
今年はあらゆる業界の企業が、AI サービスを展開しています。Microsoft、Oracle、Perplexity、Snap、その他の数百社に及ぶ大手企業にとっては、世界トップクラスの半導体、システム、ソフトウェアで構成されるフル スタックの NVIDIA AI 推論プラットフォームを利用することが、高スループットかつ低レイテンシの推論、優れたユーザー体験、そしてコスト削減を実現する上での鍵となります。
NVIDIA の推論ソフトウェアの最適化と NVIDIA Hopper プラットフォームの進歩は、各業界が最新の生成 AI モデルを提供し、卓越したユーザー体験を実現すると同時に総所有コスト (TCO) を最適化するために役立っています。また Hopper プラットフォームは、前世代と比較して、推論ワークロードのエネルギー効率を最大 15 倍向上させています。
AI 推論は、スループットとユーザー体験の間で適切なバランスを取るために多くのステップを必要とすることから、非常に難しいものです。
しかし、その基本的な目標はシンプルです。すなわち、より低いコストでより多くのトークンを生成することです。トークンとは、大規模言語モデル (LLM: Large Language Model) システムにおける単語のことを表します。そして AI 推論サービスでは通常、生成される 100 万トークンごとに課金が行われることから、この目標は、AI への投資と各タスクへの消費エネルギーに対して最も分かりやすい形でのリターンをもたらします。
フルスタックのソフトウェア最適化は、AI 推論のパフォーマンスを高め、この目標を達成する上での鍵となります。
費用対効果の高いユーザー スループット
企業はしばしば、推論ワークロードのパフォーマンスとコストのバランスを取るという課題に直面しています。既製のモデルやホスト型モデルで対応可能な顧客やユース ケースもありますが、カスタマイズが必要な場合もあります。NVIDIA のテクノロジは、モデルの展開を簡素化すると同時に、AI 推論ワークロードのコストとパフォーマンスを最適化します。さらに、顧客は自ら展開すると選んだモデルで柔軟性とカスタマイズ性を体験できます。
NVIDIA NIM マイクロサービス、NVIDIA Triton Inference Server、NVIDIA TensorRT ライブラリは、ユーザーのニーズに合わせて NVIDIA が提供している推論ソリューションの一部です。
- NVIDIA NIM 推論マイクロサービスは、クラウド、データセンター、エッジ、ワークステーションなどのあらゆるインフラに AI 基盤モデルを迅速に展開できるよう、事前にパッケージ化され、パフォーマンスも最適化されています。
- NVIDIA Triton Inference Server は、NVIDIA の最も人気の高いオープンソース プロジェクトの 1 つです。ユーザーは、トレーニングに使用された AI フレームワークに関わらず、あらゆるモデルをパッケージ化して提供することができます。
- NVIDIA TensorRT は、高性能なディープラーニング推論ライブラリで、ランタイムとモデルの最適化により、低レイテンシかつ高スループットの推論を本番アプリケーションに提供します。
あらゆる主要なクラウド マーケットプレイスで利用可能な NVIDIA AI Enterprise ソフトウェア プラットフォームは、これらのソリューションをすべて含んでおり、エンタープライズグレードのサポート、優れた安定性、管理性、セキュリティを提供します。
フレームワークに依存しない NVIDIA AI 推論プラットフォームにより、企業は生産性、開発、インフラおよびセットアップ コストを節約できるようになります。また NVIDIA のテクノロジにより、ダウンタイムや不正取引を回避し、e コマース ショッピングのコンバージョン率を向上させ、AI を活用した新たな収益源を生み出すことが可能になるため、全体としてビジネスの収益を向上させることができます。
クラウドベースの LLM 推論
LLM の展開を容易化するため、NVIDIA はすべての主要なクラウド サービス プロバイダーと緊密に協力し、NVIDIA 推論プラットフォームが最小限のコードで、あるいはコード不要でクラウドにシームレスに展開できるようにしました。NVIDIA NIM は、以下のようなクラウドネイティブ サービスと統合されています。
- Amazon SageMaker AI、Amazon Bedrock Marketplace、Amazon Elastic Kubernetes Service
