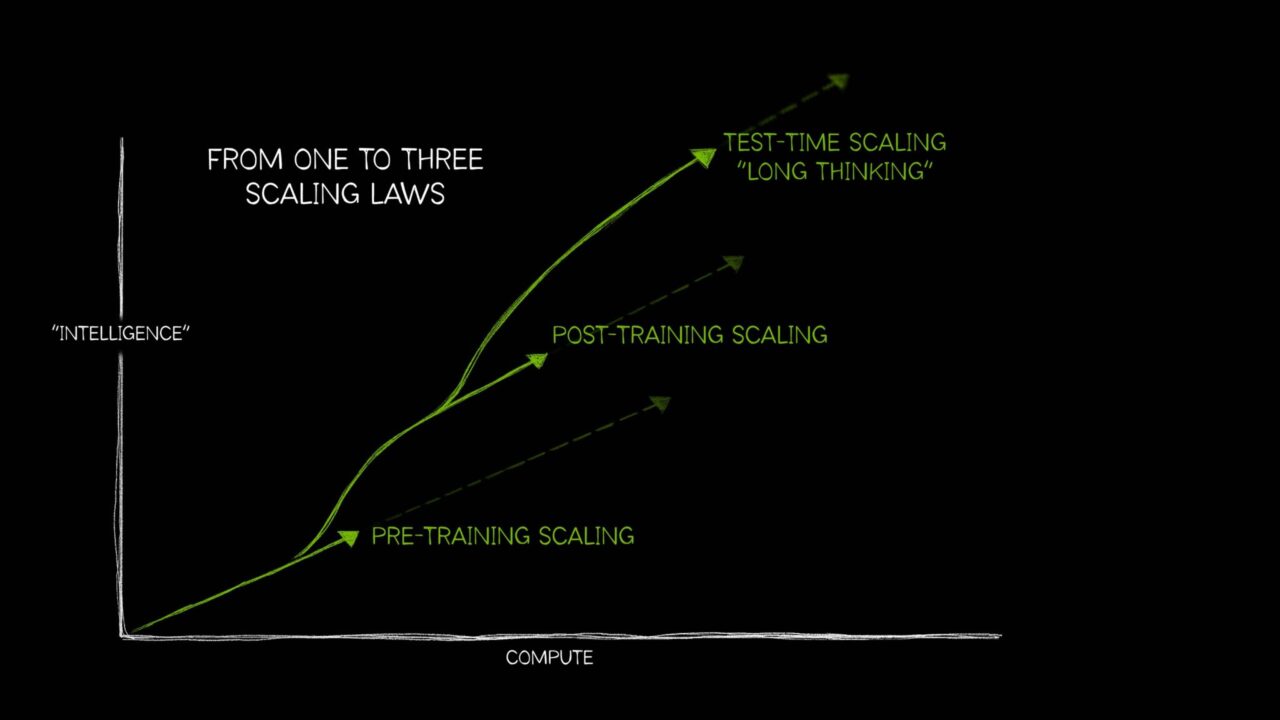
一般に広く理解されている自然界の経験則で、たとえば、「上がったものは必ず下りてくる」、「すべての作用は等しい逆向きの反作用を生む」といったものがあるように、AI の分野でも長い間、単一の考え方が主流を占めてきました。すなわち、より多くの計算、より多くのトレーニング データ、より多くのパラメーターが、より優れた AI モデルを生み出すという考え方です。
しかし、AI はその後、3 つの明確な法則を必要とするまでに成長しました。これらの法則は、計算資源の適用の仕方によってモデルのパフォーマンスにどのような影響が及ぶかを説明するものです。これらの AI スケーリング則 (事前トレーニング スケーリング、事後トレーニング スケーリング、そして「長時間思考」とも呼ばれるテストタイム スケーリング) は、ますます複雑化する多様な AI ユース ケースのため、追加の計算資源を活用する技術とあわせてこの分野がどのように進化してきたかを反映しています。
最近では、推論時に計算能力を追加して精度を向上させるテストタイム スケーリングの手法が広まった結果、AI 思考モデル、つまり特定のタスクを解決するのに必要な手順を説明しながら、複数の推論パスを実行して複雑な問題に取り組む新しいタイプの大規模言語モデル (LLM) が実現されました。テストタイム スケーリングでは、AI 思考を支えるために膨大な計算資源が必要となることから、アクセラレーテッド コンピューティングの需要が今後さらに高まるでしょう。
事前トレーニング スケーリングとは
事前トレーニング スケーリングとは、AI 開発における基本的な法則です。トレーニング データセットのサイズ、モデルのパラメーター数、および計算資源を増やすことで、モデルのインテリジェンスや精度を予測可能な形で改善できることを示しました。
データ、モデルのサイズ、計算能力の 3 つの要素は互いに関連しています。この研究論文で概説されている事前トレーニング スケーリング則によると、より大きなモデルに多くのデータを与えることで、モデルの全体的なパフォーマンスが向上します。これを実現するには、開発者は計算能力を拡張する必要があります。したがって、これらの大規模なトレーニング ワークロードを実行する目的で、強力なアクセラレーテッド コンピューティングのリソースが求められます。
この事前トレーニング スケーリング則が、画期的な能力を実現する大規模モデルの誕生につながりました。また、10 億から 1 兆ものパラメーターを持つ Transformer モデル、Mixture of Experts モデル、新しい分散トレーニング テクノロジなど、モデル アーキテクチャにおける大きなイノベーションも促しました。これらはすべて、膨大な計算能力を必要とします。
そして事前トレーニング スケーリング則は、今後も有用であり続けます。人間が作るマルチモーダル データの量が増え続ける限り、テキスト、画像、音声、ビデオ、センサー情報などの膨大なデータが、将来の強力な AI モデルのトレーニングに活用されるでしょう。
事後トレーニング スケーリングとは
大規模な基盤モデルの事前トレーニングは、誰にでもできるものではありません。多額の投資、高度な専門家、豊富なデータセットが必要となるためです。しかし、モデルが事前トレーニングされてリリースされると、その事前トレーニング済みモデルを他のアプリケーションに適応させるための基盤として利用できるようになり、AI 導入の障壁が低くなります。
この事後トレーニングのプロセスにより、企業や広範な開発者コミュニティ全体で、アクセラレーテッド コンピューティングへの累積的な需要がさらに高まります。人気の高いオープンソース モデルには、さまざまな分野でトレーニングされた派生モデルが数百、数千の単位で存在することもあります。
さまざまなユース ケースに対応するこうした派生モデルのエコシステムを開発するには、元となる基盤モデルの事前トレーニングと比べて約 30 倍の計算能力が必要になる場合もあります。
