスーパーコンピュータ クラスのインフラストラクチャに織り込むことで得られる利益を示しています。
2017 年の春の時点では、NVIDIA DGX-1 システムに V100 GPU を搭載し、画像認識モデルの ResNet-50 をトレーニングするには、一日の労働時間全て、つまり 8 時間が必要でした。
現在、同じ V100 GPU を使い、Mellanox InfiniBand にて相互接続された NVIDIA DGX SuperPOD にて、NVIDIA が最適化した最新の AI ソフトウェアで AI を分散トレーニングすると、わずか 80 秒で完了します。
まさに、コーヒーを 1 杯飲むよりも短い時間なのです。
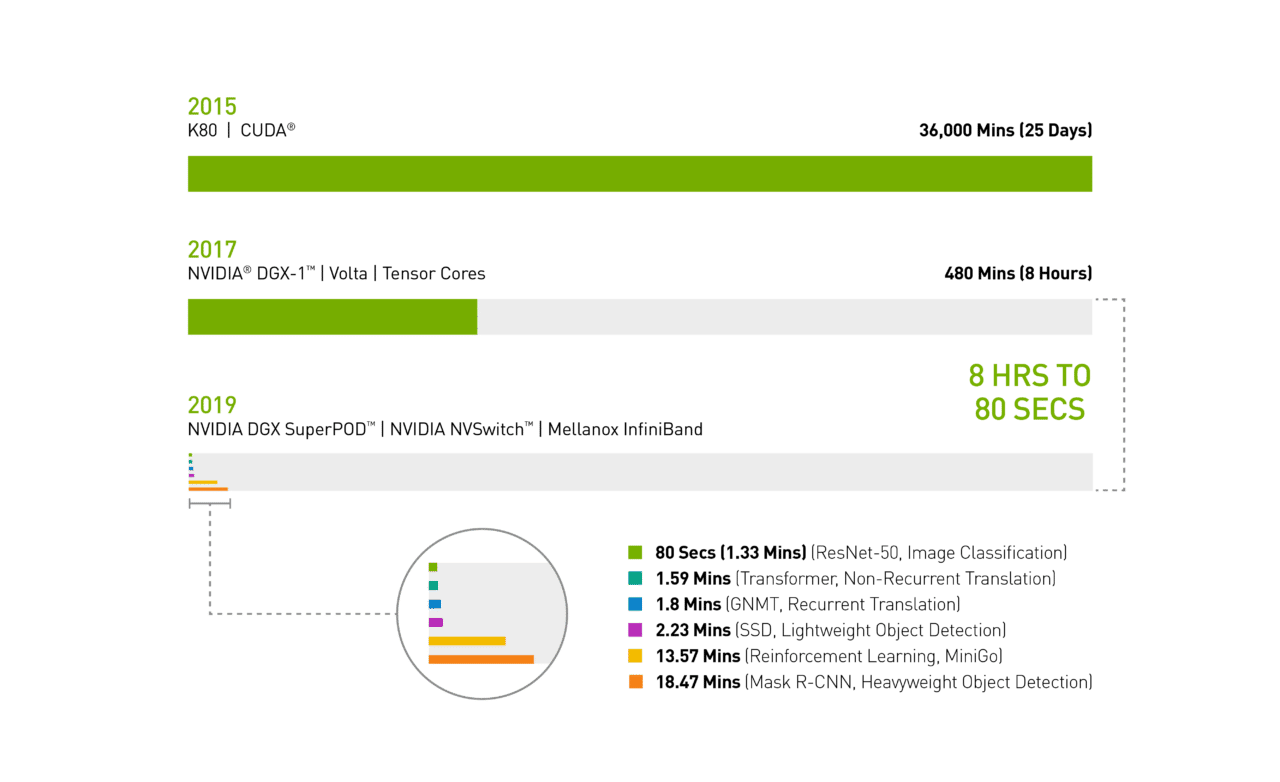
チャート 1: AI のタイムマシン
2019 年の MLPerf ID (チャートの上下順): ResNet-50: 0.6-30 | Transformer: 0.6-28 | GNMT: 0.6-14 | SSD: 0.6-27 | MiniGo: 0.6-11 | Mask R-CNN: 0.6-23
AI に欠かせない装置:ワークロードをより速く処理する DGX SuperPOD
今日の MLPerf の結果をより詳しく見れば、NVIDIA DGX SuperPOD が、MLPerf の 6 つのカテゴリーのそれぞれを 20 分未満で完了できた唯一の AI プラットフォームであることがわかります。

チャート 2: DGX SuperPOD、AI の記録を大幅に更新
最大規模での MLPerf 0.6 性能 | 大規模実装での MLPerf ID: RN50 v1.5: 0.6-30、0.6-6 | Transformer: 0.6-28、0.6-6 | GNMT: 0.6-26、0.6-5 | SSD: 0.6-27、0.6-6 | MiniGo: 0.6-11, 0.6-7 | Mask R-CNN: 0.6-23、 0.6-3
