
データは AI アプリケーションの原動力ですが、エンタープライズのデータはその規模の大きさから、効果的に使用するにはコストや時間がかかりすぎることがよくあります。
IDC の Global DataSphere1 によると、エンタープライズは 2028 年までに年間 317 ゼタバイトのデータを生成し、このうち 29 ゼタバイトは固有データの作成により生成されると予想されます。317 ゼタバイトの 78% は非構造化データで、そのうち 44% は音声と動画です。データ量が非常に多く、データの種類多様であるため、ほとんどの生成 AI アプリケーションは、保存あるいは生成されるデータの総量のわずかしか使用していません。
エンタープライズが AI 時代で成功を収めるには、自分たちの全データを活用する方法を見つける必要があります。これは、従来のコンピューティングやデータ処理技術では不可能です。その代わりにエンタープライズに必要となるのが、AI クエリ エンジンです。
AI クエリ エンジンとは?
簡単に言えば、AI クエリ エンジンは AI アプリケーションや AI エージェントをデータに接続するシステムです。エージェント型 AI の重要な構成要素であり、組織のナレッジ ベースと AI 搭載アプリケーションの間の橋渡しとして機能し、より正確でコンテキストを意識した応答を可能にします。
AI エージェントは AI クエリ エンジンの基盤となっており、情報の収集や、人間の従業員を支援する作業を行うことができます。AI エージェントは、多くのデータ ソースから情報を収集し、プランニング、リーズニング、アクションを実行します。AI エージェントはユーザーとコミュニケーションを取ることができるほか、バックグラウンドでの動作も可能であるため、人間のフィードバックや人間とのやりとりは常に利用可能です。
実際のところ、AI クエリ エンジンは大量のデータを効率的に処理し、ナレッジを抽出して保存し、そのナレッジに対してセマンティック検索を実行する高度なシステムです。しかもそのナレッジは AI によってすばやく取得して使用できます。
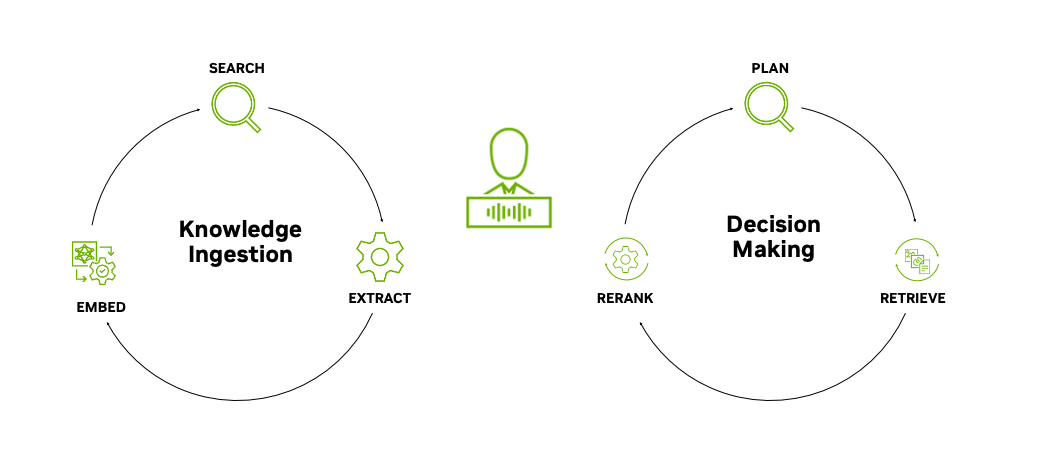
AI クエリ エンジンが非構造化データ内にあるインテリジェンスを解放
エンタープライズの AI クエリ エンジンは、さまざまな形式で保存されているナレッジにアクセスできますが、非構造化データからインテリジェンスを抽出可能であることは、AI クエリ エンジンが実現する最も大きな進歩の 1 つです。
洞察を生成するために、従来のクエリ エンジンは、リレーショナル データベースなど、構造化クエリとデータ ソースに依存しています。ユーザーは SQL などの言語を使用して正確なクエリを作成する必要があり、結果は定義済みのデータ形式に限定されます。
それとは対照的に、AI クエリ エンジンは、構造化データ、半構造化データ、非構造化データを処理できます。非構造化データの典型的な形式は、PDF、ログ ファイル、画像、動画であり、これらはオブジェクト ストア、ファイル サーバー、並列ファイル システムに保存されます。AI エージェントは、自然言語を使用してユーザーとコミュニケーションを取るほか、エージェント同士でも通信します。そのため、さまざまなデータ ソースにアクセスすることで、ユーザーの意図を、たとえあいまいな場合でも解釈できます。AI エージェントは会話形式で結果を提供できるため、ユーザーは自分で結果を解釈できます。
