多くのユーザーは、プライバシーの保護と制御を向上し、またサブスクリプションなしで大規模言語モデル (LLM) をローカルで実行したいと考えています。これは、最近までは出力品質の低下を招いていました。OpenAI の gpt-oss や Alibaba の Qwen 3 など、新たにリリースされたオープンウェイト モデルは、PC 上で直接実行することが可能で、特にローカル環境のエージェント型 AI に、有用かつ高品質な出力をもたらします。
これにより、学生、趣味で使用するユーザー、開発者がローカル環境で生成 AI アプリケーションを探索する新たな機会が生まれます。NVIDIA RTX PC は、これらの体験を高速化し、ユーザーに高速で応答性に優れた AI を提供します。
RTX PC 向けに最適化されたローカル LLM の始め方
NVIDIA は、RTX PC 向けに主要な LLM アプリケーションを最適化し、RTX GPU の Tensor コアのパフォーマンスを最大限に引き出すための取り組みを行ってきました。
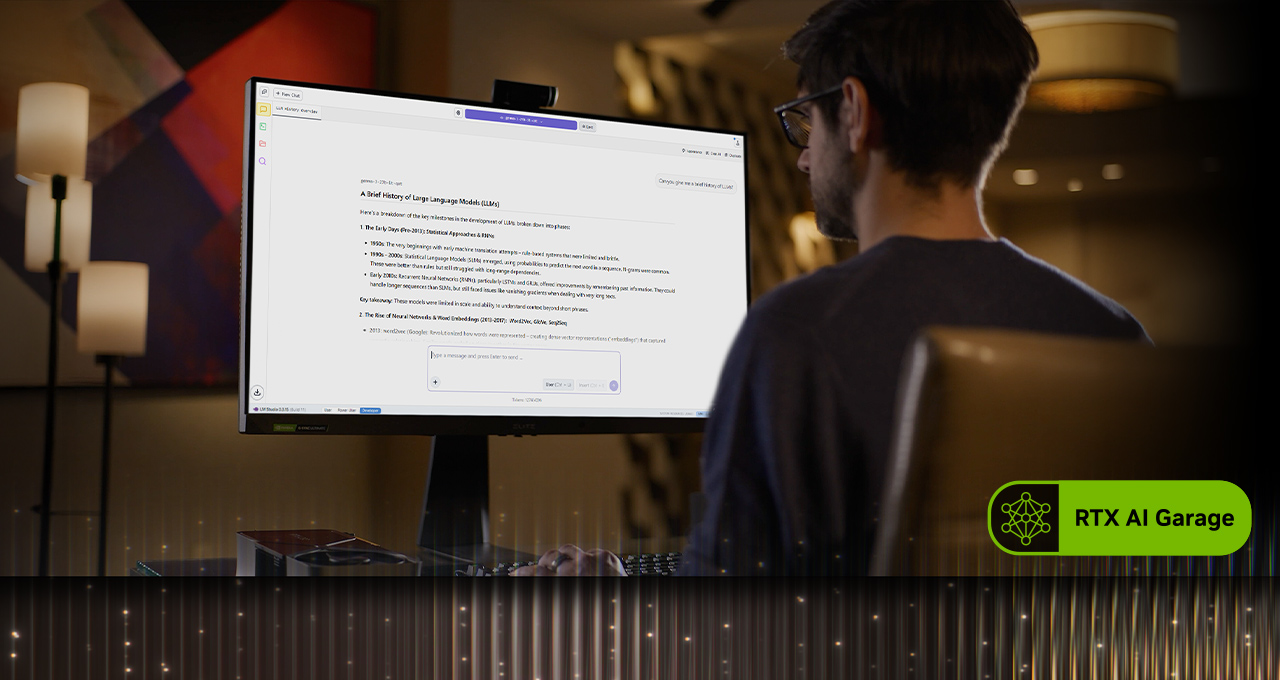
PC で AI を始める最も簡単な方法の 1 つは、LLM の実行と対話に適したシンプルなインターフェースを提供するオープンソース ツールである Ollama を使用することです。プロンプトに PDF をドラッグアンドドロップする機能、対話型のチャット、テキストや画像を含むマルチモーダルな理解ワークフローをサポートしています。
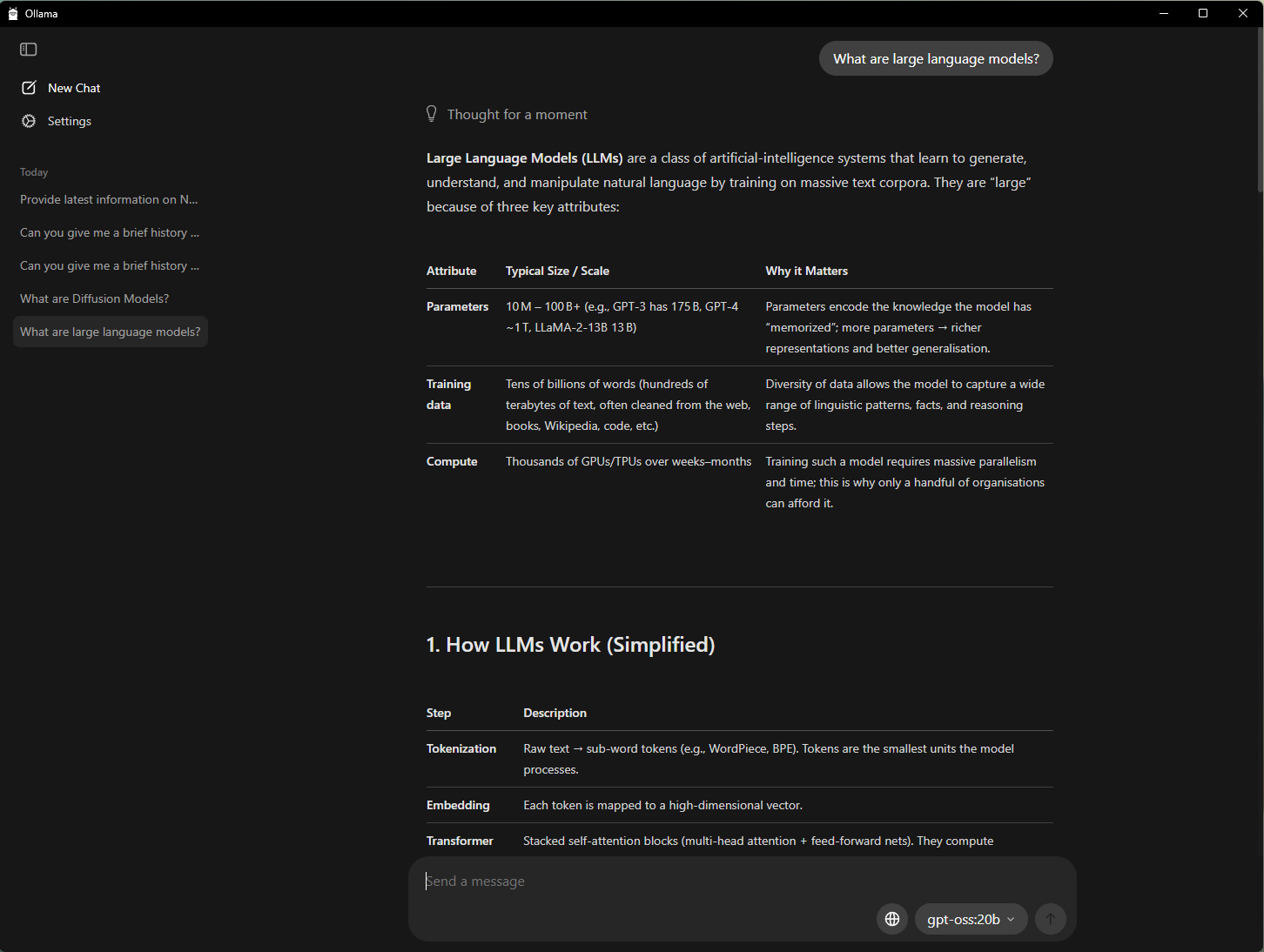
NVIDIA は Ollama と協業し、そのパフォーマンスとユーザー体験を向上させました。最新の開発内容は、以下の通りです。