さらに詳しく見てみると、NVIDIA の AI プラットフォームは、重み付けを大きくした物体検知および強化学習におけるトレーニングの合計時間を測定したところ、最も困難な AI の問題でも傑出した性能を発揮したことが明らかになりました。
Mask R-CNN ディープ ニューラル ネットワークを使った重み付けの大きい物体検知により、ユーザーは最先端のインスタンス セグメンテーションが利用できるようになります。インスタンス セグメンテーションによって、たとえば、カメラやセンサー、ライダー、超音波画像などの複数のデータ ソースとの組み合わせで、特定の物体を正確に識別および位置認識できるようになります。
このタイプの AI ワークロードにより、自律走行車両のトレーニングができるようになり、歩行者や他の物体の正確な位置を自動運転車に知らせることができます。現実生活での用途は他にもあり、たとえば、医師が医用スキャンで腫瘍の発見および識別ができるようになります。命に関わることです。
NVIDIA の重み付けの大きい物体検知の完了通知時間はわずか 19 分未満で、次点の完了通知時間のほぼ半分となっています。
強化学習も難しいカテゴリーです。この AI 手法は、生産を合理化するために工場で働いているロボットのトレーニングに使われています。この手法は、交通渋滞を軽減するための、都市内の交通信号制御にも使用されています。NVIDIA DGX SuperPOD を使用して、NVIDIA は MiniGo AI 強化学習モデルを新記録の 13.57 分でトレーニングしました。
コーヒーを飲む時間もない速さ: 即座に利用できる AI インフラストラクチャが世界最高レベルの性能を発揮
もっとも、ベンチマークを上回るよりも重要なのは、イノベーションのスピードアップです。そのため、DGX SuperPOD では、パワフルであるだけでなく、簡単に設定できるようになっています。
NVIDIA のNGC コンテナ レジストリより自由に入手できる、最適化された CUDA-X AI ソフトウェアをフル活用した DGX SuperPOD により、世界最高レベルの AI 性能をすぐに利用することができます。