事後トレーニングのテクノロジを利用すれば、組織が希望するユース ケース用にモデルの特異性や関連性をさらに高めることができます。事前トレーニングは AI モデルを学校に通わせて基礎的なスキルを学ばせること、事後トレーニングは想定する仕事に合ったスキルでモデルを強化することにたとえられます。たとえば LLM に事後トレーニングを施せば、感情分析や翻訳などのタスクを実行させたり、医療や法律などの特定分野の専門用語を理解させたりできるようになります。
事後トレーニング スケーリング則においては、ファインチューニング、枝刈り、量子化、蒸留、強化学習、合成データ拡張といったテクノロジを活用することで、事前トレーニング済みモデルのパフォーマンスを計算効率、精度、該当分野への特異性の面でさらに改善できます。
- ファインチューニングでは、追加のトレーニング データを使用し、特定の分野や用途に合わせて AI モデルのカスタマイズを行います。これは、組織の内部のデータセットや、サンプル モデルの入力と出力のペアを使用して実施されます。
- 蒸留には、大規模で複雑な教師モデルと軽量な生徒モデルの 2 つの AI モデルを必要とします。最も一般的な蒸留テクノロジであるオフライン蒸留では、生徒モデルが、事前トレーニング済みの教師モデルの出力を模倣するように学習します。
- 強化学習 (RL) は、報酬モデルを利用して、特定のユース ケースに沿った意思決定を行えるようエージェントをトレーニングする機械学習のテクノロジです。エージェントは、環境との相互作用を通じ、長期的に累積報酬を最大化する意思決定を下すことを目指します。たとえば、ユーザーからの「いいね」を受けて正の強化を行うチャットボットの LLM などです。このテクノロジは、人間のフィードバックによる強化学習 (RLHF) として知られています。また、より新しいテクノロジとして AI のフィードバックによる強化学習 (RLAIF) があります。RLAIF は、AI モデルのフィードバックを用いて学習プロセスを導き、事後トレーニングを合理化します。
- ベスト オブ N サンプリングでは、言語モデルから複数の出力を生成し、報酬モデルに基づいて最も高い報酬スコアを持つ出力を選択します。この手法は、モデル パラメーターを変更せずに AI の出力を改善する目的で使用されることが多く、強化学習によるファインチューニングの代替的なアプローチとなります。
- 検索手法では、最終的な出力を選択する前に、幅広い潜在的な意思決定経路を探索します。この事後トレーニング テクノロジを利用すれば、モデルの応答を反復的に改善することができます。
開発者は事後トレーニングをサポートするため、合成データを使って、ファインチューニング用のデータセットを拡張または補完することができます。現実世界のデータセットを AI 生成データで補完することで、オリジナルのトレーニング データでは表現が不足している、または欠落しているエッジ ケースへのモデルの能力を向上させることが可能になります。

テストタイム スケーリングとは
LLM は、入力プロンプトに対して迅速に応答します。このプロセスは単純な質問に対する正しい答えを得るには適していますが、ユーザーが複雑な問い合わせ (クエリ) を行う場合にはうまく機能しないことがあります。複雑な質問に答える能力は、エージェント型 AI のワークロードにおいて不可欠な機能です。LLM には質問のロジックを理解してから回答を導き出すことが求められます。
これは、多くの人間の思考の仕組みと似ています。人は「2+2 の計算を求められた場合、足し算や整数の基本についてわざわざ説明しなくても、即座に答えを出せるでしょう。しかし、その場で会社の利益を 10% 伸ばすための事業計画を作れと言われた場合、人はおそらく多様な選択肢のロジックを検討し、複数ステップにわたる回答を出すでしょう。
長時間思考とも呼ばれるテストタイム スケーリングは、推論中に実行されます。ユーザーの入力に対して即座に回答を生成する従来の AI モデルとは異なり、このテクノロジを利用するモデルでは、推論中に追加の計算資源を割り当て、複数の潜在的な回答を論理的に検討した後で、最適な回答を導き出します。