- OpenAI の gpt-oss-20B モデルと Google の Gemma 3 モデルで GeForce RTX GPU のパフォーマンスが向上
- RTX AI PC での超効率的な RAG のための、新しい Gemma 3 270M と EmbeddingGemma モデルへのサポート
- メモリ使用率の最大化および正確な報告を可能にするモデル スケジューリング システムの改善
- 安定性とマルチ GPU の改善
Ollama は、他のアプリケーションと連携して使用できる開発者フレームワークです。たとえば AnythingLLM は任意の LLM を活用してユーザーが自分の AI アシスタントを構築できるオープンソース アプリですが、このアプリは Ollama 上で実行でき、その高速化の恩恵がすべて得られます。
愛好家は、人気の llama.cpp フレームワークを基盤としたアプリである LM Studio を使用してローカル LLM の利用を始めることもできます。このアプリは、モデルをローカルで実行するためのユーザーフレンドリーなインターフェースを提供します。ユーザーは、さまざまな LLM を読み込み、リアルタイムでチャットできるほか、カスタム プロジェクトに統合するためのローカル アプリケーション プログラミング インターフェイス (API) エンドポイントとして提供できます。
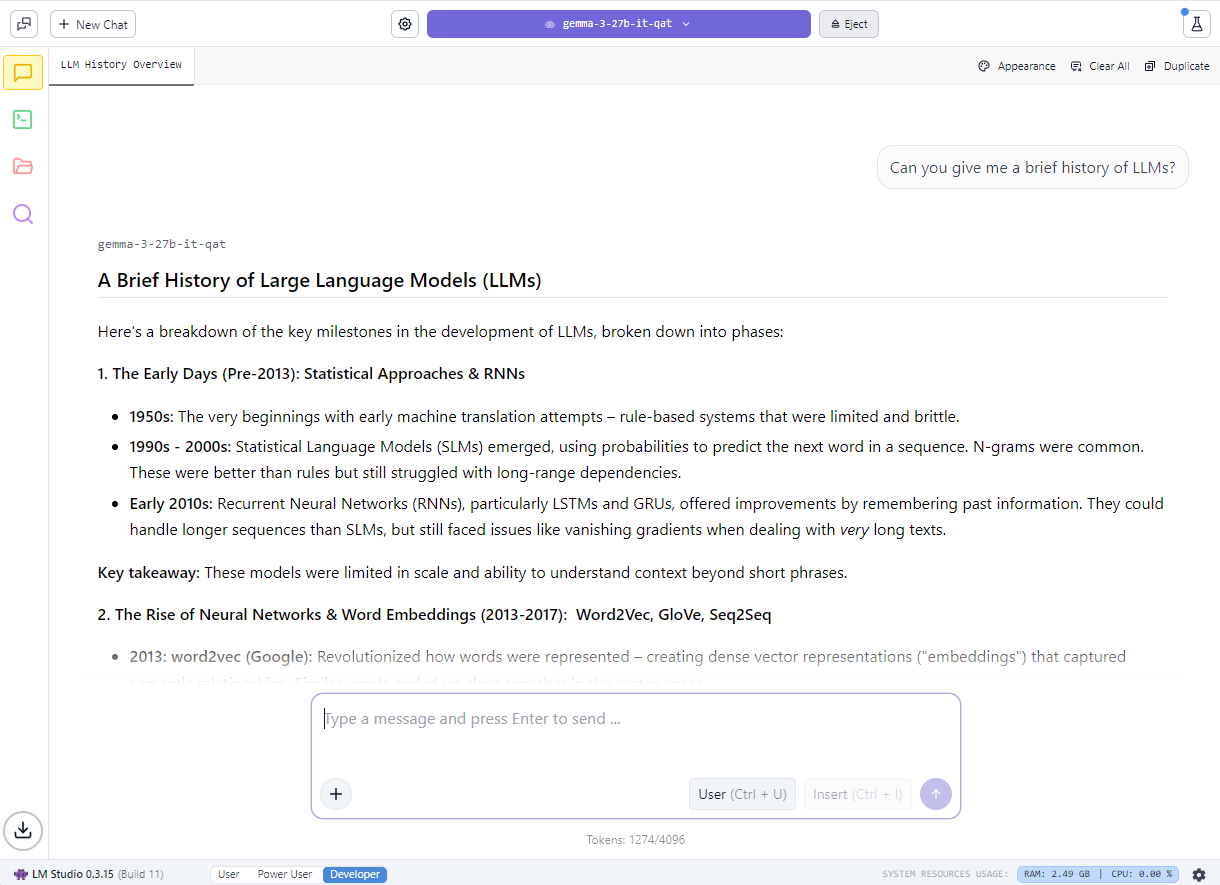
NVIDIA は llama.cpp と協力して、NVIDIA RTX GPU 上でのパフォーマンスを最適化しました。 最新のアップデート内容は、以下の通りです。
- 革新的な hybrid-mamba アーキテクチャをベースとする最新の NVIDIA Nemotron Nano v2 9B モデルのサポート
