
ムーアの法則の終焉により、コンピューティング パフォーマンスの向上に対する飽くなき要求を満たすための従来のアプローチでは、コストと電力の不均衡な増加が必要になります。
同時に、気候変動の影響を遅らせるにはより効率的なデータセンターが必要になりますが、そこではすでに毎年 200 テラワット時以上のエネルギーを消費しており、これは世界のエネルギー使用量の約 2% に相当します。
本日発表された、世界で最も効率的なスーパーコンピューターを示す Green500 のリストでは、リストの上位 30 のシステムすべてで既に使用されているアクセラレーテッド コンピューティングのエネルギー効率を実証しています。そのエネルギー効率への影響は驚異的です。
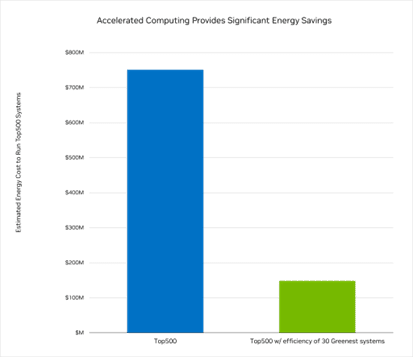
TOP500 のシステムがすべて動作するには、年間 5 テラワット時以上のエネルギー、つまり 7 億 5000 万ドル相当のエネルギーが必要であると、NVIDIAは見積もっています。
しかし、これらのシステムが TOP500 リストの 上位30 の最も環境に優しいシステムと同じくらい効率的であれば、それは 80% 以上削減されてわずか 1 億 5,000 万ドルになり、4 テラワット時のエネルギーを節約できます。
逆に、現在の TOP500 システムと同じ電力量で上位 30 システムの効率を実現すれば、これらのスーパーコンピューターは現在の 5 倍のパフォーマンスを実現することができます。
そして、最新の Green500 システムによって明らかにされた効率の向上は、ほんの始まりにすぎません。NVIDIA は、CPU、GPU、ソフトウェア、およびシステム ポートフォリオ全体で継続的なエネルギーの改善を実現するために奔走しています。
Hopperの Green500 デビュー
NVIDIA のテクノロジは、最新の Green500 リストの上位 30 のシステムのうち 23 に既に搭載されています。
例えば、ニューヨークのフラットアイアン研究所は、NVIDIA Hopper H100 GPU を搭載し、Lenovo によって構築された空冷式の ThinkSystem を使用したことにより、最も効率的なスーパーコンピューターとして Green500 リストのトップになりました。
Green500 によると、Henri と名付けられたこのスーパーコンピューターは、1 ワットあたり 650 億回の倍精度浮動小数点演算を行い、計算天体物理学、生物学、数学、神経科学、量子物理学の問題に取り組むために使用されます。
NVIDIA Hopper GPU アーキテクチャに基づく NVIDIA H100 Tensor コア GPU は、前世代の A100 GPU と比較して、最大 6 倍の AI パフォーマンスと最大 3 倍の HPC パフォーマンスを備え、驚異的な効率で動作するように設計されています。その第 2 世代である Multi-Instance GPU テクノロジは、GPU をより小さなコンピューティング ユニットに分割できるため、データセンターのユーザーが利用できる GPU クライアントの数が劇的に増加します。
今年の SC22 カンファレンスの展示フロアには、NVIDIA の最新テクノロジを搭載したASUS、Atos、Dell Technologies、GIGABYTE、Hewlett Packard Enterprise、Inspur、Lenovo、QCT、Supermicro の新しいシステムが目白押しです。
TOP500 リストに初めて登場したシステムの中で最速のコンピューターである Leonardo は、Cineca 非営利コンソーシアムによってホストおよび管理されています。このコンピューターは、約 14,000 の NVIDIA A100 GPU を搭載し、4 位を獲得しましたが、12 番目にエネルギー効率の高いシステムでもありました。
全体では、NVIDIA のテクノロジは、新しいシステムの 90% を含む、TOP500 リストの 361 のシステムを支えています (図参照)。
 最新の TOP500 リストで、NVIDIA のテクノロジは、これまでで最も多くのシステムを支えています。
最新の TOP500 リストで、NVIDIA のテクノロジは、これまでで最も多くのシステムを支えています。次世代の高速データセンター
NVIDIA はさらに、高速化されたデータセンターにさらに優れたエネルギー効率とパフォーマンスを提供する新しいコンピューティング アーキテクチャも開発しています。
今年初めに発表された Grace CPU と Grace Hopper Superchipは、NVIDIA アクセラレーテッド コンピューティング プラットフォームのエネルギー効率を大幅に向上させます。Grace CPU Superchip は、Grace CPU と低電力 LPDDR5X メモリの驚異的な効率により、従来の CPU に比べワットあたり最大 2 倍のパフォーマンスを提供します。
例えば、1 メガワットの HPC データ センターで、電力の 20% が CPU 部分に割り当てられ、80% がアクセラレーター部分に割り当てられ、Grace と Grace Hopper を使用していると仮定すると、データセンターは、同様に電力を分配した x86 ベースのデータセンターと比較して、同じ電力量で 1.8 倍多くのジョブを実行できます。
さらなる効率向上を推進する DPU
シミュレーションの使用の増加がスーパーコンピューティング サービスの需要を加速させているのと同じように、Grace および Grace Hopper とともに、NVIDIA ネットワーキング テクノロジは、クラウドネイティブのスーパーコンピューティングを加速させています。
NVIDIA の BlueField-3 DPU をベースとする NVIDIA Quantum-2 InfiniBand プラットフォームは、クラウド コンピューティング プロバイダーやスーパーコンピューティング センターが必要とする究極のパフォーマンス、幅広いアクセス性、強力なセキュリティを提供します。
最近のホワイトペーパーで説明されているこの取り組みは、DPU を使用してネットワーク、セキュリティ、ストレージ、またはその他のインフラストラクチャ機能とコントロールプレーン アプリケーションをオフロードおよび高速化し、サーバーの消費電力を最大 30% 削減する方法を実証しました。
節電量はサーバーの負荷が増加するにつれて増加し、1万台のサーバーを備えた大規模なデータセンターの場合、サーバーの 3 年間の耐用年数で 500 万ドルの電力コストを簡単に節約でき、さらに冷却、電力供給、ラック スペース、およびサーバー資本コストでの節約が可能となります。
ネットワーク、セキュリティ、およびストレージ ジョブ向けの DPU によるアクセラレーテッド コンピューティングは、データセンターの電力効率を高めるための次の大きなステップの 1 つです。
パフォーマンスと効率の両方を提供
このようなブレイクスルーは、科学的手法がデータ分析、AI、物理ベースのシミュレーションを駆使したアプローチに急速に変化し、より効率的なコンピューターが次世代の科学的ブレイクスルーの鍵となっていることを意味しています。
NVIDIA は、この新しいアプローチに最適化された多分野にまたがるハイ パフォーマンス コンピューティング プラットフォームを研究者に提供し、パフォーマンスと効率の両方を提供できるようにすることで、科学者に人類全体へ利益をもたらす重要な発見を行う手段を提供します。