- Google Cloud の Vertex AI、Google Kubernetes Engine
- Microsoft Azure AI Foundry (近日利用可能)、Azure Kubernetes Service
- Oracle Cloud Infrastructure のデータ サイエンス ツール、Oracle Cloud Infrastructure Kubernetes Engine
さらに、カスタマイズされた推論の展開においては、NVIDIA Triton Inference Server がすべての主要なクラウド サービス プロバイダーに深く統合されています。
例えば、OCI Data Science プラットフォームを利用すれば、モデルの展開の際にコマンド ライン引数でスイッチをオンにするだけで NVIDIA Triton を簡単に展開でき、即座に NVIDIA Triton 推論エンドポイントを起動できます。
同様に、Azure Machine Learning では、Azure Machine Learning Studio によるノーコード展開、または Azure Machine Learning CLI によるフルコード展開のいずれかで NVIDIA Triton を展開できます。AWS では SageMaker Marketplace から NVIDIA NIM をワンクリックで展開可能なほか、Google Cloud では Google Kubernetes Engine (GKE) 上でワンクリック展開オプションを提供しています。
NVIDIA AI 推論プラットフォームは、AI 予測を提供するために一般的な通信方法を使用しており、クラウドベースのインフラ内でユーザーのニーズの拡大や変化に合わせて自動的に調整することもできます。
LLM の高速化からクリエイティブ ワークフローの強化、そして契約管理の変革に至るまで、NVIDIA の AI 推論プラットフォームは、さまざまな業界で実際に改善を実現しています。コラボレーションとイノベーションにより、以下の企業がどのように新次元の効率性と拡張性を達成しているかご覧ください。
Perplexity AI: 毎月 4 億件の検索クエリに対応
AI を利用した検索エンジンである Perplexity AI は、毎月 4 億 3,500 万件以上のクエリを処理しています。各クエリは複数の AI 推論リクエストを表します。この需要を満たすため、Perplexity AI チームは NVIDIA H100 GPU、Triton Inference Server、TensorRT-LLM を採用しました。
Perplexity は、8B や 70B といった Llama 3 のバリエーションを含む 20 以上の AI モデルをサポートし、検索、要約、質問への回答などの多様なタスクを処理しています。同社は、より小さな分類モデルを使用し、NVIDIA Triton が管理する GPU ポッドにタスクをルーティングすることで、コスト効率が良く、応答性が高いサービスを厳格なサービス レベル契約の下で提供しています。
Perplexity は、複数の GPU 間で LLM を分割するモデル並列処理により、低レイテンシと高精度を維持しながらコストを 3 分の 1 にまで削減することに成功しました。このベストプラクティスのフレームワークは、NVIDIA のアクセラレーテッド コンピューティングによって、いかに IT チームが増加する AI の需要に対応し、TCO を最適化し、シームレスな拡張を実現することができるかを示しています。
Recurrent Drafter (ReDrafter): 応答時間を短縮
オープンソースの研究の進歩が、AI 推論の民主化に役立っています。最近、NVIDIA は、Apple が公開した投機的デコーディングへのオープンソースのアプローチである ReDrafter を、NVIDIA TensorRT-LLM に組み込みました。
ReDrafter は、より小さな「ドラフト」モジュールを使用してトークンを並列に予測し、その後、これらをメイン モデルで検証します。このテクノロジにより、特にトラフィックが少ない時間帯に、LLM の応答時間が大幅に短縮されます。
Docusign: 契約管理を変革
デジタル契約管理のリーダーである Docusign は、NVIDIA を採用してインテリジェント契約管理プラットフォームを強化しました。世界中に 150 万を超える顧客を持つ Docusign は、AI 駆動の洞察を提供しながら、スループットを最適化し、インフラの費用を管理する必要がありました。