- Flash Attention がデフォルトで有効に (Flash Attention 無効時と比較して、パフォーマンスが最大 20% 向上)
- RMS Norm と fast-div ベースの Modulo に対する CUDA カーネルの最適化により、人気のモデルで最大 9% のパフォーマンス向上を実現
- セマンティック バージョニングにより、開発者が今後のリリースを容易に採用することが可能に
RTX 上の gpt-oss についての詳細と、NVIDIA が LM Studio と協力して RTX PC での LLM のパフォーマンスを高速化した方法についてご覧ください。
AnythingLLM を活用した AI 搭載 Study Buddy の構築
LLM をローカルで実行すると、プライバシー保護の強化とパフォーマンス向上を体感できるほか、読み込めるファイル数や利用可能な期間に関する制限がなくなり、文脈を認識する AI との対話をより長時間実行できます。これにより、対話型 AI および生成 AI を活用したアシスタントを構築する際の柔軟性が大幅に向上します。
学生にとって、大量のスライド、ノート、実習資料、過去問を管理する負担はかなりのものです。ローカル LLM を利用すれば、個々の学習ニーズに適応できるパーソナルな家庭教師システムの構築が可能になります。
以下のデモは、学生がローカル LLM を使用して生成 AI を活用したアシスタントを構築する方法を紹介しています。
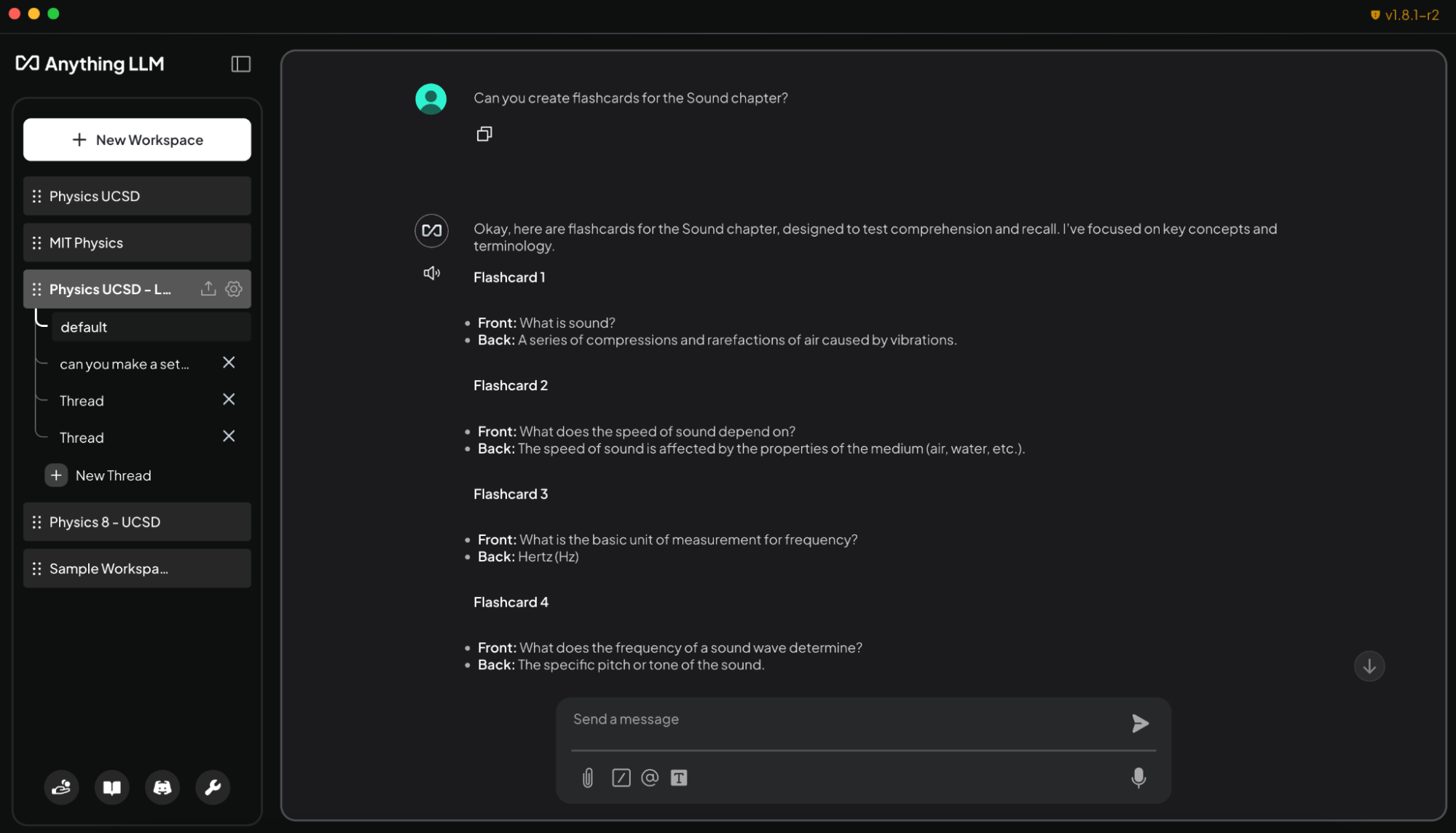
これは、ドキュメントのアップロード、カスタムのナレッジベース、対話型インターフェースをサポートする AnythingLLM で簡単に行えます。これにより、AnythingLLM は調査、プロジェクト、日常のタスクを支援するカスタマイズ可能な AI を作成したいユーザーにとって、柔軟性の高いツールとなります。また、RTX による高速化により、ユーザーはさらに高速な応答を体験できます。