DGX SuperPOD により、あらゆる AI フレームワークと開発環境に対応するために NVIDIA と連携している、130 万人以上の CUDA 開発者で構成されたエコシステムとつながることができます。
NVIDIA は、数百万行のコードの最適化を可能にし、クラウドでも、データセンターでも、エッジでも、NVIDIA GPU のあるあらゆる場所で、お客様が自身の AI プロジェクトに生命を吹き込めるようにしています。
今日は速く、明日はもっと速くなる AI インフラストラクチャ
いまでも十分に速いのですが、このプラットフォームはつねに速度を上げています。NVIDIA は毎月、CUDA-X AI の新たな最適化と性能改良を行っており、NGC コンテナ レジストリで包括的なソフトウェア スタックを自由にダウンロードできるようにしています。そのなかには、コンテナ化されたフレームワークや事前にトレーニングを受けたモデル、スクリプトが含まれています。
CUDA-X AI ソフトウェアでのこのようなイノベーションにより、NVIDIA DGX-2H サーバーは、わずか 7 か月前に当社が投稿した、MLPerf 0.6 での完了通知速度より、スループットが最大で 80% 向上しました。
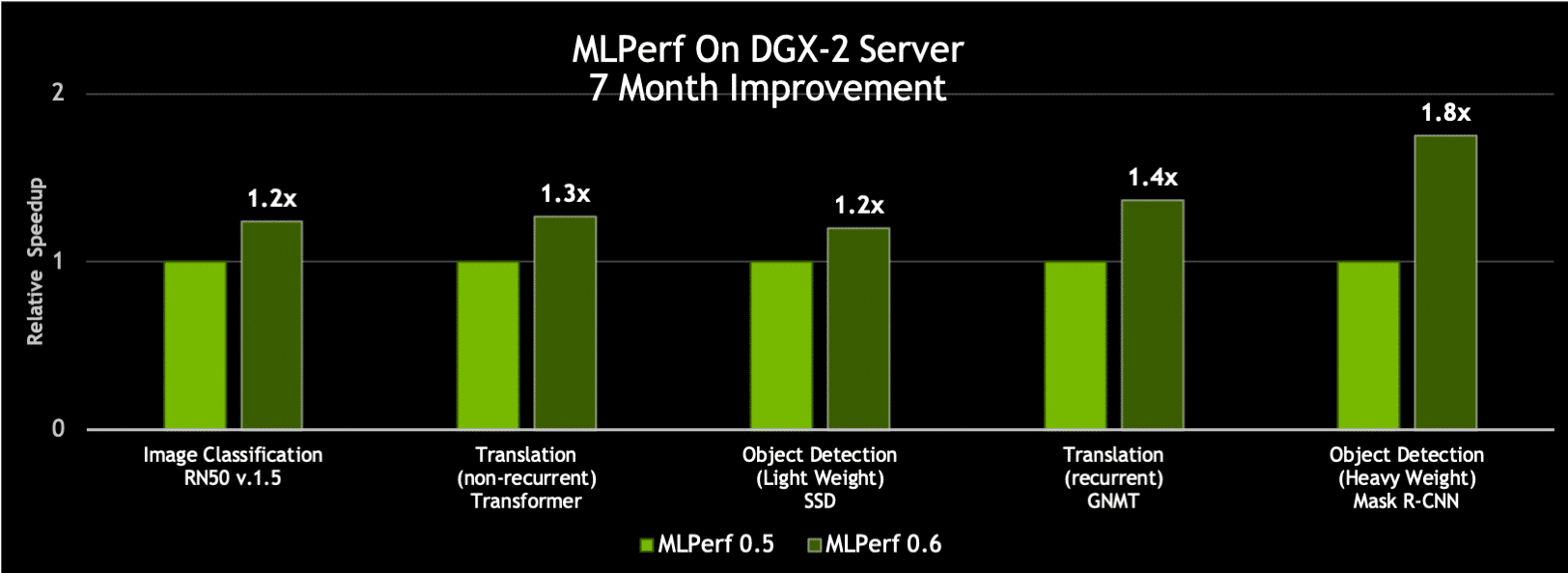
チャート 3: 同じサーバーで最大 80% の性能向上
単一のエポック (ニューラル ネットワークをデータセットが 1 回通過すること) での単一の DGX-2H サーバーのスループット比較 | MLPerf ID 0.5および0.6 の比較: ResNet-50 v1.5: 0.5-20/0.6-30 | Transformer: 0.5-21/0.6-20 | SSD: 0.5-21/0.6-20 | GNMT: 0.5-19/0.6-20 | Mask R-CNN: 0.5-21/0.6-20
要約すると、上記の成果は数百億ドルの投資の賜物なのです。すべては今日の仕事を迅速にできるようにするためで、明日はさらに迅速に対応できるようにするためなのです。