NVIDIA Triton は、すべてのフレームワークに対応する統合された推論プラットフォームを提供し、契約データを実用的な洞察へと変換することで、商品の市場投入にかかる時間を短縮し、生産性を向上させました。Docusign が NVIDIA 推論プラットフォームを採用した結果、拡張可能な AI インフラが顧客体験と業務効率にプラスの影響をもたらすことが明らかになりました。
Docusign のシニア プロダクト マネージャーである Alex Zakhvatov 氏は次ののように語りました。「NVIDIA Triton のおかげで仕事がしやすくなりました。AI モデル用に、フレームワークごとの推論サーバーをカスタムで展開する必要がなくなりました。当社は Triton をすべての AI フレームワークのための統合推論サーバーとして活用しており、適切な本番シナリオを特定することで、コストとパフォーマンスを最適化する取り組みを行っています」
Amdocs: 通信事業者のカスタマー ケアを強化
Amdocs は、通信およびメディア プロバイダー向けのソフトウェアやサービスを提供している大手プロバイダーです。オープンでセキュア、費用対効果が高く、LLM に依存しないフレームワークとして、通信事業者向けのドメイン特化型の生成 AI プラットフォームである amAIz を開発しました。Amdocs は、NVIDIA DGX Cloud と NVIDIA AI Enterprise ソフトウェアを使用することで、市販の LLM およびドメイン適応モデルに基づくソリューションを提供しており、サービス プロバイダーがエンタープライズグレードの生成 AI アプリケーションを構築および展開できるように支援しています。
NVIDIA NIM を使用することで、Amdocs は展開されたユース ケースで消費されるトークンの数を、データの前処理で最大 60%、推論で 40% 削減することに成功しました。さまざまな要因や使用量に応じて、トークンあたりのコストを大幅に削減しながら、従来と同等の精度を維持しています。また、このコラボレーションにより、クエリのレイテンシ (待ち時間) が約 80% 短縮され、エンド ユーザーはほぼリアルタイムの応答を体験できるようになりました。こうした高速化により、商取引、カスタマー サービス、オペレーションなどのあらゆる場面でユーザー体験が向上します。
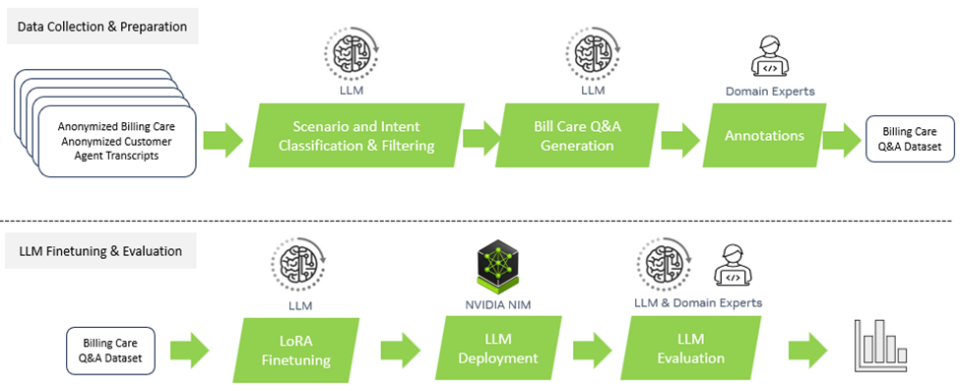
Snap: AIで小売業に革命を起こす
Snap の Screenshop 機能により、買い物で完璧な服装を見つけるのがかつてないほど簡単になりました。この AI 搭載ツールは Snapchat に統合されており、写真に写っているファッション アイテムをユーザーが見つけるのに役立ちます。NVIDIA Triton は、Screenshop のパイプラインを実現する上で重要な役割を果たしました。このパイプラインでは、TensorFlow や PyTorch などの複数のフレームワークを使用して画像を処理します。

パイプラインを単一の推論サーバー プラットフォームに統合することで、Snap は、開発時間とコストを大幅に削減すると同時に、更新されたモデルのシームレスな展開を可能にしました。その結果、AI によるスムーズなユーザー体験を実現できました。
Snap の機械学習エンジニアである Ke Ma 氏は次のように語りました。「当社の Screenshop パイプライン用にカスタムの推論サーバー プラットフォーム、TensorFlow 用の TF-serving プラットフォーム、そして PyTorch 用の TorchServe プラットフォームを展開したくはありませんでした。フレームワークに依存しない Triton の設計と、TensorFlow、PyTorch、ONNX などの複数のバックエンドをサポートする機能は、非常に魅力的でした。これにより、単一の推論実行プラットフォームを使用してエンドツーエンドのパイプラインを提供できるようになり、推論実行コストと、本番モデルを更新するために必要な開発者の作業日数を削減することができました。」
NVIDIA Triton 上での Screenshop サービスの立ち上げが成功した後、Ma 氏とそのチームは、NVIDIA TensorRT に目を向け、システムのパフォーマンスをさらに高めることを目指しました。Screenshop チームは、コンパイル プロセス中に NVIDIA TensorRT のデフォルト設定を適用したことで、スループットが直ちに 3 倍に増加し、コストを 66% 削減できると推定されました。
Wealthsimple: AI による金融の自由化