開発者向けの複雑なカスタマイズ コードの生成のようなタスクでは、この AI 思考プロセスに数分、あるいは数時間かかることもあります。従来の LLM 上での単一の推論パスと比較すると、難しいクエリに対応するには 100 倍以上の計算能力が必要になるケースも容易に考えられます。従来の LLM が複雑な問題に対して 1 回で正解を導き出せる可能性は非常に低いでしょう。
このテストタイムの計算能力により、AI モデルは特定の問題に対して複数の解決策を模索し、複雑なリクエストを複数のステップに分解することが可能になります。多くの場合、思考時にその過程をユーザーに示します。複数の思考と計画のステップが要求される自由形式の質問 (プロンプト) を AI モデルに与えると、テストタイム スケーリングの結果、より質の高い応答が得られることが研究で明らかになっています。
テストタイムの計算方法には、以下のような多くのアプローチが含まれます。
- 「思考の連鎖」プロンプティング: 複雑な問題を、一連のより簡単なステップに分解します。
- サンプリングと多数決: 同じプロンプトに対して複数の応答を生成し、最も頻繁に繰り返される回答を最終的な出力として選択します。
- 検索: 木構造の回答の中から複数の経路を探索し、評価します。
ベスト オブ N サンプリングのような事後トレーニング手法は、推論時の長時間思考にも利用でき、人間の好みやその他の目的に沿って応答を最適化することができます。

テストタイム スケーリングが AI 思考を可能にする仕組み
テストタイム計算を利用すれば、AI はユーザーからの複雑な自由形式の問い合わせに対して、論理的に考えられた、有用かつ正確な回答を提供できるようになります。これらの能力は、自律型のエージェント型 AI やフィジカル AI のアプリケーションに期待される、詳細な複数ステップの思考タスクに取り組むために不可欠な存在となるでしょう。業界全体で、非常に優れたアシスタントをユーザーに提供することで、効率性と生産性を高め、作業を加速させることができます。
ヘルスケア分野では、モデルがテストタイム スケーリングを利用することで、膨大なデータを分析して病気の進行を予想したり、新しい治療法から生じる可能性のある合併症を薬物分子の化学構造に基づいて予測したりすることが可能になります。あるいは、臨床試験のデータベースを精査して、個々の患者の病状に適した治療法を提案したり、さまざまな研究の長所と短所について思考過程を共有したりすることも考えられます。
小売業やサプライチェーン物流業においては、短期的な業務課題への対応と長期的な戦略目標の達成に求められる複雑な意思決定を行う上で、長時間思考が役立ちます。思考のテクノロジは、複数のシナリオを同時に予測および評価することで、リスクを軽減し、スケーラビリティの課題に対応するのに有用な場合があります。その結果、より正確な需要予測、サプライチェーンの移動ルートの合理化、そして組織のサステナビリティの取り組みに沿った調達判断が可能になります。
またグローバル企業においては、このテクノロジを、詳細な事業計画の立案、ソフトウェアのデバッグ用の複雑なコードの生成、さらには配送トラック、倉庫ロボット、ロボタクシーの最適な移動ルートの算出などに応用することも可能です。
AI 思考モデルは急速に進化しています。ここ数週間で OpenAI の o1-mini と o3-mini、DeepSeek R1、Google DeepMind の Gemini 2.0 Flash Thinking が登場しており、さらに新しいモデルが間もなく登場する見込みです。
これらのモデルは、推論中に論理的な検討を行い、複雑な質問に対する正しい答えを生成するために、はるかに多くの計算能力を必要とします。つまり、企業は自社のアクセラレーテッド コンピューティングのリソースを拡張して、複雑な問題解決、コーディング、および複数ステップにわたる計画立案に対応できる次世代の AI 思考ツールを提供する必要があります。
NVIDIA AI で推論を高速化することのメリットもご紹介しています。