RTX PC 上の AnythingLLM にシラバス、課題、教科書を読み込ませることで、学生は適応性のあるインタラクティブな学習パートナーを得ることができます。このエージェントに、平易なテキストや音声で以下のようなタスクを依頼できます。
- 講義スライドからフラッシュカードを生成: 『講義スライドの「音響」の章からフラッシュカードを作成して。表に重要な用語を、裏に定義を書いてください』
- 教材に関連した文脈で質問: 『物理 8 のノートを使って、運動量保存則を説明して』
- 試験対策用の小テストの作成と採点: 『化学の教科書の 5 ~ 6 章を基にして 10 問の選択問題を作成し、私の回答を採点して』
- 難問を段階的に解説: 『コーディングの宿題の問題 4 の解決方法を、段階的に解く方法を教えて』
教室外の利用としては、趣味で学ぶユーザーや専門家が新しい研究分野の資格取得準備やその他の目的で AnythingLLM を利用できます。また、RTX GPU 上でローカルに実行することで、サブスクリプション費用や使用制限なしに、高速でプライベートな応答が可能になります。
Project G-Assist がノート PC 設定の制御機能を追加
Project G-Assist は、簡単な音声またはテキスト コマンドを通じて、メニューを深く掘り下げることなくゲーミング PC のチューニング、制御、最適化を支援する実験的な AI アシスタントです。新しい G-Assist アップデートがNVIDIA アプリのホーム ページを通じて展開されます。
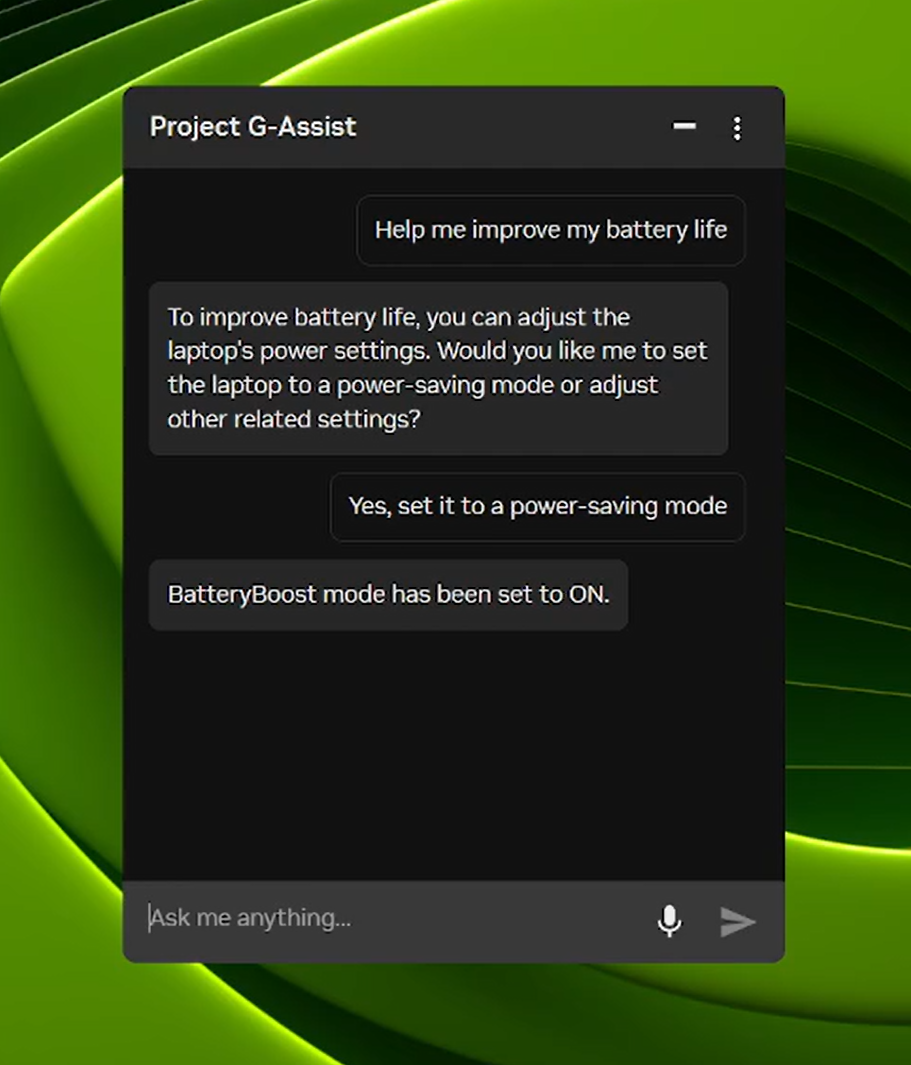