カナダの投資プラットフォームである Wealthsimple は、300 億カナダドルを超える資産を管理しています。同社は、NVIDIA の AI 推論プラットフォームにより、機械学習へのアプローチを見直しました。インフラを標準化することで、Wealthsimple はモデルの提供時間を数か月から 15 分未満に短縮し、ダウンタイムをなくすとともに、機械学習をサービスとして提供するチームの能力を強化することができました。
NVIDIA Triton を導入し、そのモデルを AWS で実行することで、Wealthsimple は 99.999% のアップタイムを達成し、年間 1 億 4,500 万件以上の取引についてシームレスな予測を行えるようになりました。この変革は、堅牢な AI インフラが金融サービス業界に革命をもたらすこと浮き彫りにしています。
「NVIDIA の AI 推論プラットフォームは当社の ML (機械学習) のサクセス ストーリーにおいて重要な役割を果たしており、モデルの展開に革命をもたらし、ダウンタイムを削減し、比類のないサービスをお客様に提供することができました」と、Wealthsimple のシニア ソフトウェア開発マネージャーである Mandy Gu 氏は述べています。
Let’s Enhance: クリエイティブ ワークフローの改善
AI による画像生成は、クリエイティブ ワークフローを変革しました。またパーソナライズされたコンテンツやマーケティング用ビジュアルの独創的な背景の作成といった、企業での使用事例にも応用できます。拡散モデルはクリエイティブ ワークフローを支援する強力なツールですが、モデルの計算コストが高くなる場合があります。
AI スタートアップのパイオニアである Let’s Enhance は、本番環境で Stable Diffusion XL モデルを使用してワークフローを最適化するために、NVIDIA AI 推論プラットフォームを選択しました。

Let’s Enhance の最新商品である AI Photoshoot は、SDXL モデルを使用して、単純な商品写真を、e コマース Web サイトやマーケティング キャンペーン用の美しいビジュアル資産に変換します。
NVIDIA Triton の各種フレームワークおよびバックエンドに対する強力なサポートと、動的バッチング機能セットを組み合わせることで、Let’s Enhance はエンジニアリング チームの関与を最小限に抑えつつ、SDXL モデルを既存の AI パイプラインにシームレスに統合することができました。これにより、エンジニアリング チームが研究開発用の時間を確保することが可能になりました。
OCI: クラウドベースのビジョン AI を高速化
Oracle Cloud Infrastructure (OCI) は、NVIDIA Triton を統合することでビジョン AI サービスの処理能力を強化し、予測スループットを最大 76% 向上させ、遅延を 51% 削減しました。これらの最適化により、公共交通での通行料請求の自動化やグローバル企業の請求書認識の合理化などのアプリケーションで顧客体験が改善されました。
Triton のハードウェアに依存しない機能により、OCI は AI サービス ポートフォリオを拡大し、世界中のデータセンターに堅牢で効率的なソリューションを提供しています。
「当社の AI プラットフォームは、Triton に対応することで、お客様にメリットをもたらしています」と、OCI のデータ サイエンス サービス部門で商品管理ディレクターを務める Tzvi Keisar 氏は述べています。同部門では、Oracle の社内外のユーザーを対象に機械学習を扱っています。
Microsoft: リアルタイムのコンテキスト化されたインテリジェンスと検索効率
Azure は、NVIDIA AI を搭載し最適化された仮想マシンを非常に幅広く提供しています。これらの仮想マシンには、NVIDIA Blackwell や NVIDIA Hopper システムを含む、複数の世代の NVIDIA GPU が含まれています。
このエンジニアリング コラボレーションの豊かな歴史を基に、NVIDIA GPU と NVIDIA Triton は、Microsoft 365 の Copilot における AI 推論の高速化を支援しています。Windows PC の専用の物理キーボード キーとして利用可能な Microsoft 365 Copilot は、LLM のパワーと独自の企業データを組み合わせ、リアルタイムのコンテキスト化されたインテリジェンスを提供することで、ユーザーの創造性、生産性、スキルを向上させます。