こうした能力により、行と列にきちんと収まるデータだけでなく、あらゆる種類のデータからより多くの洞察やインテリジェンスを引き出すことができます。
たとえば、DataStax や NetApp などの企業は、顧客が次世代アプリケーションで利用できる AI クエリ エンジンを持てるようにする AI データ プラットフォームを構築中です。
AI クエリ エンジンの主な機能
AI クエリ エンジンには、いくつかの重要な機能があります:
- 多様なデータ処理: AI クエリ エンジンは、テキスト、PDF、画像、動画、特殊データ タイプといった複数のソースから取得した構造化データ、半構造化データ、非構造化データなど、さまざまなデータ タイプにアクセスして処理できます。
- スケーラビリティ: AI クエリ エンジンはペタバイト規模のデータを効率的に処理できるため、エンタープライズのすべてのナレッジを AI アプリケーションですばやく利用できるようになります。
- 正確な検索: AI クエリ エンジンは、複数のソースからのナレッジを高精度かつ高性能で埋め込み、ベクトル検索、再ランク付けすることが可能です。
- 継続的な学習: AI クエリ エンジンは AI 搭載アプリケーションからのフィードバックを保存して組み込むことができるため、AI データ フライホイールが作成され、その中でフィードバックを使用してモデルが改良され、時間の経過とともにアプリケーションの有効性が向上します。
検索拡張生成 (RAG) は、AI クエリ エンジンの構成要素です。RAG は、生成 AI モデルの性能を利用することでデータに対する自然言語インターフェースとして機能するため、モデルは応答生成プロセス中に大規模なデータセットから関連情報にアクセスして組み込むことが可能です。
RAG を使用すると、どんな企業や組織でも、自社の技術情報、ポリシー マニュアル、動画、その他のデータを有用なナレッジ ベースに変換できます。その後に AI クエリ エンジンがこれらのソースを利用することで、顧客関係、従業員のトレーニング、開発者の生産性などの分野に対応できるようになります。
さらに新たな情報検索技術やナレッジの保管方法の研究開発も進んでおり、AI クエリ エンジンの能力は急速に進化することが期待されています。
AI クエリ エンジンの影響
エンタープライズは AI クエリ エンジンを使用することで、AI エージェントの性能を最大限に活用することが可能になり、従業員を膨大な量のエンタープライズ ナレッジにつなぐことや、AI 生成の応答の精度と関連性の向上、これまで利用されていなかったデータ ソースの処理や活用、AI アプリケーションを継続的に改善するデータ駆動型 AI フライホイールの作成などが可能になります。
例を挙げると、パーソナライズされた 24 時間年中無休のカスタマー サービス エクスペリエンスを提供する AI 仮想アシスタント、動画の検索と要約を行う AI エージェント、ソフトウェアの脆弱性を分析する AI エージェント、AI リサーチ アシスタントなど、さまざまです。
生データと AI 搭載アプリケーションの間の溝を埋める AI クエリ エンジンは、組織がデータから価値を引き出すのを支援する重要な役割を果たすようになるでしょう。
AI の自社データへの接続を考えているエンタープライズには、NVIDIA Blueprint が役立ちます。NVIDIA Blueprint についての詳細はこちらからご確認ください。また、NVIDIA API カタログでの試用も可能です。
- IDC、「Global DataSphere Forecast」、2024 年