8 月にリリースされた、新たな高効率な AI モデルと多くの RTX GPU のサポートを基盤に、新しい G-Assist アップデートにはノート PC の設定を調整するためのコマンドが追加されました。
- ノート PC に最適化されたアプリ プロファイル: ノート PC がバッテリー駆動状態のとき、ゲームやアプリの効率性、画質、バランスを自動的に調整します。
- BatteryBoost の制御: BatteryBoost を有効または調整して、滑らかなフレームレートを維持しながらバッテリー駆動時間を向上させます。
- WhisperMode の制御: 必要に応じてファンの動作音を最大 50% 低減し、不要な場合にはフル パフォーマンスに戻します。
Project G-Assist は拡張性も備えています。G-Assist Plug-In Builder を使用すると、ユーザーは簡単に作成できるプラグインで新しいコマンドを追加したり、外部ツールと連携したりすることで、G-Assist の機能を作成およびカスタマイズできます。また、G-Assist PlugIn Hub により、G-Assist の機能を拡張するプラグインを簡単に見つけてインストールできます。
NVIDIA の G-Assist GitHub リポジトリにて、サンプル プラグイン、ステップバイステップの手順、カスタム機能構築のためのドキュメントなど、始める方法に関する資料を確認してください。
再掲 — RTX AI PC の最新情報
🎉Ollama が RTX で大幅なパフォーマンス向上
最新のアップデートには、OpenAI の gpt-oss-20B のパフォーマンス最適化、Gemma 3 モデルの高速化、メモリ問題を軽減し、マルチ GPU の効率が向上させるスマートなモデル スケジューリングが含まれています。