Microsoft Bing も、レイテンシ、コスト、速度などの課題に対処するために、NVIDIA 推論ソリューションを利用しています。NVIDIA TensorRT-LLM テクノロジを統合することで、Microsoft は Deep Search 機能の推論パフォーマンスを大幅に向上させました。これが Web 検索結果の最適化を可能にしています。
Microsoft によるDeep Search の解説
Microsoft Bing Visual Search は、世界中の人々が写真をクエリとして使用し、コンテンツを検索できるようにします。この機能の中核となるのが、Microsoft の TuringMM 視覚埋め込みモデルで、これが画像とテキストを共有の高次元領域にマッピングします。Web 上の数十億もの画像を処理するため、パフォーマンスが非常に重要です。
Microsoft Bing は、NVIDIA TensorRT のほか、CV-CUDA や nvImageCodec を含む NVIDIA のアクセラレーション ライブラリを使用して、TuringMM パイプラインを最適化しました。これらの取り組みにより、5.13 倍の高速化と大幅な TCO 削減を実現できました。
ハードウェアのイノベーション: AI 推論の潜在能力を最大限に引き出す
AI 推論のワークロード効率をどうすれば高められるかは、ハードウェアとソフトウェアの両面で革新的な技術が求められる多面的な課題です。
NVIDIA GPU は、高い効率性とパフォーマンスを AI モデルに提供する AI 実現の最前線に立っています。また、NVIDIA GPU はエネルギー効率にも優れており、NVIDIA Blackwell アーキテクチャ上の NVIDIA のアクセラレーテッド コンピューティングは、兆単位のパラメータを持つ AI モデルの推論において、過去 10 年の間でトークン生成あたりのエネルギー使用量を 10 万分の 1 にまで削減しました。
NVIDIA NVLink-C2C を使用して NVIDIA Grace CPU と Hopper GPU アーキテクチャを組み合わせた NVIDIA Grace Hopper Superchip は、さまざまな業界で大幅な推論パフォーマンスの向上を実現しています。
Meta Andromeda の業界をリードする機械学習: 広告主の価値を解き放つ
Meta Andromeda は、効率的かつ高性能なパーソナライズされた広告検索にスーパーチップを使用しています。Facebook と Instagram では、計算の複雑性と並列性を高めたディープニューラルネットワークを作成することにより、特定のセグメントで広告品質を 8%、リコールを 6% 向上させることができました。
最適化された検索モデルと低レイテンシ、高スループット、そしてメモリ I/O を意識した GPU オペレーターにより、Andromeda は、従来の CPU ベースのコンポーネントと比べ、特徴抽出速度が 100 倍向上しています。こうした検索段階での AI の統合により、Meta は広告検索業界をリードしてきました。またスケーラビリティや遅延といった課題に対処することで、ユーザー体験の改善だけでなく、広告費に対する利益率の向上も実現しています。
最先端の AI モデルがさらに大規模化するにつれ、各トークンを生成するために必要な計算量も増加します。最先端の LLM をリアルタイムで実行するには、複数の GPU を協調動作させる必要があります。NVIDIA Collective Communication Library (NCCL) などのツールを使用することで、マルチ GPU システムは最小限の通信時間で GPU 間の大量のデータ交換を迅速に行うことができます。
AI 推論の今後のイノベーション
AI 推論は、パフォーマンスとコストの両面で未来にかけて大きな進歩を遂げるでしょう。
NVIDIA ソフトウェア、新しいテクノロジ、そして高度なハードウェアの組み合わせにより、データセンターはますます複雑化と多様化が進むワークロードを処理できるようになります。AI 推論は、より正確な予測、迅速な意思決定、そして優れたユーザー体験を実現することで、ヘルスケアや金融などの業界での進歩を推進し続けるでしょう。
これらのトレンドが今後も進化する中にあって、企業は時代に遅れずついていき、最新の推論最適化を導入することで、投資効果を最大限に高め、AI 時代における競争力を維持することが求められます。
NVIDIA が画期的な推論パフォーマンス結果をどのように提供しているか、さらに詳しく知りたい方は、最新の AI 推論パフォーマンスの情報をご覧ください。