🚀Llama.cpp と GGML が RTX に最適化
最新のアップデートでは、NVIDIA Nemotron Nano v2 9B モデルのサポート、Flash Attention のデフォルト有効化、CUDA カーネルの最適化など、RTX GPU でより高速かつ効率的な推論を実現します。
⚡Project G-Assist アップデートの公開
NVIDIA アプリから G-Assist v0.1.18 アップデートをダウンロードできます。このアップデートはノート PC ユーザー向けの新しいコマンドと、回答品質の向上が特徴です。
⚙️Windows ML with NVIDIA TensorRT for RTX が一般提供開始
Microsoft は Windows ML with NVIDIA TensorRT for RTX acceleration をリリースしました。これにより、Windows 11 PC 上で最大 50% 高速化された推論、効率化された展開、LLM、拡散モデル、その他のモデル タイプのサポートが提供されます。
🌐 NVIDIA Nemotron が AI 開発を強化
NVIDIA Nemotron のオープン モデル、データセット、手法は、汎用的な推論から業界に特化したアプリケーションまで、AI のイノベーションを加速しています。
NVIDIA AI PC については、Facebook、Instagram、TikTok、X で確認できます。また、RTX AI PC ニュースレターを購読すると、最新情報を確実に受け取ることができます。
LinkedIn と X で NVIDIA Workstation をフォローしてください。
ソフトウェア製品情報に関するお知らせをご覧ください。